zipkin和sleuth配合使用,可以实现分布式调用链路追踪。
zipkin是twitter开源的,作为服务端。sleuth是spring cloud的组件,作为客户端。
zipkin的作用是收集客户端报上来的数据,存储并提供查询接口、查询页面,它有4个核心成员:
Collector,收集器,用于接收客户端传过来的信息
Storage,存储器,存储接收来的信息,可以存在内存中,也可以持久化到数据库中、es中等
Restful api,提供一些接口让我们调用,返回一些指标信息
Web ui,可以在ui页面上查询。其实查询时就是调用上面的api接口
sleuth的作用是向服务端上报调用耗时等数据,它有几个重要概念
trace:一个请求进来到响应,这个过程中后台系统间调用的链路就是一个trace
span:一个服务调用另一个服务,这就是一个span
如何启动zipkin服务端?zipkin github推荐下载jar包,直接java -jar启动。默认占用9411端口。默认是把接收到的数据放在内存中,这样的话,server重启后,之前的数据会丢失。生产上会放到mysql或者es中,可以在启动时用相应参数指定。
如何保证zipkin服务端的高可用呢?
sleuth客户端写在我们的应用中。
1、在pom.xml中引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2、在配置文件中添加
spring.sleuth.web.client.enabled=true
spring.sleuth.sampler.probability=1.0
spring.zipkin.base-url=http://127.0.0.1:9411
第一个是表示启动sleuth,第二个是表示取样比例,1.0表示所有的trace都上报,0.5表示有一半的trace会上报。第三个表示zipkin服务端地址,即把数据上报到哪里。sleuth和zipkin相关的配置还有很多,这里不详细阐述。
从浏览器发起一个请求,让后台有多个服务调用,可以在zipkin server ui上看到服务调用关系以及每阶段的耗时。如下图
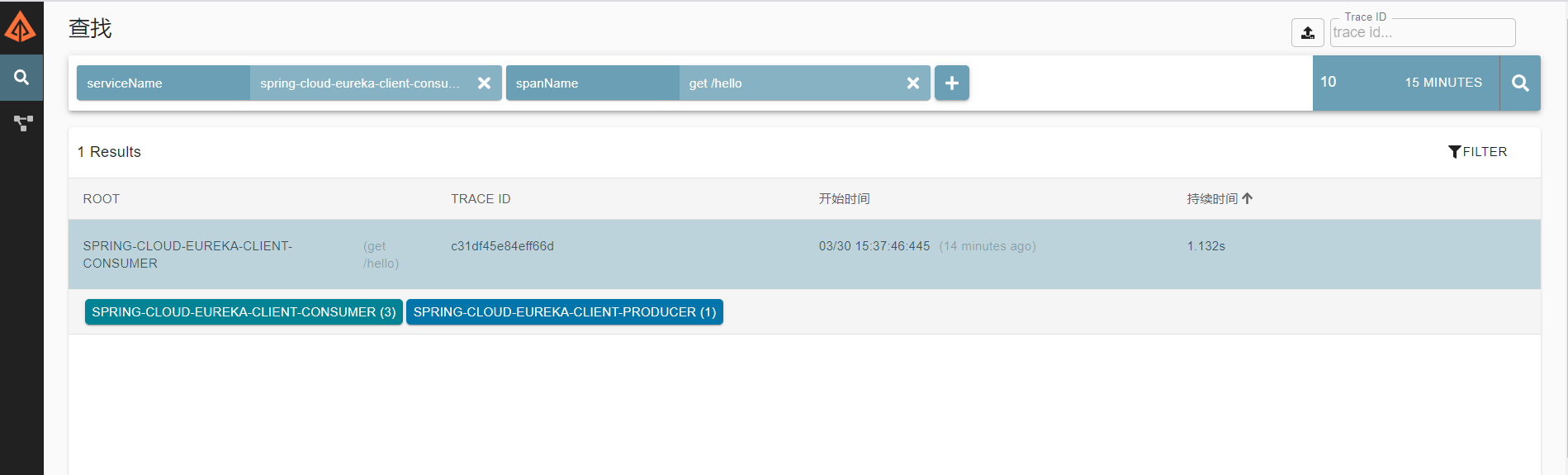
如上,一个trace id就对应着一次完整的请求响应过程。点进去可以看到整体耗时及每个阶段的耗时。