Redis是一个开源的内存中的数据结构存储系统,它可以用作:数据库、缓存和消息中间件。可以理解成java中的HashMap,可以跨进程的进行访问。redis是单线程的,访问这个HashMap是采用的他规定的官方协议,redis 5.0 之前是是采用resp2.0的协议,redis6.0是采用resp 3.0。和MemCached一样都是k-v 结构的内存级别的数据库,所有的操作数据都是保存在内存中,所以性能非常的好,相较于磁盘存储。通过定期异步的方式,来进行数据的刷盘落库,在redis中,提供两种不同的刷盘方式,就是两种持久化方式 AOF 和RDB 。单k-v的容量可以达到1GB,还有丰富的数据类型,提供了八大数据类型。通过这八大数据类型,可以完成互联网中很多的应用场景。
redis先对与Memcached的优势
- memcached 所有的值均是简单的最字符串,而redis支持八种数据类型,数据类型丰富。
- redis 速度比memcached快
- redis支持数据持久化。
应用场景:
服务端购物车,热点数据缓存,分布式全局锁。计数器,抽奖,消息队列,点赞/打卡/签到,用户关注/商品推荐,排行榜等。
本篇介绍常用的五种数据类型:String hash list set zset
在线测试网站:https://try.redis.io/
1.String数据类型
在redis中String类型的数据,可以理解成在java中HashMap<String,Object>
其中Object 可以存储字符串 String,数值Number,二进制bit
String(String)
操作String的常用命令:
| 命令 | 含义 |
|---|---|
| SET | 存入一个字符串键 |
| SETNX | 存入一个字符串键 ,若key已存在则操作失败 |
| GET | 获取指定key的字符串 |
| MSET | 批量存入字符串键 |
| MGET | 批量获取指定key的字符串 |
| DEL | 删除指定key |
应用场景-1
分布式锁:
分布式锁的实现方式:redis、zookeeper、数据库行锁(后面抽空研究)
命令 SETNX 存在一种互斥性,那么使用SETNX + DEL 命令,就可以实现一个分布式锁。就比如我们有两台应用程序,一台向redis存入一个key为 KEY1 的字符串,此时另外一台redis存入一个key为 KEY1 的字符串 ,那么肯定是返回失败。
在这种场景下,如果一台服务器拿到锁之后,出现了异常情况,导致无法释放锁,那么就会出现死锁的情况,根据这一个问题,在redis2.0 redis提供了过期策略expire key +时间 单位为s,我们可以通过命令ttl key来查看当前剩余的过期时间。当到达设置的过期时间之后,会自动的删除key。
设置过期时间也会存在一定的问题,比如无用等待。那么这个过期时间就需要根据特定的业务场景,来适当的调整,通过压测等手段
这时候我们可能会产生质疑,如果在执行设置锁过期时间之前(就是在代码中通过SETNX设置存入了key之后)宕机了,导致过期时间没有设置成功,我们还是解决不了死锁的问题,redis中有一个命令,可以给设置锁和设置过期时间一个原子操作命令,原子操作即要么同时成功,要么同时失败
锁失控失效问题:在一般情况下上面的方式表面看是没有问题的,但是在高并发的情况下可能会存在问题。假设有这样的一个场景,我们redis锁设置10s的过期时间,当一个线程进来获取到锁之后,业务的执行时间达到了15s,此时线程1获得的锁已经是过期的锁,就是锁失效了。就表示此时如果有一个线程2进来可以获得锁。当线程2获得锁时候,此时,线程1 正好执行完毕,释放掉锁,就会导致线程1释放了线程2 的锁。会导致锁失控。
解决方法:设置一个全局的锁的id,这个id可以用uuid,在获取锁的时候将锁的id设置到value里面,当前线程执行完业务后释放锁之前先判断是否是自己的锁,如果是,则释放
我们还需要思考的问题
比如拿到锁后,锁的过期时间是30秒,处理业务30秒还是没有完成获取mysql在运行慢查询5分钟,这时候分布式锁还是失效
可以使用redisson;redisson原理?
String lockKey = "lockKey";
RLock redissonLock = redisson.getLock(lockKey );
redissonLock.lock();
.................处理业务
redissonLock.unlock()
String(number)
| 命令 | 描述 |
|---|---|
| INCRBY key increment | 对key 进行数量相加 |
| DECRBY key decrement | 对key 进行数量相减 |
| INCR key | 对key 的自加一 |
| DECR key | 对key 的自减一 |
应用场景: 实现全局唯一ID解决方案
String(bit)

| 命令 | 含义 |
|---|---|
| GETBIT key offset | 获取key下标offset的值 |
| SETBIT key offset value | 对key下标offset 设值 |
| BITCOUNT key [start] [end] | 统计start到end位置值为1的数量 |
| BITOPS opdestkey [key...] | 对多个key进行位计算 op(and/or/xod/not) |
应用场景1 ,在线用户统计
每上线一个用户 就 就设值位1,下线一个用户就设值为0
比如:所有的用户都用一个key userbit 来存储,那么SETBIT userbit 用户A的id 1 就是记录用户A上线了,SETBIT userbit 用户Ai的id 0就是表示用户A下线了。 再使用BITCOUNT userbit 就可以统计当前在线的用户。

2.hash数据类型:
hash数据类型可以理解为java中的HashMap<String,HashMap<String,Object>>,
| 命令 | 含义 |
|---|---|
| HSET | 存入一个key filed 散列结构 |
| HSETNX | 存入一个key filed ,若key中filed存在则操作失败 |
| HGET | 获取指定key filed |
| HMSET | 批量存入key filed |
| HMGET | 批量获取指定key filed |
| HDEL | 删除指定key filed |
| HINCRBY | 对key filed的数值进行加减操作 |
这种操作相较于String存储,优点:可以将信息凝聚在一起,便于管理。一定程度上减少key的冲突,比如用String来存储一张表的数据,会产生很多的key,这种结构的话,一张表就是一个key。

缺点:如果是在redis集群环境下,一个key只能在存在一个节点下,存在数据分布不均匀,不能使用expire,因为如果使用过期键,那么整个数据就被销毁了。不方便维护。
使用场景:
购物车的实现:
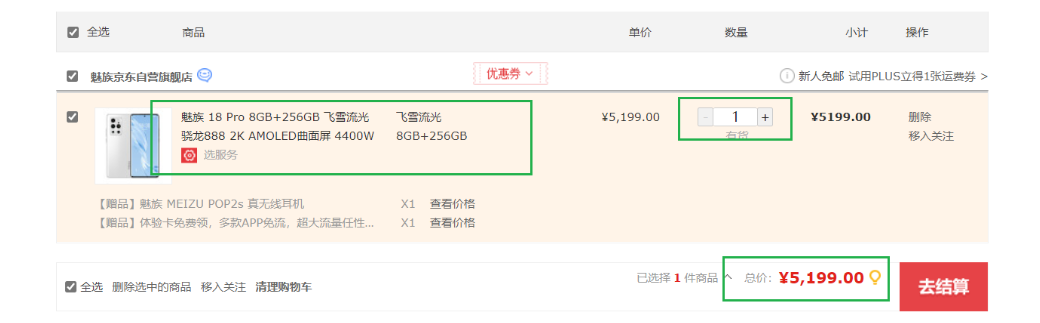
如:使用用户 id:car 生成一个唯一的Key,这个key就表示这个用户的购物车。
基本结构:用户id:car 商品:id 数量

对商品商量的加减操作:
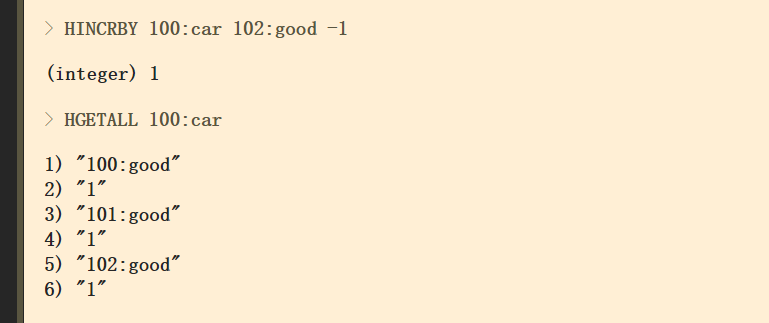
把得到的商品id和数量传给服务端计算,算出总价返回。
3.List数据类型:

可以理解成Java中的HashMap<String,List<Object>>
| 命令 | 含义 |
|---|---|
| LPUSH key value [value ...] | 在指定Key所关联的List Value的头部插入参数中给出的所有Values。 如果该Key不存在,则创建。 |
| RPUSH key value [value ...] | 在指定Key所关联的List Value的尾部插入参数中给出的所有Values。 如果该Key不存在,则创建。 |
| LPOP key | 返回并弹出指定Key关联的链表中的第一个元素,即头部元素。 如果该Key不存,返回nil。 |
| RPOP key | 返回并弹出指定Key关联的链表中的最后一个元素,即尾部元素。 如果该Key不存,返回nil。 |
| LRANGE key start stop | 获取列表键中start下标到stop小标的元素 |
| BLPOP key[key ...] timeout | 阻塞的从key的列表键最头部弹出一个元素,若列表中不存在元素, 阻塞等待timeout,若timeout=0,则一直阻塞。 |
| BRPOP key[key ...] timeout | 阻塞的从key的列表键尾端弹出一个元素,若列表中不存在元素, 阻塞等待timeout,若timeout=0,则一直阻塞。 |
应用场景: 获取关注的最新消息列表

LRANGE 0 -1 就是拿出整个键中的所有元素
异步队列:
rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
4.set数据类型
set集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。
| 命令 | 含义 |
|---|---|
| sadd key value… | 在指定key对应的集合中添加 value集合,如果key不存在,即新创建 |
| srem key value… | 移除指定key中的value集合,并返回移除的值的数量 |
| sismember key value | 判断指定key中指定value是否存在集合中,返回 0 或 1 |
| scard key | 返回指定key对应的集合长度 |
| smembers key | 返回指定key对应的集合中的所有元素 |
| spop key | 随机的移除key对应的集合中的某个元素,并返回移除的该元素 |
| sdiff key… | 以第一个key为基准,获取两个key对应集合的差集。 例如 key1:1 2 3;key2:1 2 4,那么以key1为基准, key2中只有 4 是不在key1对应的集合中的,那么 sdiff key1 key2 的结果就是 4 |
| sinter key… | 获取指定key对应的集合中的交集, 例如: key1: 1 2 3 ,key2:1 2 4;那么 sinter key1 key2的结果是获取交集,即 1 2 |
应用场景1:点赞/签到/打卡


应用场景2:用户关注/商品推荐


5.Zset(有序集合)数据类型
Zset 其实就是在 set 基础上加了一个 score 值。之前 set 是 k1 v1 v2 v3 ,那么现在 zset 是 k1 score1 v1 score2 v2,相当于它的 value 值又是一个 k-v 键值对
| 命令 | 含义 |
|---|---|
| ZADD key score element[...] | 向 zset 中插入数据,value 值又是一个 k-v 键值对, 其中 key 是 score 值。 若key不存在则新建。 |
| ZREM key [element...] | 从有序集合key中删除元素 |
| ZSCORE key element | 获取有序集合key中 element 元素的 score 值 |
| ZINCRBY key increment element | 给有序集合key中的element元素进行score值操作。若key不存在则新建。 element元素不存在则新增后进行score操作 |
| **ZCARD key ** | 获取有序集合key中的元素个数 |
| ZRANGE key start stop | 正序获取有序集合key从start下标到stop下标的元素列表 |
| ZRANGE key start stop [withscores] | 正序获取有序集合key从start下标到stop下标的元素列表联通score值一起 |
| ZREVRANGE key start stop | 倒序获取有序集合key从start下标到stop下标的元素列表 |
| ZREVRANGE key start stop [withscores] | 倒序获取有序集合key从start下标到stop下标的元素列表联通score值一起 |
| ZUNIONSTORE destkey numkeys key [key ...] | 并集计算 |
| ZINTERSTORE destkey numkeys key [key ...] | 交集计算 |
应用场景1: 排行耪
文章被点击一次:
#以日期为key 每点击一次articleId就+1
ZINCRBY article:{date} 1 {articleID}
#获取前十热点文章:
ZREVRANGE article:{date} 0 10 WITHSCORES
场景2: 定时任务的数据来源:
score值为ms数, element值为任务名称。
比如一个任务:再规指定的时间执行,如果当前时间大于这个时间了就执行。