俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下:
- 数据库的概念、逻辑、数据模型概念
- 应用程序的分层体系结构发展
- MVC设计模式与四层结构的对应关系
- 持久层的设计目标
- 数据映射器架构模式
- JDBC的缺点
- Hibernate简介
- 迅速使用Hibernate开发的例子
- Hibernate的核心类和接口,以及他们的关系
- POJO和JavaBean的比较
数据库精华知识点总结(1)—数据库的三层模式和二级映像,E-R(实体联系图)图,关系模型
简单来说,就是在软件开发领域,可以用模型表示真实世界的实体。针对数据库就分为:- 概念模型(分析阶段):一般不描述实体的行为,技术人员和非技术人员都能看懂。
- 逻辑模型(设计阶段)
- 物理模型/数据模型(实现阶段)
举例电脑;

在需求分析阶段,我们要考虑电脑的概念模型:品牌,颜色,价格……在设计阶段,需要构建逻辑模型,比如建立实体类(包含属性和方法),在物理模型阶段,我们要把实体保存到数据库中,此时需要建立表……把数据插入到表,实体的属性对应表的字段。他们的关系如下:
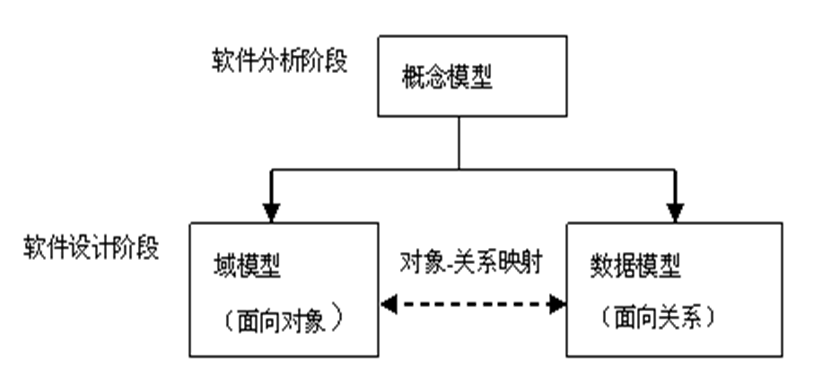
很自然的,研发人员需要把数据模型(面向关系)和域模型(面向对象)联系起来,因为目前主流的数据库都是关系型数据库,比如常见的MySQL,Oracle,SQLServer……而我们的程序(目前大多数)都是面向对象的模型。
PS:关系型数据库以行和列的形式存储数据,以便于用户理解。这一系列的行和列被称为表,一组表组成了数据库。表与表之间的数据记录有关系。关系模型本质就是一张二维表。
- 表-------实体
- 字段-------属性
- 记录--------实例
- 视图
- 索引
- 主键,主键满足三点特征:1.唯一性,2.非空,3.不可修改
- 还有一种主键叫代理主键:不具有业务逻辑含义。比如 MySQL 的 auto_increament, uniqueidentify
- 触发器/存储过程
下面简单看下实体和实体之间的关联关系:
- One to One(一对一),比如一个公民对应一个身份证号码
- One to Many(一对多),比如一个公民有多张银行卡账号
- Many to Many(多对多),比如一个老师对应多个学生,同时一个学生对应多个老师
简单复习表的完整性
- 实体的完整性 (表记录的唯一性,通过主键解决)
- 参照完整性 (主子表数据的一致性)
- 域的完整性 (类型与约束检查)
- 用户自定义的完整性 (用户自定义的约束),例如:考试成绩0-100是合理的,需要用户定义
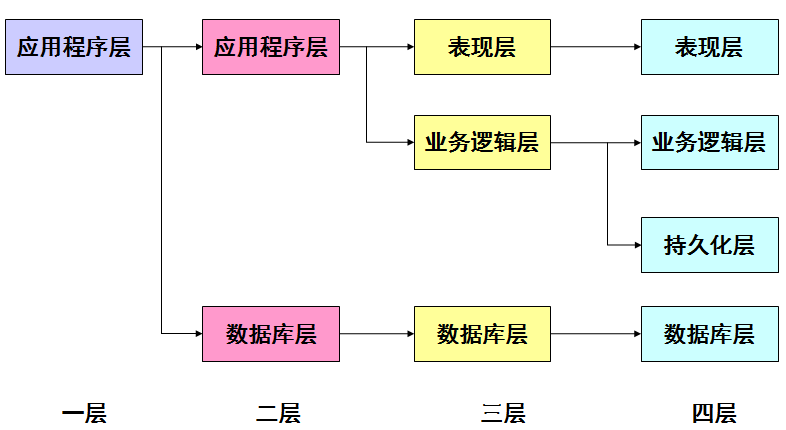
应用程序的分层体系结构发展
- 伸缩性:伸缩性指应用程序是否能支持更多的用户
- 可维护性:可维护性指的是当发生需求变化,只需修改软件的某一部分,不会影响其他部分的代码
- 可扩展性:可扩展性指的是在现有系统中增加新功能的难易程度。层数越多,就可以在每个层中提供扩展点,不会打破应用的整体框架
- 可重用性:可重用性指的是程序代码没有冗余,同一个程序能满足多种需求。例如,业务逻辑层可以被多种表述层共享
- 可管理性:可管理性指的是管理系统的难易程度。将应用程序分为多层后,可以将工作分解给不同的开发小组,从而便于管理
下面复习下数据映射器架构模式:
程序中的对象间的关系,和关系型数据库中的表是不同的,数据库的表可以看成是由行与列组成的格,表中的一行可以通过外键和另一个表(甚至同一个表)中的一行关联,而对象的关系非常复杂:一个对象可能包含其他对象,不同的数据结构可能通过不同的方式组织相同的对象……对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。
要把关系数据库里的数据本身和处理业务逻辑的内存对象对应联系起来,可以通过数据映射器把两者关联。数据映射器是分离内存对象和数据库的中间软件层,在保持对象和数据库(以及映射器本身)彼此独立的情况下,在二者之间移动数据的一个映射器层。简单的说,数据映射器就是一个负责将数据映射到对象的类数据,由它来负责对象和关系数据库两者数据的转换,从而有效地在领域模型中隐藏数据库操作并管理数据库转换中不可避免的冲突。
数据映射器架构模式最强大的地方在于消除了领域层和数据库操作之间的耦合。数据映射器在幕后运作,可以应用于各种对象关系映射。而与之带来的是需要创建大量具体的映射器类,不过现在的主流Web开发框架都可以自动生成并维护……比如Hibernate框架,前面提到了对象关系映射,继续总结:
对象-关系映射(Object/Relation Mapping,简称ORM)
是随着面向对象的软件开发方法发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。它的实质就是将关系数据(库)中的业务数据用对象的形式表示出来,并通过面向对象(Object-Oriented)的方式将这些对象组织起来,实现系统业务逻辑的过程。
先看看背景,JavaWeb 开发中,服务器端通常分为表示层、业务层、持久层,这就是所谓的三层架构:
- 1、表示层负责接收用户请求、转发请求、显示数据等;
- 2、业务层负责组织业务逻辑;
- 3、持久层负责持久化业务对象,本质上是封装了对数据的访问细节,为业务逻辑层提供面向对象的API,使业务层可以专注于实现业务逻辑(“持久化” 包括和数据库相关的各种操作,保存、更新、删除、加载、查询);

这三个分层,每一层都有不同的模式,即架构模式,如下图。

MVC设计模式与四层结构的对应关系

- 代码可重用性高,能够完成对象持久化操作
- 如果需要的话,能够支持多种数据库平台
- 具有相对独立性,当持久层发生变化时,不会影响上层实现
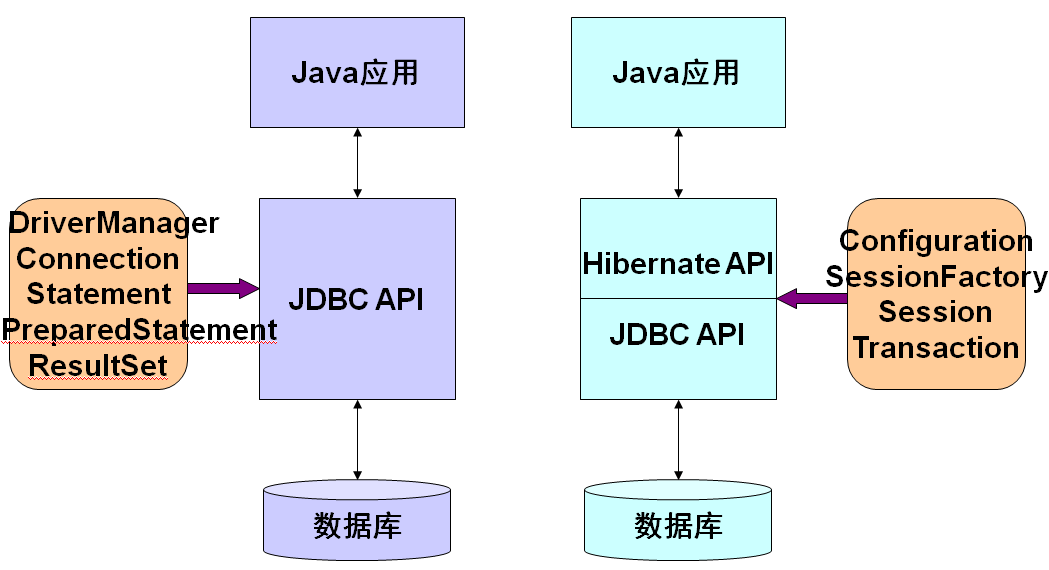
之前我们是直接使用Java的JDBC API进行数据库操作。
JDBC编程的缺点:
- 业务逻辑和关系数据绑定,如果关系数据模型发生变化,例如修改了表的结构,那么必须手工修改程序代码中所有相关的SQL语句,增加了软件维护的难度
- 在程序代码中嵌入面向关系的SQL语句,使开发人员不能完全运用面向对象的思维来编写程序
- 如果程序代码中的SQL语句包含语法错误,在编译时不能检查这种错误,在运行时才能发现这种错误,这增加了调试程序的难度
而持久层的架构模式常用常见的就是数据映射器架构模式,Hibernate就是数据映射器架构模式的一种实现,Hibernate本意(狗熊)冬眠,它是一个持久层的开源框架,解决了对象-关系映射的难题,比较庞大,也很智能(相对Ibatis来说,这个iBatis很简单,后续再顺带总结)。
- Hibernate是对JDBC API的封装,是JDBC轻量级封装框架,增强了代码的重用性,简化了代码,提高了编程效率
- 使Java程序员可以方便的运用面向对象的编程思想来操纵关系型数据库。
- 因为Hibernate是对JDBC的轻量级封装,必要时Java程序员还可以轻松绕过Hibernate直接访问JDBC API。
- Hibernate不仅可以应用在独立的java程序中,还可以应用在java web项目中,可以和多种web服务器集成,并支持多种数据库平台
看图,Hibernate作为一个数据映射器架构模式的实现,位于Web开发三层架构的第三层——数据持久层。

通过Hibernate(数据持久层)把业务逻辑里的代码(数据)持久化到数据源里(关系数据库)中,故Hibernate支持非常非常多的数据库系统。下面小试牛刀,写一个Hibernate的应用demo。简单创建一个Java应用程序。需要引用的jar包:核心jar包是:hibernate3.jar,所有的如下:

还有MySQL数据库连接的jar包。
编写Hibernate应用的一般步骤无外乎以下4步:
- 创建Hibernate的配置文件:Hibernate需要从配置文件中读取数据库配置信息,一般位于项目根路径。Hibernate配置文件两种方式。
- hibernate.properties (键=值方式)
- hibernate.cfg.xml(必须在src的根目录下)
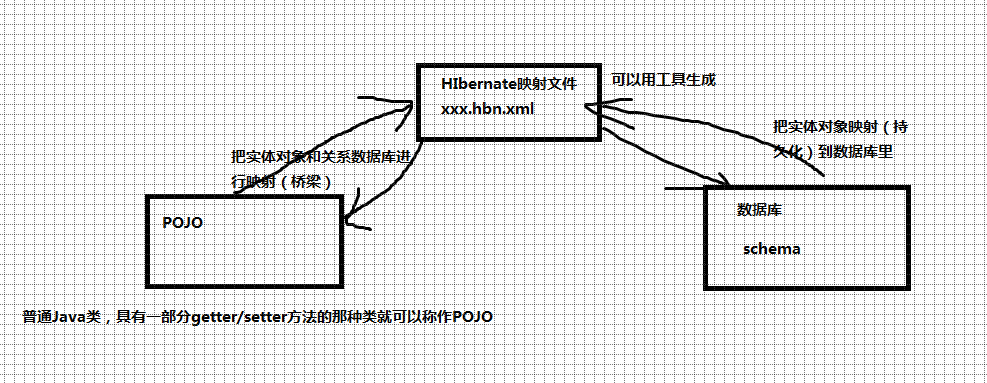
- 创建持久化类Xxx.java:指其实例需要被Hibernate持久化到数据库中的类,即实体类
- 创建持久化类的对象-关系映射文件:xxx.hbn.xml,必须放在实体类对应的包内
- 通过Hibernate API编写访问数据库的代码,完成对象的持久化
so easy!
针对配置文件,我们可以去jar包的示例去找,看官方的例子,或者随便网上一搜一堆……没有必要去记!!!关键是思路和原理的掌握。
Hibernate配置文件是典型的 XML 文件,我们只保留 session 工厂部分,里面的内容不要。


<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory name="foo"> </session-factory> </hibernate-configuration>
创建一个数据库bbs,一张表user

持久化类和我们的数据库的表是有对应关系的,故前提是,得有一张数据库的表User二维表(至少1张)和对应的实体类User类,我在vo包(数据对象value Object:页面与页面之间的传递值时保存值的对象)建立:
1 package dashuai.vo; 2 3 /** 4 * User 实体类 5 * 6 * @author Wang Yishuai. 7 * @date 2016/2/2 0002. 8 * @Copyright(c) 2016 Wang Yishuai,USTC,SSE. 9 */ 10 public class User { 11 private int userId; 12 13 private String username; 14 15 private String password; 16 17 public String getPassword() { 18 return password; 19 } 20 21 public void setPassword(String password) { 22 this.password = password; 23 } 24 25 public int getUserId() { 26 return userId; 27 } 28 29 public void setUserId(int userId) { 30 this.userId = userId; 31 } 32 33 public String getUsername() { 34 return username; 35 } 36 37 public void setUsername(String username) { 38 this.username = username; 39 } 40 }
同时它也是一个POJO类——POJO全称是Plain Ordinary Java Object / Plain Old Java Object,中文可以翻译成:普通Java类,具有一部分getter/setter方法的那种类就可以称作POJO类。
创建对象-关系映射的XML文件,必须放在实体类对应的包(我的是vo)下,名字严格对应为:类名.hbm.xml
<?xml version="1.0"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!-- class 里面的属性必须和对应的类名,表名保持一致,实现映射--> <class name="dashuai.vo.User" table="user"> <!-- id代表数据库表的主键, name="userId",对应数据库表里的字段column="userId"--> <id name="userId" column="userId" type="int"/> <!-- 数据库里其他普通字段和实体属性的映射,属性的类型需要小写--> <property name="username" column="username" type="string"/> <property name="password" column="password" type="string"/> </class> </hibernate-mapping>
<class>元素用于指定类和表之间的映射,name属性设定类名(包含路径),table属性设定表名,默认以类名作表名

- name – 对应类的属性名称
- type – 指定属性的类型
- column – 指定表字段的名称
- not-null –指定属性是否允许为空
顺便把Hibernate的主配置文件hibernate.cfg.xml(需放在src根目录下)补充好,千万别忘了把之前对象关系映射配置文件引入到主配置文件内,mapping……
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <!-- 起一个名字 ,我这里叫 MySQL --> <session-factory name="MySQL"> <!-- 关于数据库连接的配置属性--> <!-- 连接MySQL数据库的驱动配置--> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <!-- 配置MySQL数据库的连接地址,我的数据库叫bbs,端口一般都是3306 --> <property name="connection.url">jdbc:mysql://localhost:3306/bbs</property> <!-- 配置数据库的用户名和密码--> <property name="connection.username">root</property> <property name="connection.password">123</property> <!-- 配置数据库的方言,设置MySQL5.0版本的方言,MySQL5Dialect类的名称要写完整 --> <property name="dialect">org.hibernate.dialect.MySQL5Dialect</property> <!-- 方便调试,show_sql = true 设置显示自动生成的SQL脚本--> <property name="show_sql">true</property> <!-- 关键:把对象关系映射配置文件加到hibernate 主配置 文件,否则程序找不到 --> <mapping resource="dashuai/vo/User.hbm.xml"/> </session-factory> </hibernate-configuration>
创建dao包,并通过Hibernate API 编写访问数据库的代码,这里必须要知道hibernate的一些核心的类和接口。如下:
Hibernate 框架的核心类和接口
- SessionFactory:是一个核心的接口,相当于hibernate和数据库连接的一个大管家,它缓存了Hibernate的配置信息和映射的元数据信息,属于重量级的,故实例化它的实现类只需要实例化一次,且不能轻易的关闭,如果关闭了,和数据库就断开了,此外,连接不同的数据库,需要建立不同的SessionFactory对象,而实例化该类,需要用到一个该接口的实现类——配置类Configuration,用Configuration的对象实例化之后,才能创建Session的实例。
- SessionFactory的创建,configuartion.buildSessionFactory()。
- SessionFactory是线程安全的,可以安全的让多个线程进行共享,一般整个应用只有唯一的一个SessionFactory实例。
- SessionFactory缓存
- 内置缓存,存储Hibernate配置信息和映射元数据信息,物理介质是内存
- 外置缓存,是一个可配置的缓存插件,可以存放大量的数据库数据的拷贝,物理介质可以是内存或者是硬盘
- Configuration:是SessionFactory接口的实现类。
- 该实现类两个功能
- 负责管理Hibernate的运行的底层配置信息,包括:数据库的URL、数据库用户名和密码、JDBC驱动,数据库Dialect,数据库连接池等。
- 生成SessionFactory的对象,创建的SessionFactory对象能可以创建session
- 使用的两种方法
-
属性文件(hibernate.properties),调用代码:Configuration cfg = new Configuration();
-
xml文件(hibernate.cfg.xml),调用代码:Configuration cfg = new Configuration().configure();
-
- Session:也是一个接口,继承了SessionFactory,Session是Hibernate持久操作的基础核心,可以简单的理解为之前jdbc里的connection对象。
- Session的创建(依靠SessionFactory,sessionFactory对象来自configuartion.buildSessionFactory();,而configuartion这个实例化对象来自new Configuration().configure();),Session session = sessionFactory.openSession();代表了一个数据库的连接,有了该session连接,就可对数据库进行操作(crud),故也叫session为持久化管理器。而对数据库的操作,我们需要封装到事务当中,也就是Hibernate的Transaction
- Session是一个轻量级对象,是非线程安全的,通常和一个数据库事务绑定。
- Transaction:一个接口,它将应用代码从底层的事务实现中抽象出来,是一个JDBC事务或一个JTA事务,可以在配置文件中指定,默认是JDBC事务。
- 调用代码:Transaction tx = session.beginTransaction();
- 使用Hibernate进行操作时,必须显式的调用Transaction(默认:autoCommit=false)
类图:

再介绍下Query与Criteria接口
Query接口,允许程序员在数据库上执行查询并控制查询如何执行,查询语句使用Hibernate的HQL或本地数据库的SQL,调用代码:Query query = session.createQuery(“from User”);
Criteria接口,是传统SQL的对象化表示,调用代码:Criteria criteria = session.createCriteria(Tuser.class);
结构如图:
代码如下:
1 package dashuai.dao; 2 3 import dashuai.vo.User; 4 import org.hibernate.Session; 5 import org.hibernate.SessionFactory; 6 import org.hibernate.Transaction; 7 import org.hibernate.cfg.Configuration; 8 import org.slf4j.Logger; 9 import org.slf4j.LoggerFactory; 10 11 /** 12 * UserDao 13 * 14 * @author Wang Yishuai. 15 * @date 2016/2/2 0002. 16 * @Copyright(c) 2016 Wang Yishuai,USTC,SSE. 17 */ 18 public class UserDao { 19 /** 20 * 使用 hibernate 连接 MySQL数据库,并操作 21 * @param args String[] 22 */ 23 public static void main(String[] args) { 24 final Logger LOG = LoggerFactory.getLogger(UserDao.class); 25 26 // 通过new一个Configuration实例,然后用该实例去调用configure返回一个配置实例 27 Configuration configuration = new Configuration().configure(); 28 // 通过 配置实例的buildSessionFactory方法 生成一个 sessionFactory 对象 29 // buildSessionFactory方法会默认的去寻找配置文件hibernate.cfg.xml并解析xml文件 30 // 解析完毕生成sessionFactory,负责连接数据库 31 SessionFactory sessionFactory = configuration.buildSessionFactory(); 32 // 通过 sessionFactory 获得一个数据库连接 session,可以操作数据库 33 Session session = sessionFactory.openSession(); 34 // 把操作封装到数据库的事务,则需要开启一个事务 35 Transaction transaction = session.beginTransaction(); 36 37 // 一般把对实体类和数据库的操作,放到try-catch-finally块 38 try { 39 User user = new User(); 40 user.setUserId(22); 41 user.setUsername("dashuai"); 42 user.setPassword("123456"); 43 // 把user对象插入到数据库 44 session.save(user); 45 // 提交操作事务 46 transaction.commit(); 47 LOG.info("transaction.commit(); ok"); 48 } catch (Exception e) { 49 // 提交事务失败,必须要回滚 50 transaction.rollback(); 51 // 打印日志 52 LOG.error("save user error......", e); 53 } finally { 54 // 不能丢这一步,要释放资源 55 if (session != null) { 56 session.close(); 57 LOG.info("session.close(); ok"); 58 } 59 } 60 } 61 }
整个项目结构

运行结果正确,数据成功插入;Hibernate: insert into user (username, password, userId) values (?, ?, ?)
2016-02-02 23:22:30,202 | INFO | main | dashuai.dao.UserDao.main(UserDao.java:47) | transaction.commit(); ok
2016-02-02 23:22:30,207 | INFO | main | dashuai.dao.UserDao.main(UserDao.java:57) | session.close(); ok

小结:持久化类和关系数据库的映射
说说POJO和JavaBean的区别?
前面简单说了POJO是什么——普通Java类,具有一部分getter/setter方法的那种类就可以称作POJO,理想地讲,一个POJO是一个不受任何限制的Java对象(除了Java语言规范)。例如一个POJO不应该是
- 扩展预定的类
- 实现预定的接口
- 包含预定的标注,如 @javax.ejb.Entity public class Baz{ ...
但是JavaBean则比 POJO复杂很多,JavaBean 是可复用的组件,JavaBean 并没有严格的规范,理论上讲,任何一个 Java 类都可以是一个 Bean 。但通常情况下,由于 JavaBean 是被容器所创建(如 Tomcat) 的,所以 JavaBean 应具有一个无参的构造器,另外,通常 JavaBean 还要实现 Serializable 接口用于实现 Bean 的持久性。JavaBean 是不能被跨进程访问的。
那么为什么需要JavaBean?
因为Java欠缺属性、事件、多重继承功能。所以在Java中实现一些面向对象编程的常见需求,只能手写大量胶水代码。JavaBean正是编写这套胶水代码的惯用模式或约定。对它最简单的理解是数据包,这个数据包里包含了一些信息(属性),比如名称,性别等,包含了可以给这些属性赋值和取值的方法(get和set方法)。通过实例化后的赋值操作,可在别的地方通过get方法把值取出来。这就是javabean,或者叫vo。如果在方法中含有了一些逻辑,比如getName的时候,要给name前面加上公司名称……通常情况下,就叫做bo。而数据库的表对应的持久化类一般叫POJO,这些东西都可以统称为javaBean,核心就是赋值(set)和取值(get)。如果需要用到读写硬盘的缓存,需要网络传输……则需要序列化这个javaBean.实现Serializable接口。
《spring in action》书里详细说到:
JavaBean :是公共Java类,但是为了编辑工具识别,需要满足至少三个条件:
- 有一个public默认构造器(例如无参构造器)
- 属性使用public 的get,set方法访问,也就是说属性设置成private,同时get,set方法与属性名的大小也需要对应。例如属性name,get方法就要写成,public String getName(){},N大写。
- 需要序列化。这个是框架,工具跨平台反映状态必须的
-
重写hashcode和equals方法(可选)……
……
- 在java1996年发布,当年12月即发布了java bean1.00-A,有什么用呢?这样java对象可以重用和统一操作,例如原来说的awt组件(例如一个点point(x,y),IDE可以自动展现它的状态量x,y给你配置,).这就是javaBean的来历,
- 在实际企业开发中,需要实现事务,安全,分布式,javabean就不好用了.sun公司就开始往上面堆功能,堆成了一个加强版的javaBean,这就是EJB的来历;
- EJB功能强大,但是太重了,很多时候都是杀鸡用牛刀!此时编程技术有了一定进展,就是DI(依赖注入),AOP(面向切面),开发者现在可以通过很简单的javaBean也能完成EJB的事情了。
- Spring诞生了.
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!
