(一)字典,dict全称“dictionary”,使用键值对(key-value)存储。各元素对应的索引或者下标称为键(key),各个键对应的元素称为值(value),字典中各元素的键都只能是字符串、元组或数字,不能是列表(列表时可变的)。字典是任何数据类型可变的无序集合,键值必须唯一不可变。
1、使用 { } 创建字典:
d = { key1 : value1, key2 : value2...}
# 根据同学的名字查找对应的成绩 score = {'Mike': 95, 'Nancy': 85, 'Helen': 89, 'John':65, 'Sarah':100}
2、通过 fromkeys() 方法创建字典
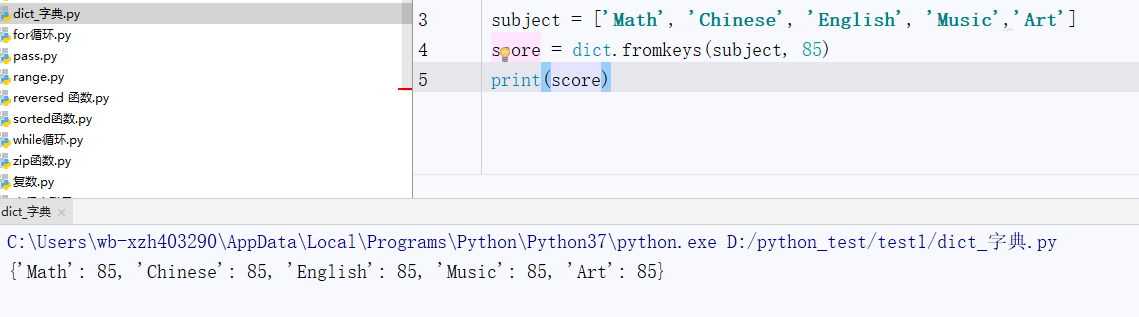
# 使用fromkeys()方法创建带有默认值的字典 d = dict.fromkeys(list, value = None)
实例练习:
3、通过 dict() 映射函数创建字典
# 字符串键值对,字符串不能带引号 a1= dict(str1=value1, str2=value2, str3=value3) # dict()函数传入列表或元组 #方式1 demo = [('abc',1), ('cde',2), ('efg',3)] #方式2 demo = [['abc',2], ['cde',1], ['efg',3]] #方式3 demo = (('abc',2), ('cde',1), ('efg',3)) #方式4 demo = (['abc',2], ['cde',1], ['efg',3]) a2= dict(demo) # 通过dict()函数和zip()函数,两个列表转换为对应的字典 keys =['abc', 'cde', 'efg'] values = [1,2,3] a3 = dict(zip(keys, values))
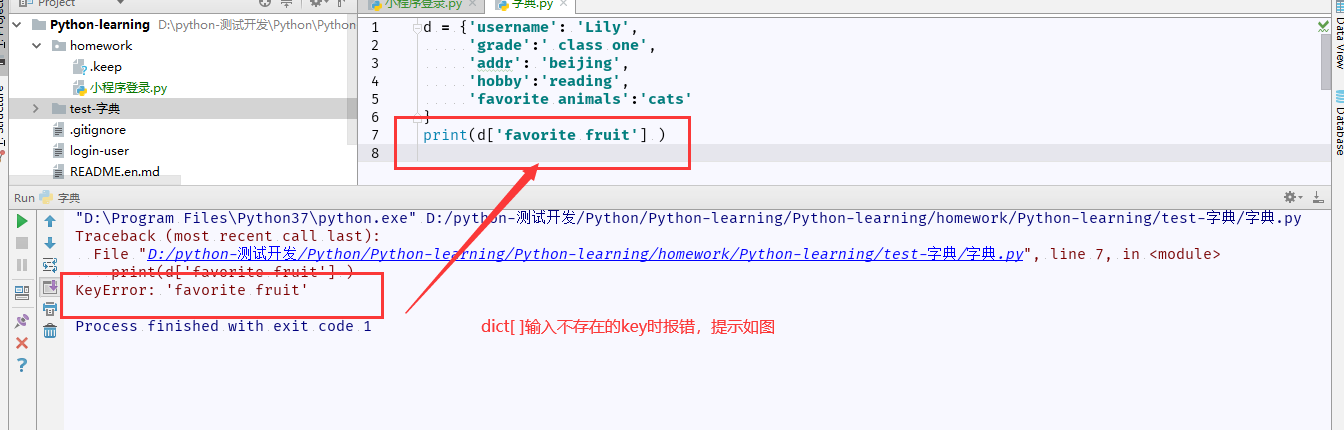
4、访问字典
# Python中访问字典元素的格式为: dict[key]
实例练习:

若键值不存在,则会抛出异常提示,如图:

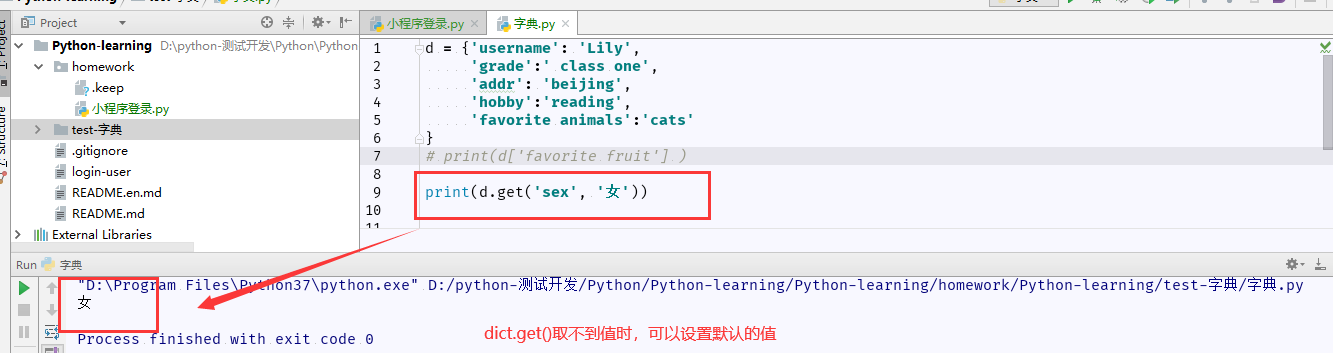
5、通过使用 get() 方法来获取指定键对应的值,当指定的键不存在时,get()方法不会抛出异常。
dict.get(key[,default])
实例练习:

若 get() 方法返回的是空值,则显示None

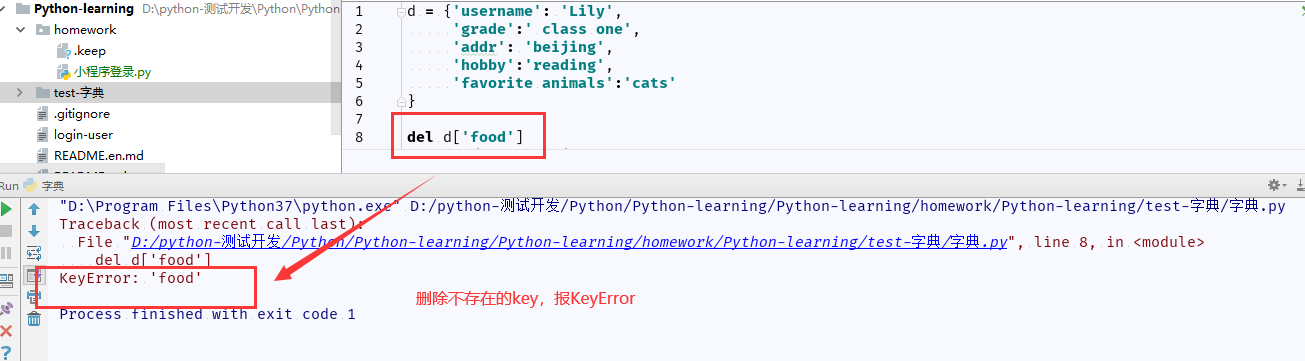
6、删除字典dict,可以使用 del 关键字删除字典
实例:
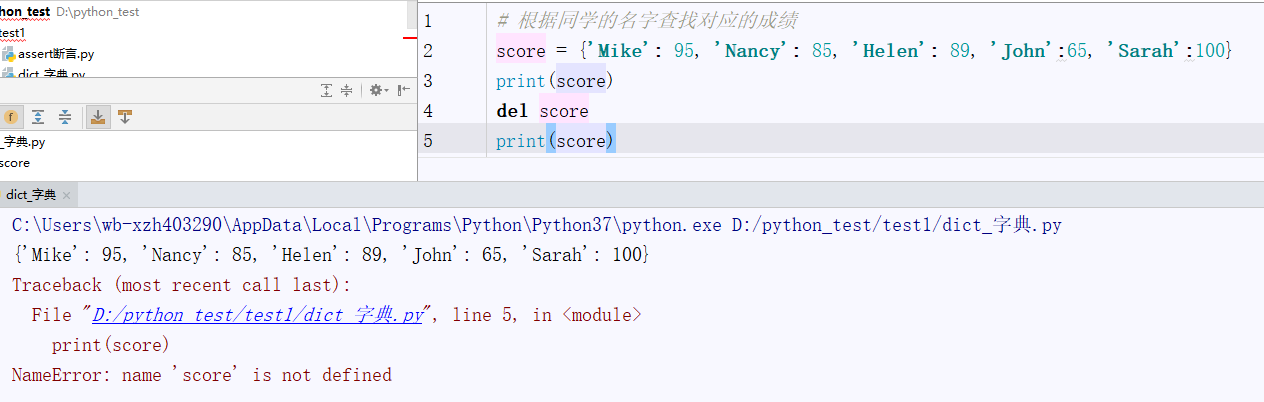
图中的del操作后,引发异常提示,del 删除后该score字典不再存在了。
7、dict 字典基本操作(添加、修改、删除键值对)
7.1 添加键值对
dict[key] = value
实例:

7.2 修改键值对,字典中键(key)不能被修改,只能修改值(value),新添加的键与已存在的键相同,那么所对应的键的值就会被新的值所替换。
实例:

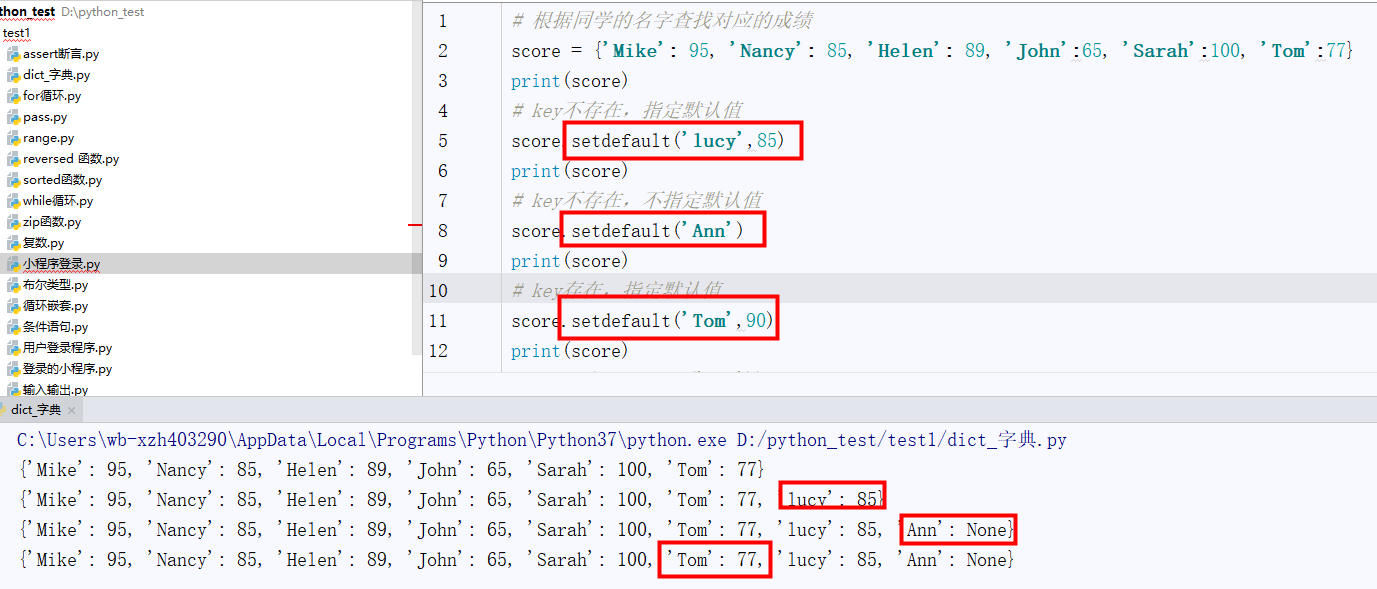
比较 dict[key] 和 dict.setdefault(key, default =None)区别:
dict[key]会把之前key对应的值修改掉,而dict.setdefault(key, default =None)不会修改键之前的对应的值(添加学生信息,一般使用setdefault来添加信息)
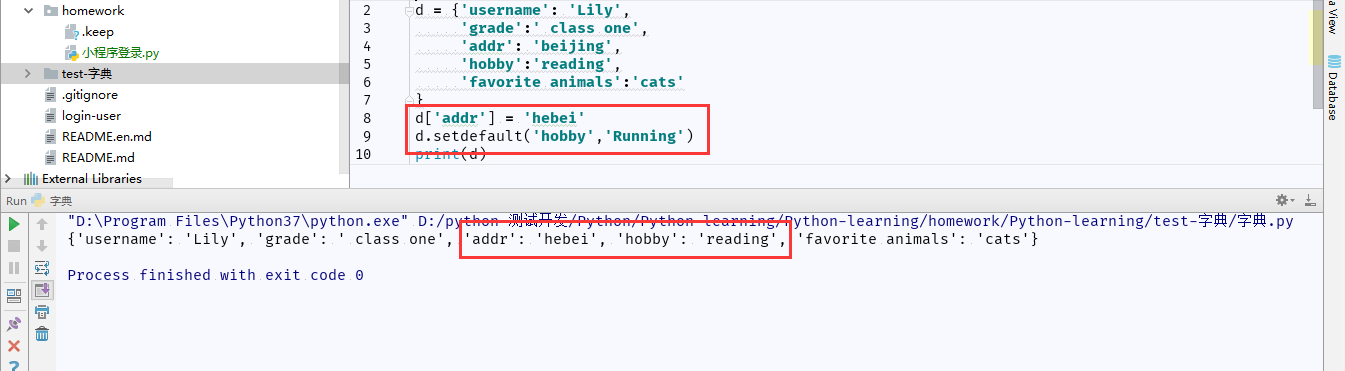
dict.setdefault(key, default=None)
7.3 删除键值对,用 del 语句删除键值对
实例:

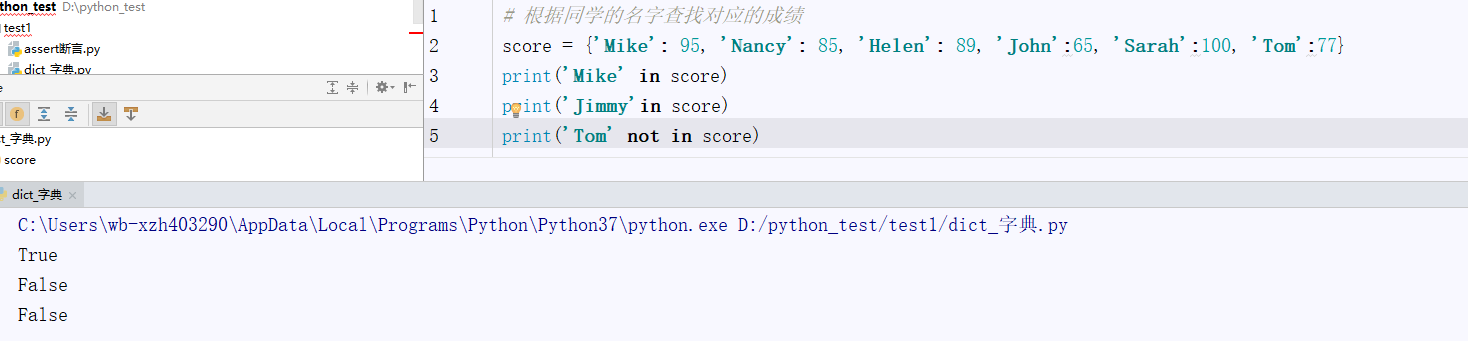
7.4、判断字典中是否存在指定键值对:首先判断字典中是否有对应的键值对,可以使用 in 或 not in 运算符。
8、字典数据类型为 dict ,该类型的基本方法
8.1 dict.keys() 方法:以列表返回一个字典所有的值
dict.values() 方法:以列表返回字典中所有值
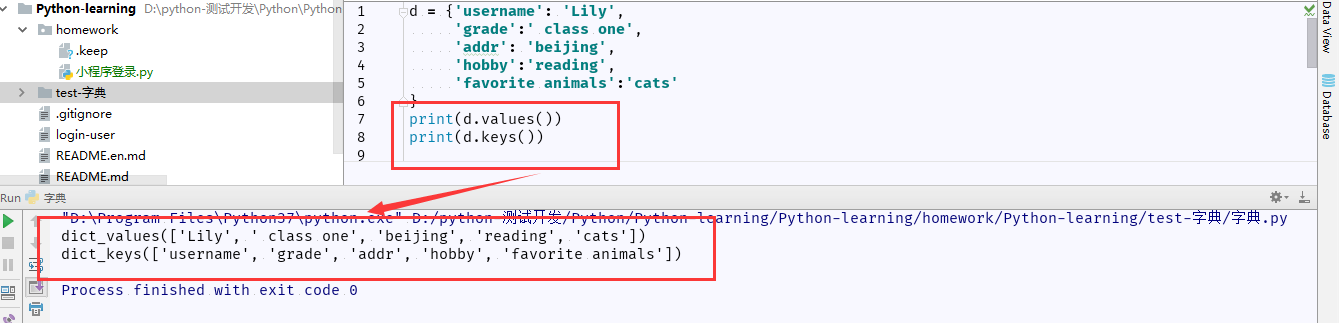
8.2 dict.items() 方法:以列表返回可遍历的(键、值)元组数组
实例中包含key()、value()、items():
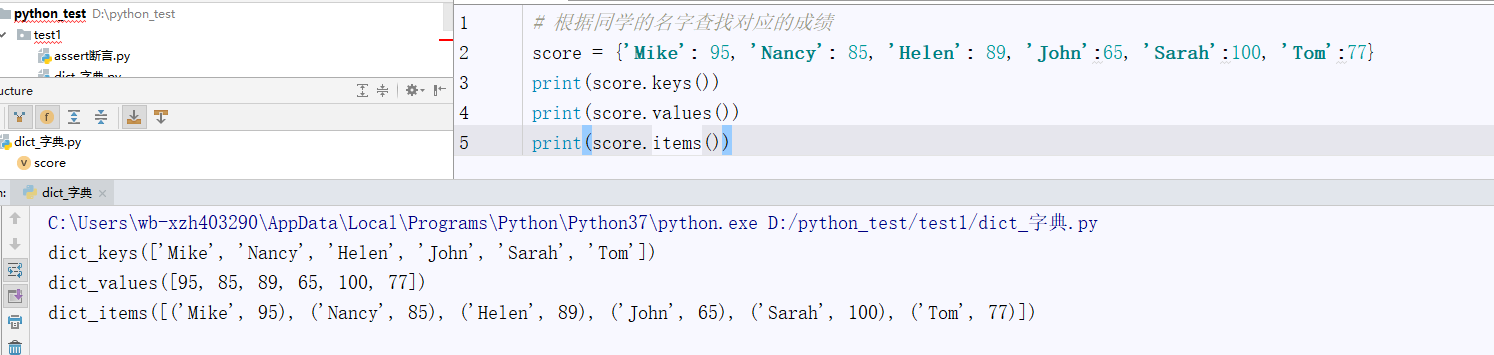
输出结果中,在 Python 2.x 中,上面三个方法的返回值都是列表(list)类型。但在 Python 3.x 中,它们的返回值并不是我们常见的列表或者元组类型,因为 Python 3.x 不希望用户直接操作这几个方法的返回值。
python 3.X中一般返回的数据方法为:list() 函数 和 for in 循环变量它们的返回值
(1)list() 函数实例:

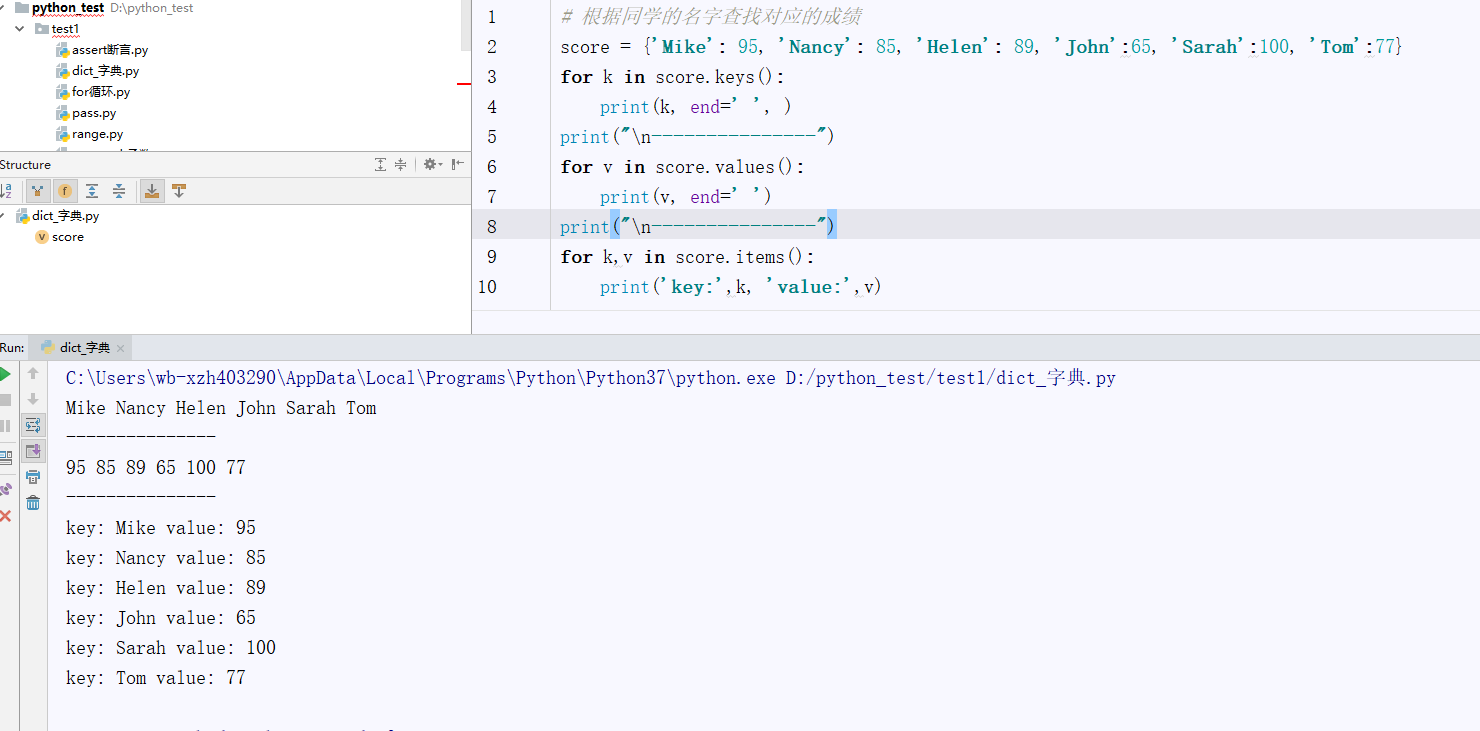
(2)for in 循环遍历
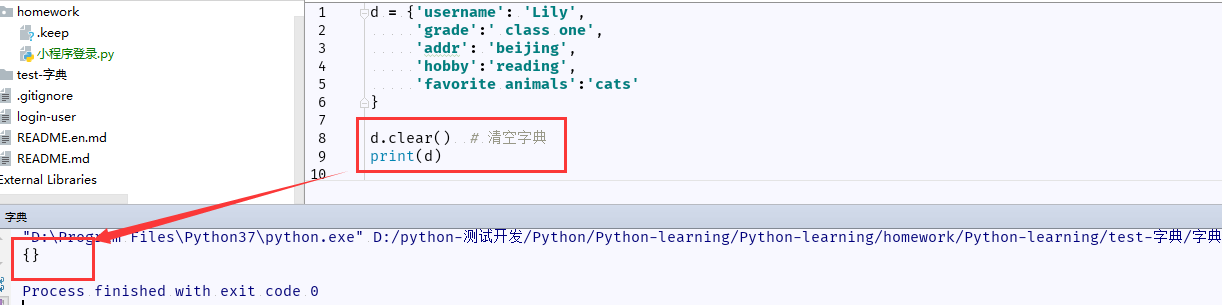
8.3 dict.clear() :删除字典内所有元素
8.4 dict.copy() :返回一个字典的浅复制
实例如图:copy() 方法将字典score 的数据全部拷贝给了字典score1

8.5 dict.get(key,default=None):返回指定键的值,如果值不存在返回default默认的None值:
(1)dict.get()
(2)dict[]和dict.(key,default=None)qq区别:

8.6 dict.has_key(key):若键在字典返回True,反之返回False (Python 2.X函数使用方法)
Python 3.X的使用方法为:
score = {'Mike': 95, 'Nancy': 85, 'Helen': 89, 'John':65, 'Sarah':100, 'Tom':77}
# score.has_key('Mike') python2的函数
print(score.__contains__('Mike')) # Python 3 的函数使用
8.7 dict.setdefault(key,default = None):与get()方法类似,若键不存在字典中,将会添加键并将值设为指定值默认None
get() 和 setdefault() 区别在于:当指定的键不存在时,setdefault() 可以通过增加键值对来更新字典。
8.8 dict.update(dic2):字典dict2的键值对更新到dict里
实例中,update()操作如图
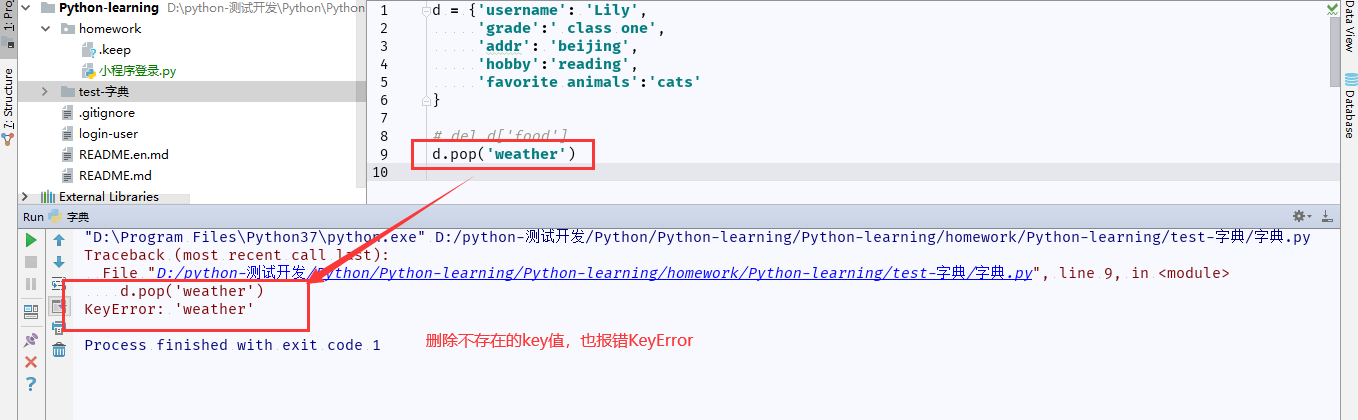
8.9 dict.pop(key[,default]):删除字典给定的键对应的值,返回值为被删除的值。
(1)dict.popitem() :返回并删除字典中最后一对键值对
实例中,pop() 和 popitem() 删除操作

(2)del d[ key] 和 dict.pop(key)删除不存在的key时:
8.10 dict.fromkeys(seq[,val]):创建一个新字典,四五千中元素做字典的值,val为字典所有键对应的初始值

9.利用字典判断字典里面的值存不存在
users ={ 'Amy': '123456', 'Bob': '456789', 'Mike': '147258' } username = 'Amy' # print(username in users.keys()) # print(username in users) # 推荐使用这个,判断Key是否存在 # users.has_key(username) # python2 方法 print(users.items()) # 循环遍历字典,以列表方式展示 for k,v in users.items(): print(k,v) for k in users: print(k,users.get(k)) # 推荐循环字典操作
字典练习:注册用户,用户名,密码,确认密码,最多输入3次,超过3次提示错误次数超限,账号密码不能为空,两次输入密码是否一致,输入的用户是否存在
users = { 'Amy':'123456', 'Bob': '456789', 'Mike':'147258' } for i in range(3): username = input('用户名:').strip() password = input('密码:').strip() cpwd = input('再次确认密码:').strip() if username == '' or password =='' or cpwd == '': print('账号或密码不能为空!') elif password != cpwd: print('两次输入的密码不一致!') elif username in users: print('用户名已存在!') else: users[username] = password print('注册成功!') break else: print('错误次数过多!') print(users)
(二)list字典嵌套
实例:字典里嵌套字典,字典里面嵌套list
info = { 'Amy':{ 'age':18, 'addr':'beijing', 'tel':'18801124520', 'hobby':['reading', 'running', 'playing tennis'] }, 'Nick':{ 'age':20, 'addr':'tianjin', 'tel':1302254850, 'hobby':['movies', 'cooking', 'playing badminton'] } } # Amy hobby中不喜欢running了,喜欢上了art # Nick Tel 手机变成了:15055001550 info['Amy']['hobby'].remove('running') info['Amy']['hobby'].append('art') info['Nick']['tel']=(15055001550) print(info)
(三)元组(tuple):元组的元素不能修改
1、元组、列表、字典表示方式:
# 元组用小括号() a = (1,2,3,4,5) # 列表用方括号[] b = [1,2,3,4,5] # 字典用花括号{} c = {key:value}
2、元组和列表(list)的不同之处在于:
- 列表的元素是可以修改的,包括修改元素值,删除和插入元素,所以列表是可变序列;
- 元组一旦被创建,其元素不可修改,故元组是不可变序列。通常情况下,用于保存无需修改的内容。
3、创建元组
(1)使用()直接创建元组
# 创建元组 tuple = (a1,a2,a3,..,n)
若元组中只包含一个元素时,需要在元素后面添加逗号,否则解释器会将它视为字符串:
# 元组中只包含一个元素时: tup1 = (a1,)
实例:
# int float bool None list str dict tuple n= (1,2,3,4,5) # 不可变的列表 # 元组一旦被创建,不能改变里面的值 print(n[0])
(2)使用tuple()函数创建元组
使用内置函数 tuple()
# data可以是字符串,元组,range对象转换为元组 tuple(data)
#将字符串转换成元组 tup1 = tuple("hello") print(tup1) #将列表转换成元组 list1 = ['Python', 'Java', 'C++', 'JavaScript'] tup2 = tuple(list1) print(tup2) #将字典转换成元组 dict1 = {'a':100, 'b':42, 'c':9} tup3 = tuple(dict1) print(tup3) #将区间转换成元组 range1 = range(1, 6) tup4 = tuple(range1) print(tup4) #创建空元组 print(tuple())
4、元组的index()方法和count()方法
m = ('1245521.2555', 'admin', '1545646') print(m.index('admin')) print(m.count('admin'))
5、访问元组,可以使用索引index()访问元组中的某个元素,也可以使用切片访问元组
# 使用索引访问元组元素: m = ('1245521.2555', 'admin', '1545646') print(m[2]) # 使用切片访问元素 word=tuple('wearefamily') print(word[2:5:1]))
6、修改元组:不可变序列,元组中元素不能被修改。只能创建新的元组替换旧的元组。
tup1 = (100, 55.26) tup2 = ('hello', 'hi') print(tup1) print(tup2) # 创建一个新的元组 tup3 = tup1 + tup2 print(tup3)
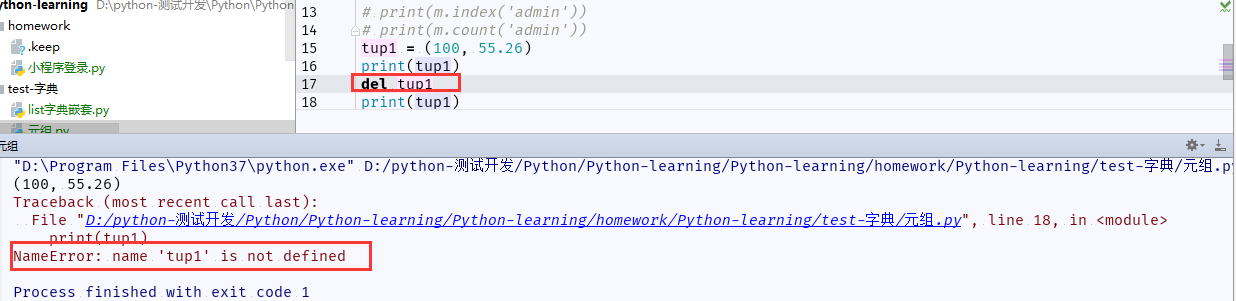
7、删除元组:可以通过del 关键字删除整个元组。
实例如图:
(四)集合:是一个无序的不重复的元素序列,可以使用大括号 { } 或者 set() 函数创建集合,创建一个空集合必须用 函数 set() 不能用 { } (用{ }创建一个空字典)。
1、创建集合
# 创建集合 setname = {value1, value2, value3,...} # 使用 set() 函数 setname = set(vlaue)
2、访问set集合元素:使用循环结构,逐一读取数据。
a = {1,2,3,4,5,6,7,8,9}
for b in a:
print(b,end=' ')
3、删除 set 集合,使用 del() 语句
a = {1,2,3,4,5,6,7,8,9}
print(a)
del(a)
print(a)
4、集合中,添加元素
(1)使用 add() 方法
注意:使用add()方法添加元素,若元素已存在则不进行该添加操作,只能添加数字、字符串、元组或布尔类型,不能添加列表、字典、集合可变数据,否则会报错,例如:TypeError: unhashable type: 'list'
# 集合中添加元素 setname.add(x) # 例如: a = {1,2,3,4,5} a.add((1,2)) print(a)
(2)还可以使用 update() 方法,且参数可以是列表、元组、字典
# 添加元素,使用 update() 方法 a = {1,2,3,4,5,6,7,8,9} print(a) a.update(['ab','bc']) print(a)
5、集合中删除元素
(1)可以使用remove() 方法,若元素不存在,则会发生错误,例如:KeyError: 'a'
# 移除集合中的元素,使用remove() setname.remove() a = {1,2,3,4,5,6,7,8,9} print(a) a.remove(1) print(a
(2)移除集合中的元素,使用 discard() 若元素不存在,不会发生错误
# 移除集合中的元素,使用 discard() 方法 a = {1,2,3,4,5,6,7,8,9} print(a) a.discard('a') print(a)
(3)随机删除集合中的一个元素
# 使用 pop() 方法随机删除 a = {1,2,3,4,5,6,7,8,9} print(a) print(a.pop( ))
(五)字符串常用方法
s = ' abcdefgABCDEabcdefg ' # 常用的字符串方法 # s.count('a') # 统计字符串出现的次数 # print(s.count('a')) # s.index('a') # 检索是否包含指定的字符串,不存在抛出异常:ueError: substring not found # print(s.index('b')) # print(s.find('b')) # 检索字符串中是否包含目标字符串,不存在会抛出异常,以:-1 返回 # s.strip() # 删除字符串前后(左右两侧)的空格或特殊字符 # print(s.strip()) # s.lstrip() # 删除字符串前面(左边)的空格或特殊字符 # print(s.lstrip()) # s.rstrip() # 删除字符串后面(右边)的空格或特殊字符 # print(s.rstrip()) # s.replace() # 把字符串中的 old(旧字符串) 替换成 new(新字符串) # print(s.replace('a','A',1)) # (将被替换的子字符串,新字符串,替换次数) # s.format() # 字符串格式化 # print("{} {}".format("hello", "world") ) # 不设置指定位置,按默认顺序 # print("{0} {1}".format("hello", "world") ) # 设置指定位置 # print( "{1} {0} {1}".format("hello", "world")) # 设置指定位置 # s.upper() # print(s.upper()) # 将字符串中的小写字母转为大写字母 # # s.lower() # 将字符串中的大写字母转为小写字母 # print(s.lower()) # s.zfill() # 返回指定长度的字符串,原字符串右对齐,前面填充0 # s1= '12' # print(s1.zfill(3)) # s.isdigit() # 判断是否为纯数字 # s2 = '1.23' # print(s2.isdigit()) # s.endswith() # 判断字符串是否以指定后缀结尾 # print(s.endswith(',')) # s.startswith() # 判断是否以指定字符串开头 # print(s.startswith(' ')) # 用的比较少些 # s.format_map() # 字典字符串 # print('{name},{value}'.format_map({"name":"Amy","value":250})) # s.center() # 字符串居中 # print('欢迎登陆'.center(50,'*')) # print('登陆结束'.center(50,'*')) # s.title() # 返回"标题化"的字符串,所有单词都是以大写开始,其余字母均为小写 # print('hello world'.title()) # s.isspace() # 判断字符串是否含有空格 # print(' '.isspace()) # s.isupper() # 判断字符串中所有的字母是否都为大写 # print(s.isupper()) # s.islower() # 判断字符串中所有的字母是否都为小写 # print(s.islower()) # s.capitalize() # 将字符串的第一个字母变成大写,其他字母变小写 # print('hello world'.capitalize()) # 重要的 # s.split() # 分隔字符串 # s2 = '''hello # nihao # hi # good # bad # worse''' # print(s2.split(' ')) # print(s2.split('#')) # 以不存在的分隔符进行分隔,分隔不了把原来的字符串放在list中,不报错 # s.join() # 将序列中的元素以指定的字符连接生成一个新的字符串 # l = ['art', 'English', 'Math', 'Chinese', 'Music'] # l_str =' '.join(l) # print(l_str) # print(type(l_str))
(六)切片:是list范围取值的一种方式
import string # print(string.ascii_lowercase) # print(string.ascii_uppercase) # print(string.digits) # print(string.ascii_letters) # print(string.punctuation) # 0 1 2 3 4 5 6 7 8 9 10 11 12 13 l = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n'] # -14 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 print(l[2:10]) print(l[2:]) # 取值到末尾 print((l[:5])) # 从最前面取值 print(l[:]) # 取所有的元素 print(l[0:10:1]) # 从最前面开始,取值到第10个,步长为1 # 切片的时候顾头不顾尾的 print(l[::-1]) # 取所有的元素,步长为负数时,取值范围就要从右往左开始取,同时开始和结束下标也要写成负数
(七)深拷贝和浅拷贝
1、copy.copy() 浅拷贝只拷贝父对象,不会拷贝对象的内部的子对象;
2、copy.deepcopy() 深拷贝,只拷贝对象及其子对象
3、拷贝对象是个一维列表,浅拷贝和深拷贝没有区别,均是重新申请一个新的内存地址;
4、嵌套列表、字典嵌套列表,深拷贝和浅拷贝完全不同。
(1)列表:进行浅拷贝和深拷贝
# 浅拷贝 import copy # 定义一个列表,其中一个元素是可变类型 list1 = [[1,2], 'sun', 55] print(list1) # 进行浅拷贝 list2 = copy.copy(list1) print(list2) # # 查看对象地址是否相同(答案是结果是不同的) print(id(list1)) print(id(list2)) # # 查看第一个元素地址是否相同(答案是结果是相同的) print(id(list1[0])) print(id(list2[0])) # 查看第二个元素地址是否相同(答案是结果是相同的) print(id(list1[1])) print(id(list2[1])) # 改变第一个值,查看复制对象变化 (结果复制对象发生变化) list1[0][0] = 2 print(list1) print(list2) # 改变第二个值,查看复制对象变化(复制对象没有发生变化) list1[1] = 'moon' print(list1) print(list2)
# 深拷贝 import copy # 定义一个列表,其中一个元素是可变类型 list1 = [[1,2], 'sun', 55] print(list1) # 进行深拷贝 list2 = copy.deepcopy(list1) print(list2) # 查看对象地址是否相同(结果是不同的) print(id(list1)) print(id(list2)) # 查看第一个元素地址是否相同(结果是不同的) print(id(list1[0])) print(id(list2[0])) # 查看第二个元素地址是否相同(答案是结果是相同的) print(id(list1[1])) print(id(list2[1])) # # 改变第一个值,查看复制对象变化 (复制对象没有发生变化) list1[0][0] = 2 print(list1) print(list2) # 改变第二个值,查看复制对象变化(复制对象没有发生变化) list1[1] = 'moon' print(list1) print(list2)
(2)字典:进行浅拷贝和深拷贝
import copy a = {1:[1,2,3]} # 原始对象 b = a # 赋值,穿对象的引用 c= copy.copy(a) # 浅拷贝 d = copy.deepcopy(a) # 深拷贝 print(a) print(b) print(c) print(d) a[1].append(4) # 修改对象a的list print(a) print(b) print(c) print(d)
(八)非空即真,非0即真
# None {} () [] '' # True False # username =input('username:') # password =input('password:') # if username.strip(): # print('你输入的不为空',username) # else: # print('username不能为空')
(九)操作文件
1、绝对路径和相对路径
(1)绝对路径:从根文件夹开始,Windows系统以(C: 或D:)作为根文件夹;OS系统或者Linux系统以 / 作为根文件夹。
(2)相对路径:指文件相对于当前工作目录所在的位置。
2、打开文件:open(文件路径和文件名,打开模式)
(1)绝对路径的打开方式
#Windows 系统 open(r'D:userXXXa.txt') # OS或Linux系统 open('/XXX/XXX/a.txt')
注:“r”表示字符串中的转义字符不进行转义。
(2)打开模式分别为:r、w、a、r+、w+、a+、x、b、t、+
r:只读模式,如果文件不存在,返回异常FileNotFoundError,默认值;只能读不能写,写入的时候报错: io.UnsupportedOperation: not writable
r+:打开不存在的文件报错:FileNotFoundError
w:覆盖写模式,文件不存在则创建一个文件,存在则完全覆盖源文件;只能写,不可读报错:
io.UnsupportedOperation: not readable
w+:都会清空文件
a:追加写模式,文件不存在则创建一个文件,存在则在原文件最后追加内容;只能写,不可读,报错:io.UnsupportedOperation: not readable
a+:追加文件,可读,但读不到内容
b:二进制文件模式
t:文本文件模式,默认值
+:与r/w/x/a一同使用,在原功能基础上增加同时读写功能
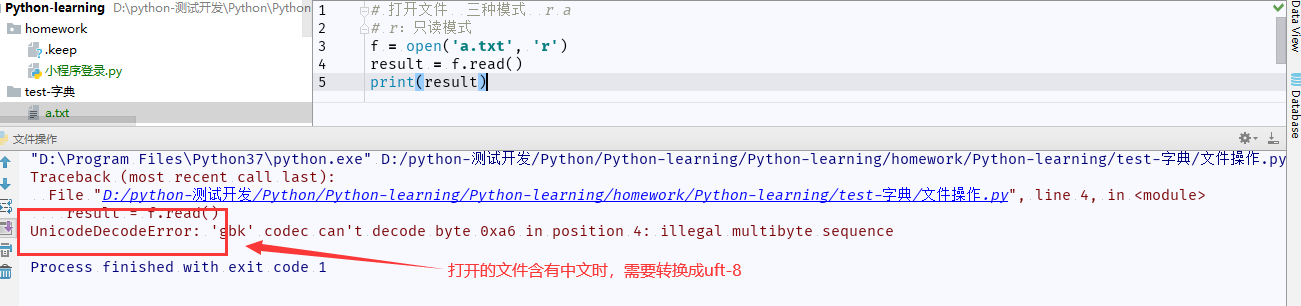
3、读取文件内容:read()
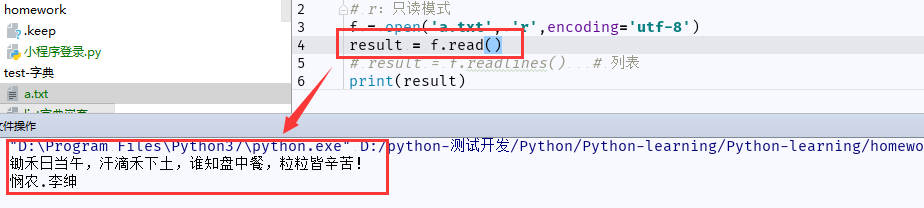
(1)打开文件,进行读取文件,当文件中含有中文时,报错:UnicodeDecodeError,这是需要加上字符集:encoding='utf-8'
# r:只读模式 f = open('a.txt', 'r',encoding='utf-8') result = f.read() print(result)
(2)读取的文件不存在时,报错:FileNotFoundError
(3)read()、readline()和readlines()的区别
- f.read():从文件中读取整个文件内容,结果是一个字符串;
- f.readline():从文件中读取一行内容,结果是一个字符串
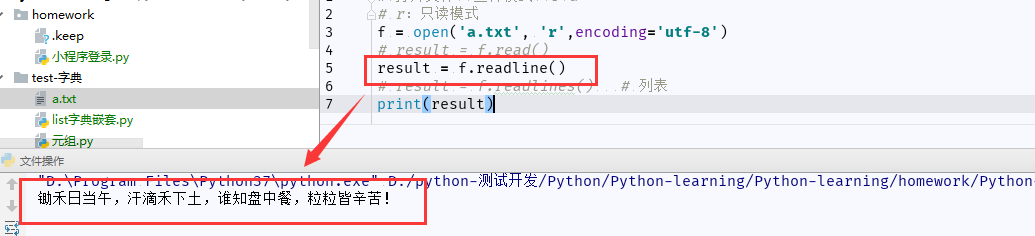
- f.readlines:从文件中读取所有行,以每行元素组成一个列表;

- read和reline操作在文件的读取时,会记录上次读取的位置,继续往下读取,而readlines是将原来的文件的最初的每一行 内容输出为列表。
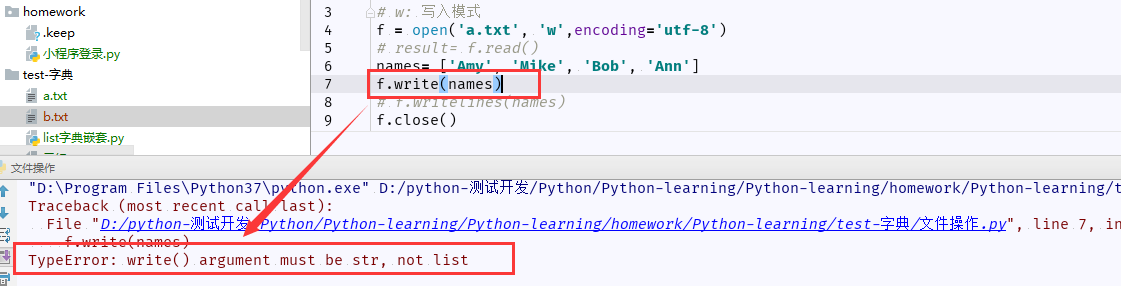
4、写入文件内容:write()
(1)向文件写入字符串S,每次写入后,记录写一个写入指针。
(2)写入文件,write() 不能以列表写入,必须是字符串,否则报错:TypeError: write() argument must be str, not list
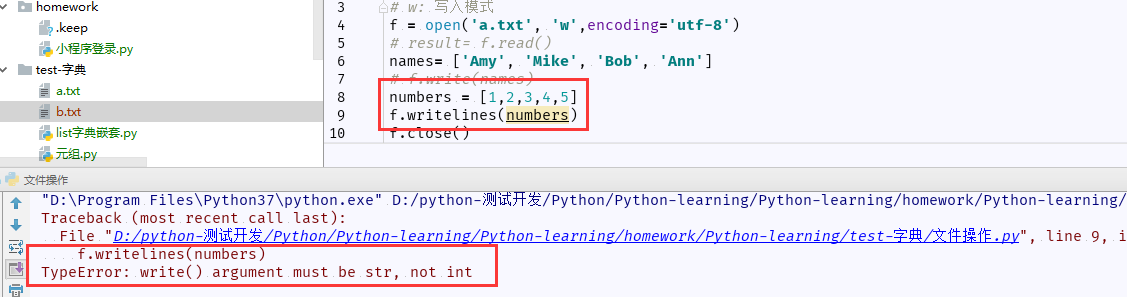
(3)写入文件,writelines()可以以列表写入文件里面

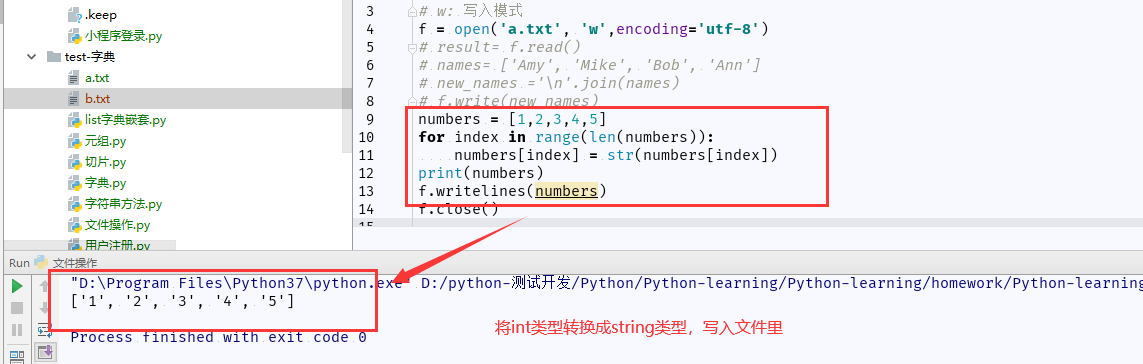
注意:writelines()其实封装write()字符串类型,不能是整型
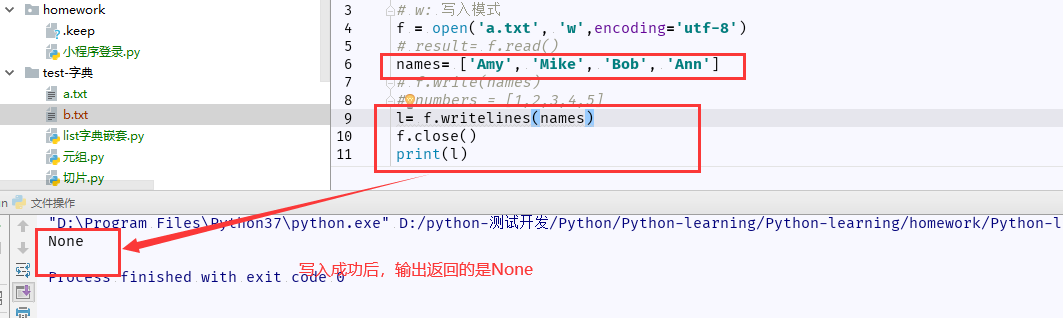
(4)write()写完之后,输出返回值为None
(5)写入内容需要换行展示:' '.join()
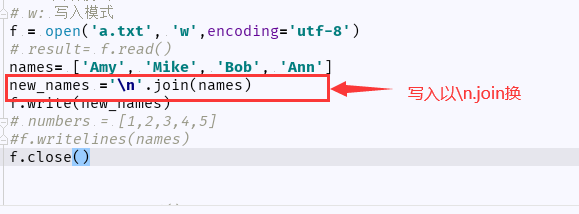
(6)将int类型转换string类型写入
5、文件指针:记录文件读取到哪一行
(1)seek() 函数:改变当前文件操作指针的位置,0代表文件开头,2代表文件结尾。
file.seek(放置位置,偏移量)
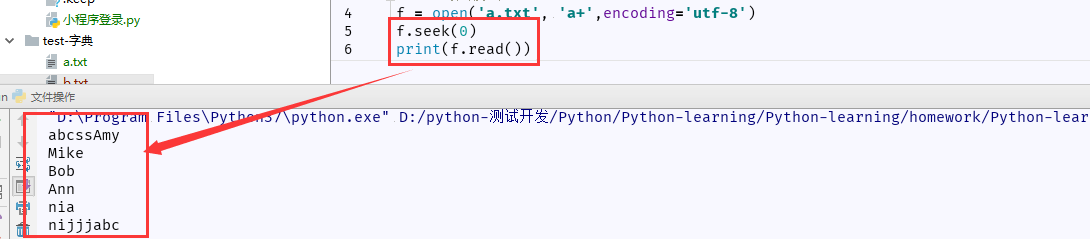
(2)清空文件内容后,添加修改内容
实例1:

实例2:

6、关闭文件
变量名.close()