1.使用drop_duplicates()函数删除重复的行
df.drop_duplicates()
2.映射
映射的含义,创建一个映射关系,把values元素和一个特定的标签或字符串绑定
map = {"label1":"value1","label2":"value2","label3":"value3"}
包含三种操作:
replace()函数:替换元素
最重要:map()函数:新建一列
rename()函数:替换索引
replace()
# 适应replace()函数,对values进行替换操作。
replace()对应参数有:
['to_replace=None', 'value=None', 'inplace=False', 'limit=None', 'regex=False', "method='pad'"]
在原数据的基础上对数据通过隐射的方式进行修改
如:df.replace({4:60,1:60},inplace=True)
map()
map()新建一列,是指使用原有的列生成一个新的列,适合处理某一单独的数据,任然是一个字典
map()函数中适合使用lambda函数或是重新定义一个函数。
map()也可以使用自定义的映射函数对values的某一列进行重新赋值。
扩展:transform()和map()类似的
apply和map类似
如:
def convert(x):
if x<60:
return "不及格"
elif x>=60 and x<80:
return "及格"
elif x>=80 and x<100:
return "一般"
elif x>=100 and x<120:
return "良好"
else:
return "优秀"
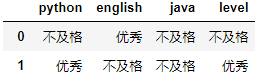
df["level"] = df["python"].map(convert)
df
3.rename()
rename()函数:替换索引
任然是新建的一个字典的映射关系
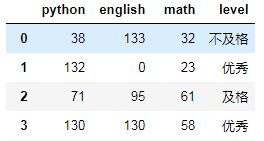
如:使用rename()函数替换索引
df.rename({0:"a",3:"B"}) #替换行索引
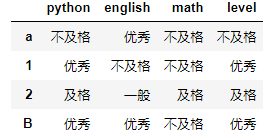
#替换列索引
df.rename({"math":"java"},axis=1)