本次作业已上传至GitHub
PSP表格
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
60 |
70 |
|
· Estimate |
· 估计这个任务需要多少时间 |
60 |
70 |
|
Development |
开发 |
830 |
1020 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
300 |
350 |
|
· Design Spec |
· 生成设计文档 |
200 |
210 |
|
· Design Review |
· 设计复审 |
50 |
40 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
30 |
|
· Design |
· 具体设计 |
30 |
30 |
|
· Coding |
· 具体编码 |
100 |
120 |
|
· Code Review |
· 代码复审 |
30 |
20 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
100 |
120 |
|
Reporting |
报告 |
370 |
410 |
|
· Test Repor |
· 测试报告 |
300 |
320 |
|
· Size Measurement |
· 计算工作量 |
20 |
20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
50 |
70 |
|
· 合计 |
1260 |
1500 |
计算模块接口的设计与实现过程
- 算法流程图
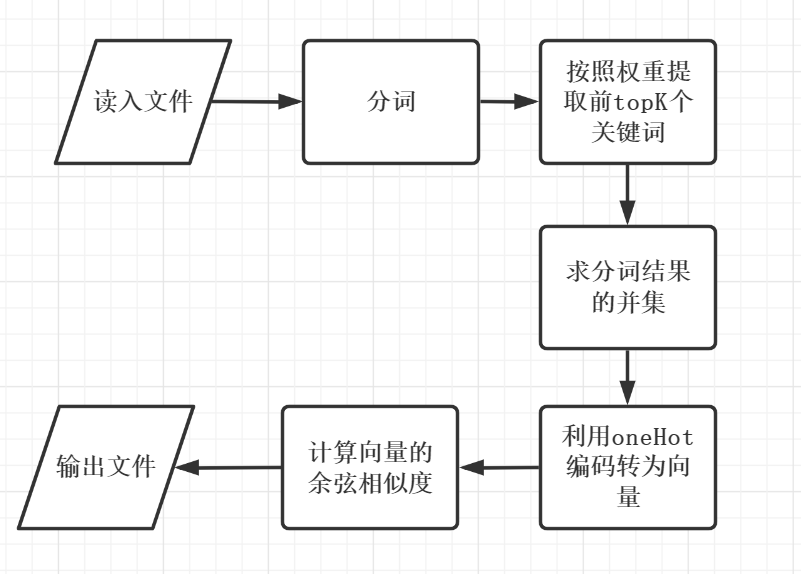
- 算法思想
整段代码用一个类(CosineSimilarity)封装,每个步骤分别用一个方法封装,最后用calculate方法串起来。
接下来简单介绍一下CosineSimilarity类中的各个方法:
- init 构造方法。 用于传入两个文本
- extract_keyword 提取关键词。 先通过jieba分词,再把分词结果提取出前K个权重最大的关键词
- one_hot 对关键词进行one_hot编码。 把文本转为向量
- calculate 计算余弦相似度。 把前面的所有方法串起来,并计算得到结果
这段代码参考了网上大佬的GitHub。如果只对分词结果进行余弦相似度的计算,对于短文本的准确率还可以,而对于长文本就不太行。因此,提取了前topK个关键词,对关键词进行相似度的计算,准确率会提高一点点。
关于topK的选取: 取群里的测试数据,一篇文章大概由10000个词组成,按照topK从1-2000,依次验证一下,发现topK在1600以后基本收敛,而在1100左右性能较好。因此,选取topK = int(len(seg)/9),其中seg为文章的分词结果。这个选取方法不是很严谨,缺少更多数据的验证。
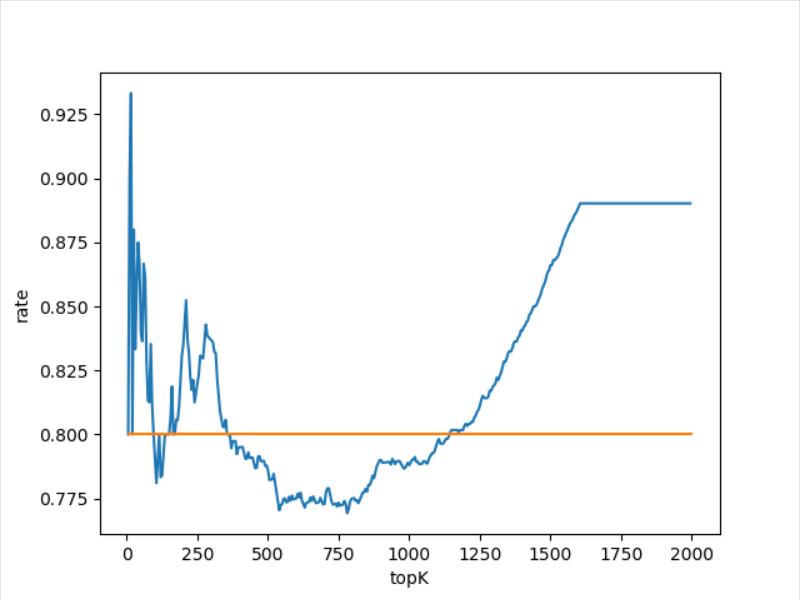
验证的代码如下:
import matplotlib.pyplot as plt
y = []
with open(r"test_dataorig.txt",encoding="utf-8") as fp:
ori = fp.read()
with open(r"test_dataorig_0.8_add.txt",encoding="utf-8") as fp:
copy = fp.read()
s = CosineSimilarity(ori,copy)
x = [i for i in range(5,2000,5)]
for i in range(5,2000,5):
topK = i
ans = s.calculate()
y.append(ans)
# print("topK = ",topK,"相似度:",ans)
print(y)
plt.plot(x,y)
plt.xlabel("topK")
plt.ylabel("rate")
x2 = [5,2000]
y2 = [0.8,0.8]
plt.plot(x2,y2)
plt.show()
计算模块接口部分的性能改进
- 运行时间分析
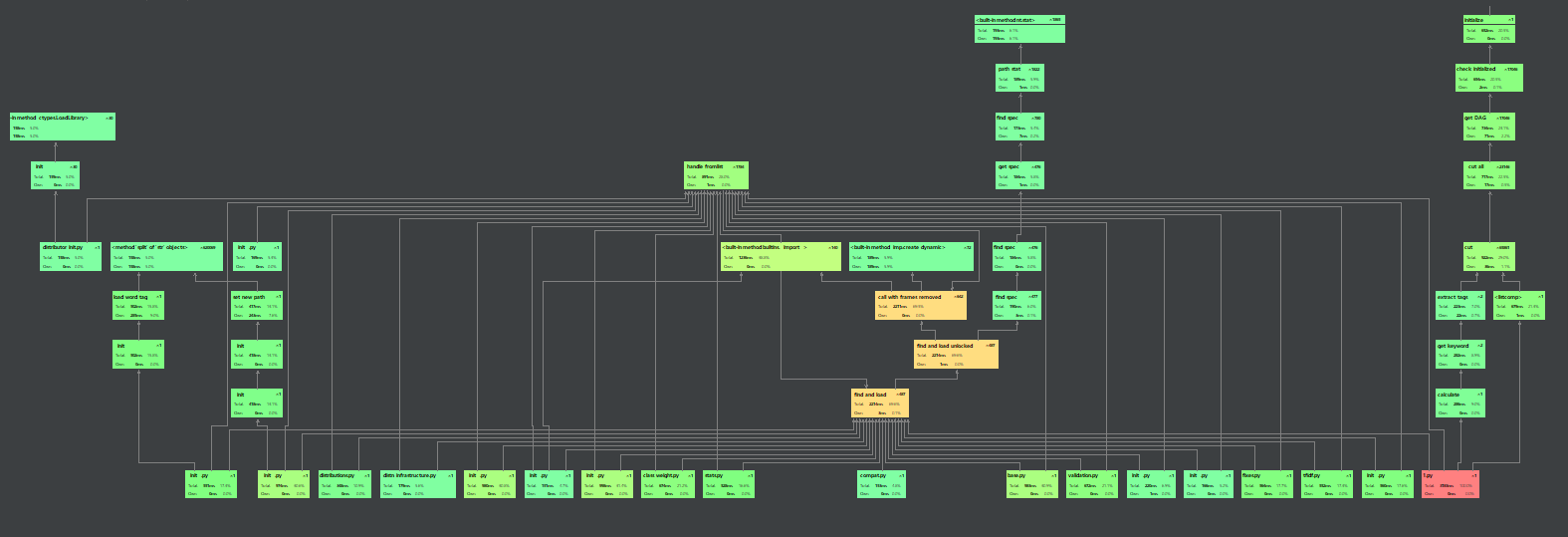
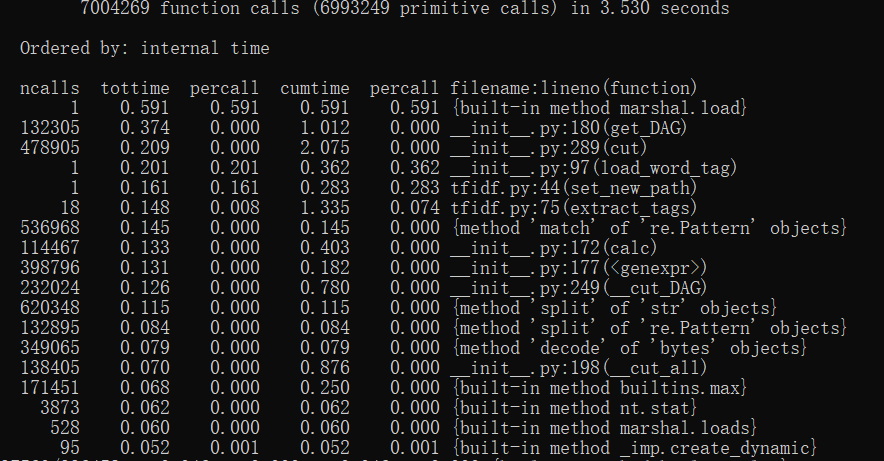
利用Python的profile工具进行分析,分析完两篇文章的总时间是3.53s,其中耗时最大的是在jieba分词这一块,因为是调用第三方库,所以但从算法的角度不太懂得怎么优化,可能开个多线程速度会快一点。哦,还有,我的余弦相似度算法为图省事直接调用的sklearn的cosine_similarity,这个函数会计算输入的n个向量两两之间的相似度,因为这道题是两篇文章对比,所以时间上的差距可能不是很大,但是自己写个函数可能会快一点。
- 消耗内存分析
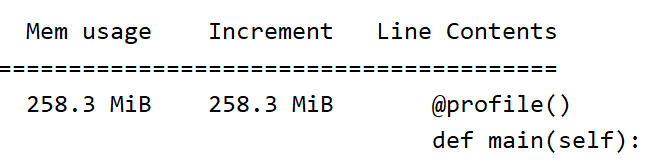
这里用了Python的memory_profiler和psutil库进行内存分析,因为是对文章进行分词并转为向量所以内存的消耗还是比较大的。其中内存消耗最大的模块是:
@staticmethod
def extract_keyword(content): # 提取关键词
# 切割
seg = [i for i in jieba.cut(content, cut_all=True) if i != '']
# 提取关键词
keywords = jieba.analyse.extract_tags("|".join(seg), topK=topK, withWeight=False)
return keywords
计算模块单元测试展示
-
测试代码
root = "sim_0.8"
fileName = os.listdir(root) # 得到当前目录下所有的文件名
with open(root+'\'+fileName[0],encoding='UTF-8') as fp:
ori = fp.read()
# print("len article = ",len(ori))
seg = [i for i in jieba.cut(ori, cut_all=True) if i != '']
topK = int(len(seg)/9)
processText(ori)
for i in range(1,10):
with open(root+'\'+fileName[i],encoding='UTF-8') as fp:
copy = fp.read()
processText(copy)
similarity = CosineSimilarity(ori,copy)
similarity = similarity.calculate()
print(fileName[i] + ' 相似度: %.2f%%' % (similarity*100))
-
测试代码构建思路
测试代码在本地完成,读取文件夹下的所有文件名,接着读入原文和修改过的文章,创建一个CosineSimilarity对象,调用对象的calculate方法,最后对结果保留两位小数并写入输出文件。
测试数据采用群里提供的9个文件,这9个文件包括了大部分查重情况。
-
测试结果
orig_0.8_add.txt 相似度: 81.00%
orig_0.8_del.txt 相似度: 70.50%
orig_0.8_dis_1.txt 相似度: 89.00%
orig_0.8_dis_10.txt 相似度: 75.00%
orig_0.8_dis_15.txt 相似度: 58.50%
orig_0.8_dis_3.txt 相似度: 86.50%
orig_0.8_dis_7.txt 相似度: 82.50%
orig_0.8_mix.txt 相似度: 80.50%
orig_0.8_rep.txt 相似度: 70.50%
从测试结果可以看出这个算法的准确度还算可以,但是感觉会偏低一点
-
测试二
利用两段相同的文本进行分析
原文
矛盾分析法是唯物辩证法的核心,唯物辩证法包括很多规律和范畴,其中,对立统一规律是其核心,在《矛盾论》的开头,事物的矛盾法则,即对立统一的法则,是唯物辩证法的最根本的法则。因而,掌握了矛盾分析法,我们就能更好地理解唯物辩证法的其他内容。
修改后
矛盾分析法是唯物辩证法的核心,唯物辩证法包括很多规律和范畴,其中,对立统一规律是其核心,在《矛盾论》的开头,事物的矛盾法则,即对立统一的法则,是唯物辩证法的最根本的法则。因而,掌握了矛盾分析法,我们就能更好地理解唯物辩证法的其他内容。
测试结果
相似度 100.00%
-
单元测试代码
class Test(unittest.TestCase):
def test1(self):
"改动0.8的文本"
with open("sim_0.8orig.txt",encoding="utf-8") as fp:
ori = fp.read()
with open("sim_0.8orig_0.8_add.txt",encoding="utf-8") as fp:
copy = fp.read()
model = CosineSimilarity(ori,copy)
ans = model.calculate()
self.assertEqual(round(ans,2), 0.8)
def test2(self):
"相同文本"
with open("sim_0.8orig.txt",encoding="utf-8") as fp:
ori = fp.read()
with open("sim_0.8orig.txt",encoding="utf-8") as fp:
copy = fp.read()
model = CosineSimilarity(ori,copy)
ans = model.calculate()
self.assertEqual(round(ans,2), 1.0)
def test3(self):
"空文本"
with open("sim_0.8orig.txt",encoding="utf-8") as fp:
ori = fp.read()
with open("sim_0.8empty.txt",encoding="utf-8") as fp:
copy = fp.read()
model = CosineSimilarity(ori,copy)
ans = model.calculate()
self.assertEqual(ans, 0.0)
if __name__ == '__main__':
unittest.main()
-
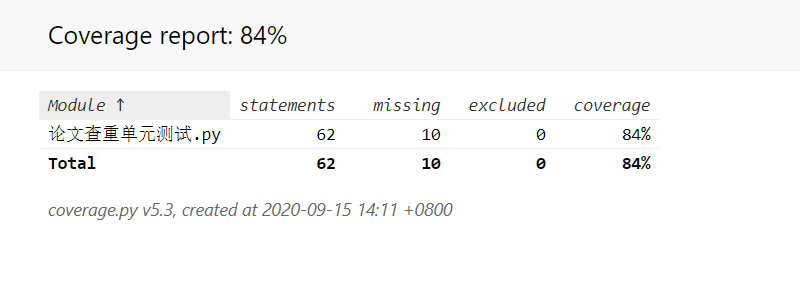
单元测试覆盖率
计算模块部分异常处理说明
- IO流异常
try:
with open(path,encoding='UTF-8') as fp:
ori = fp.read()
except:
print("路径错误")

当路径名有错时,可能无法打开文件,产生异常
- 除0异常
try:
sim = cosine_similarity(sample)
return sim[1][0]
except Exception as e:
print(e)
return 0.0
在计算两个向量的余弦值时,当输入的文本为空时,分母有可能为0,会产生异常

小结
这次作业最主要的收获是学会了用Git进行上传和下载项目和如何搭建一个项目的完整性,比如前期工作,性能分析,测试数据等,特别是单元测试,这在以前是根本不会去做的。在这之中体会到了代码不是最主要的,大部分的时间都在处理其他的事,比如写博客,学习新技术等,真正编码的时间只占了一小部分。同时,这次作业还提高了查找和收集资料的能力。