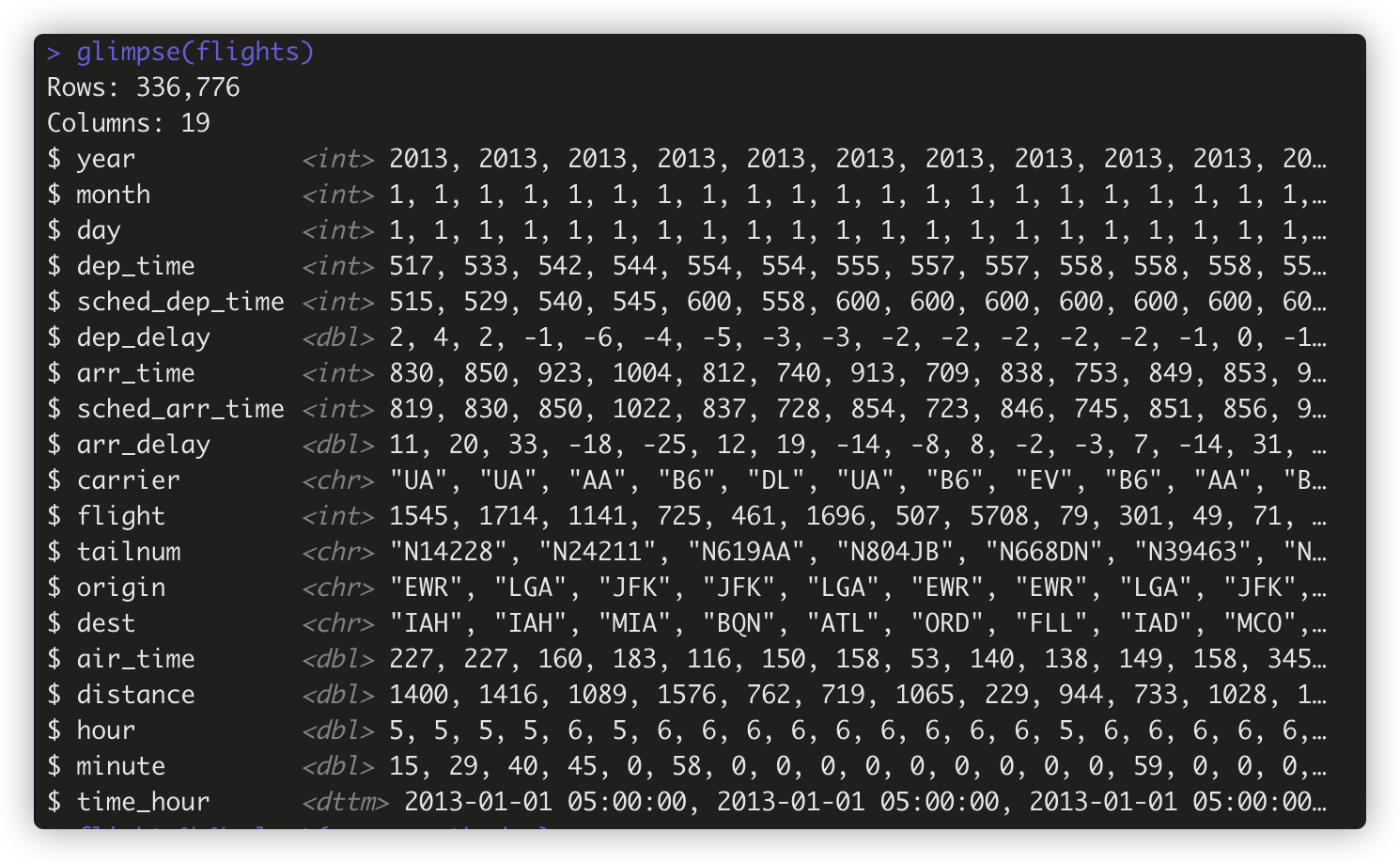
$dataframe %>%select($var1,$var2,$var3) #列名,但建议用这种。
$dataframe %>%select($index1,$index2,$index3) #列的位置
上述等效,但建议用列名选择。
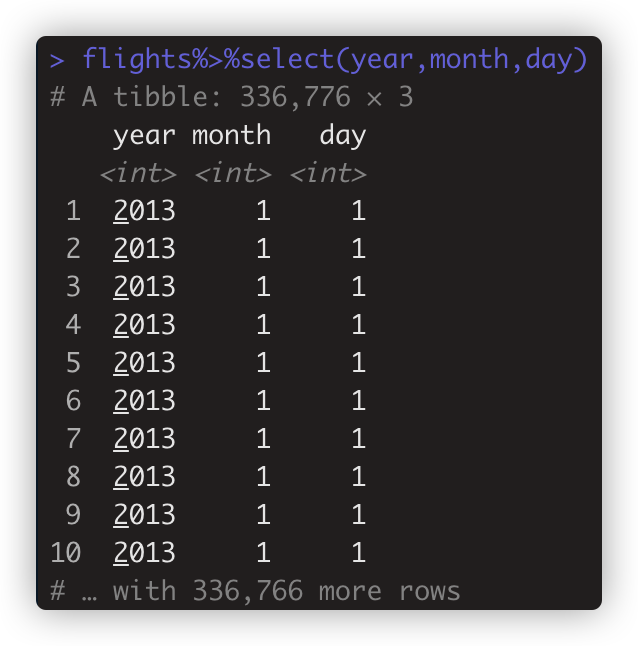
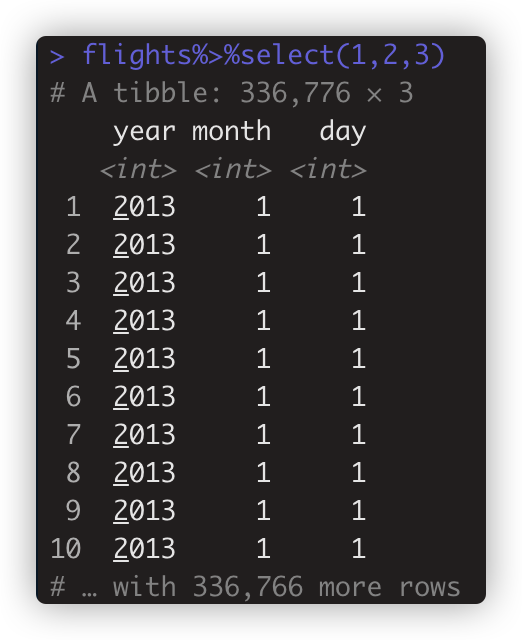
- 如flights%>%select(year,month,day) #第1、2、3列 与flights%>%select(1,2,3)一致。
- select内这是多个条件时也表示取并集,“或”关系。
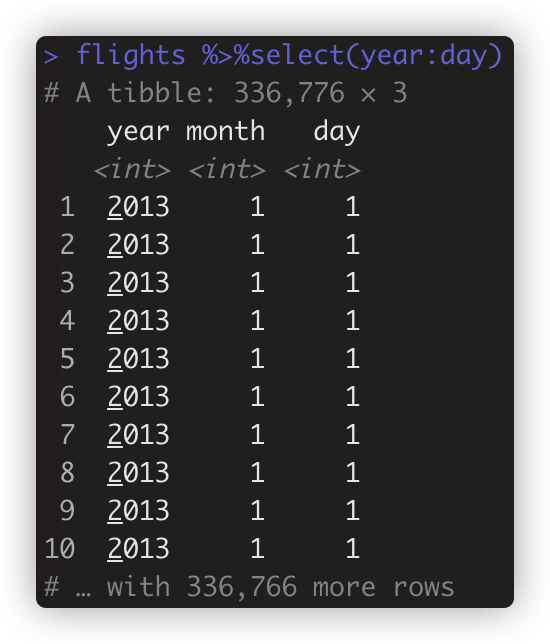
- flights %>%select(year:day) 选择两个列变量之间的所有列,冒号
-
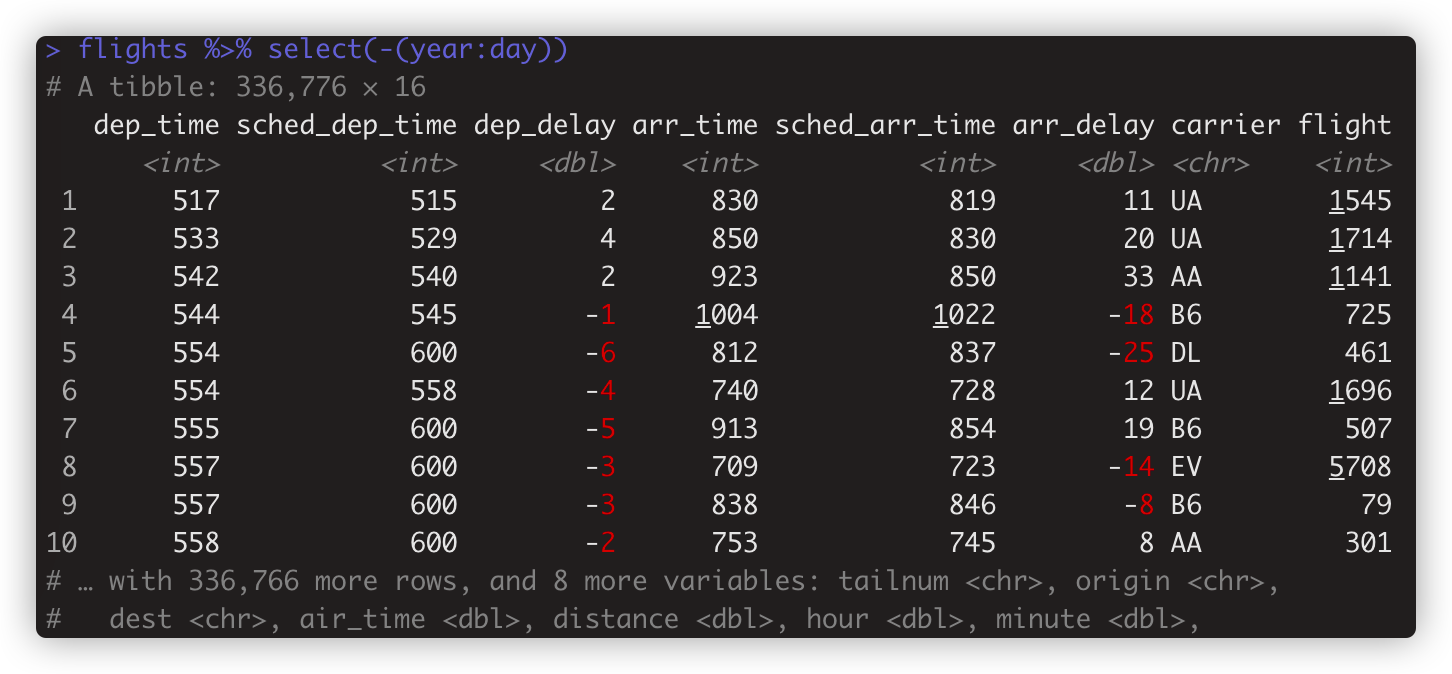
flights %>% select(-(year:day)) 选择不在列变量区间的所有列。
-
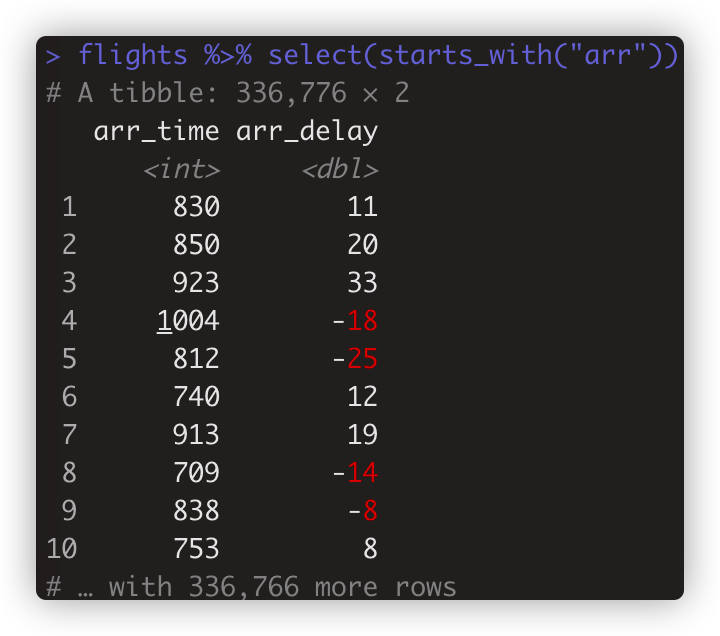
flights %>% select(starts_with("arr")) 匹配以“arr”开头的列。
-
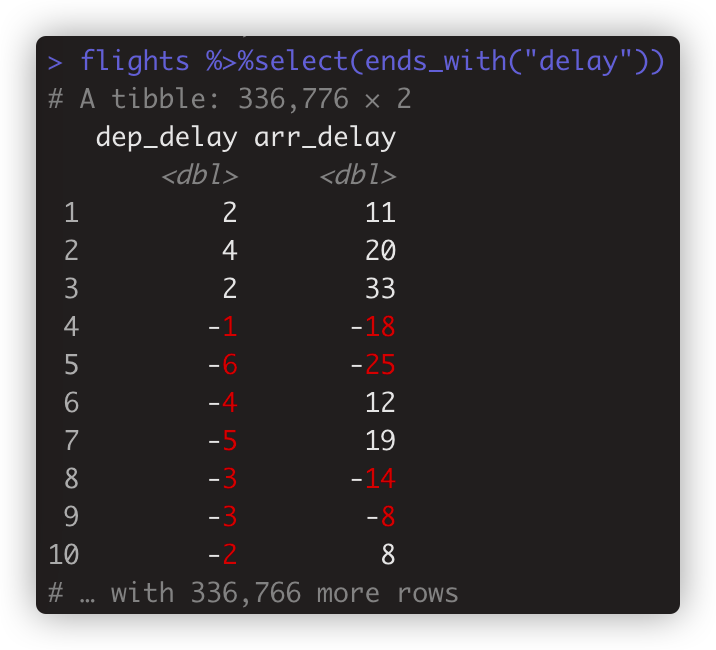
flights %>%select(ends_with("delay")) 匹配以“delay”结尾的列
-
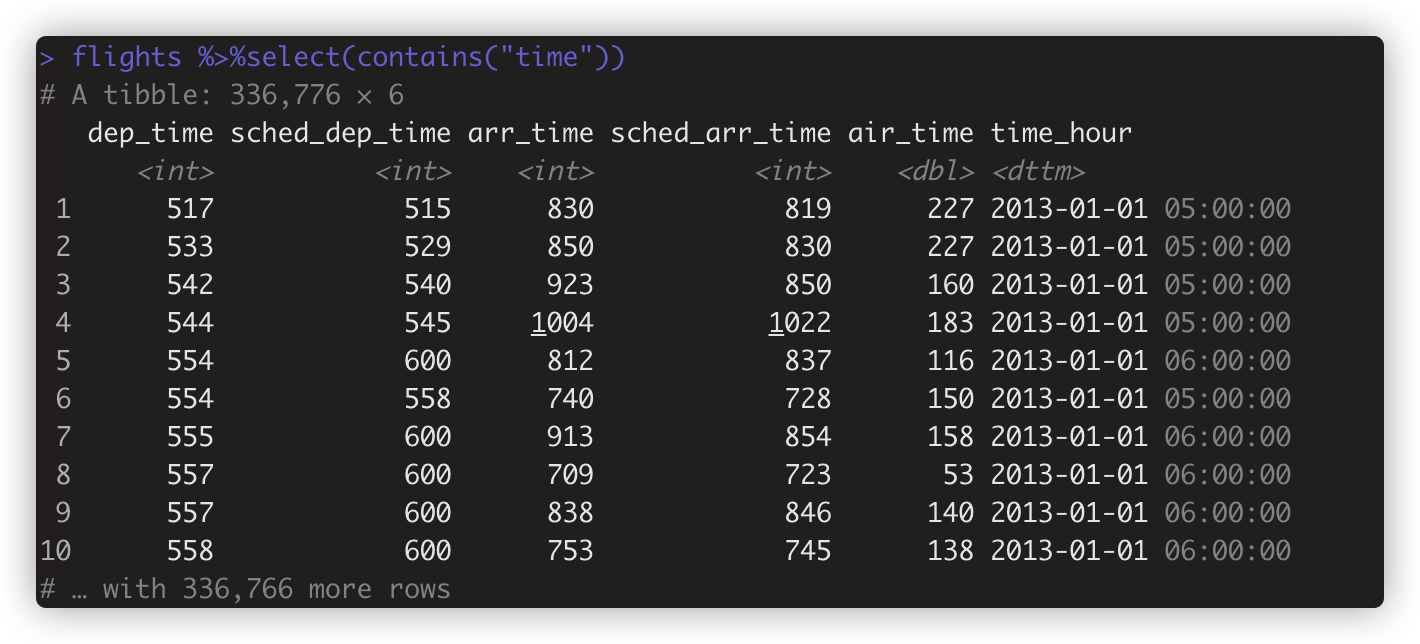
flights %>%select(contains("time")) 匹配变量名包含“time”字段的列
-
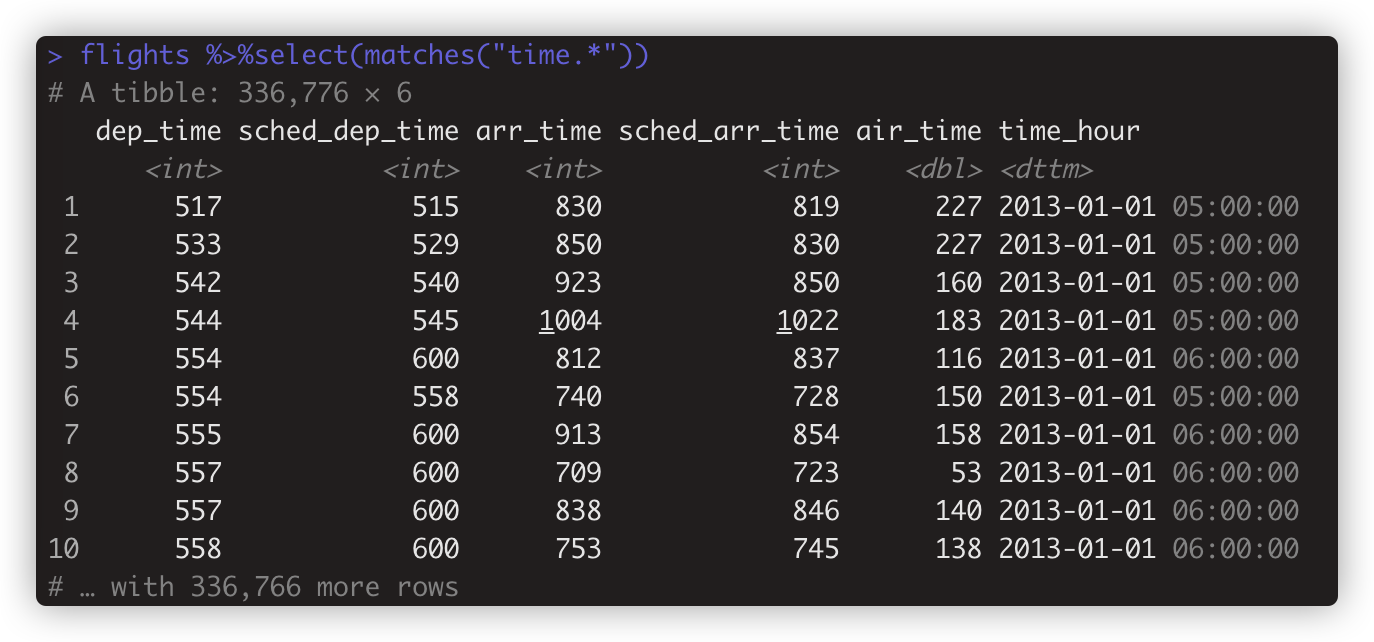
flights %>%select(matches("time.*")) 列变量名匹配matches正则表达式
-
df %>% select(num_range("x",1:3)) 选择列名为 x1,x2,x3

-
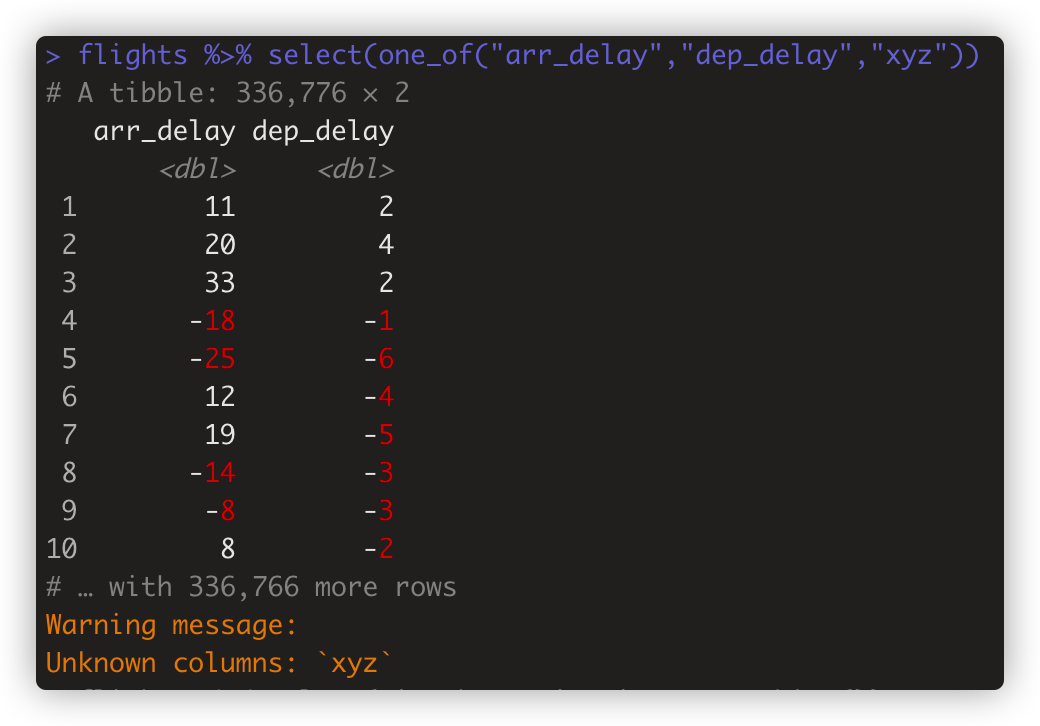
flights %>% select(one_of("arr_delay","dep_delay","xyz")) 选择列名属于这个序列中的列
-
等效: 先定义如vars<-c("arr_delay","dep_delay","xyz") 然后 flights %>% select(one_of(vars))
-
- everything() 匹配所有剩余变量,用于将某些变量移动数据集开头的场景下
-
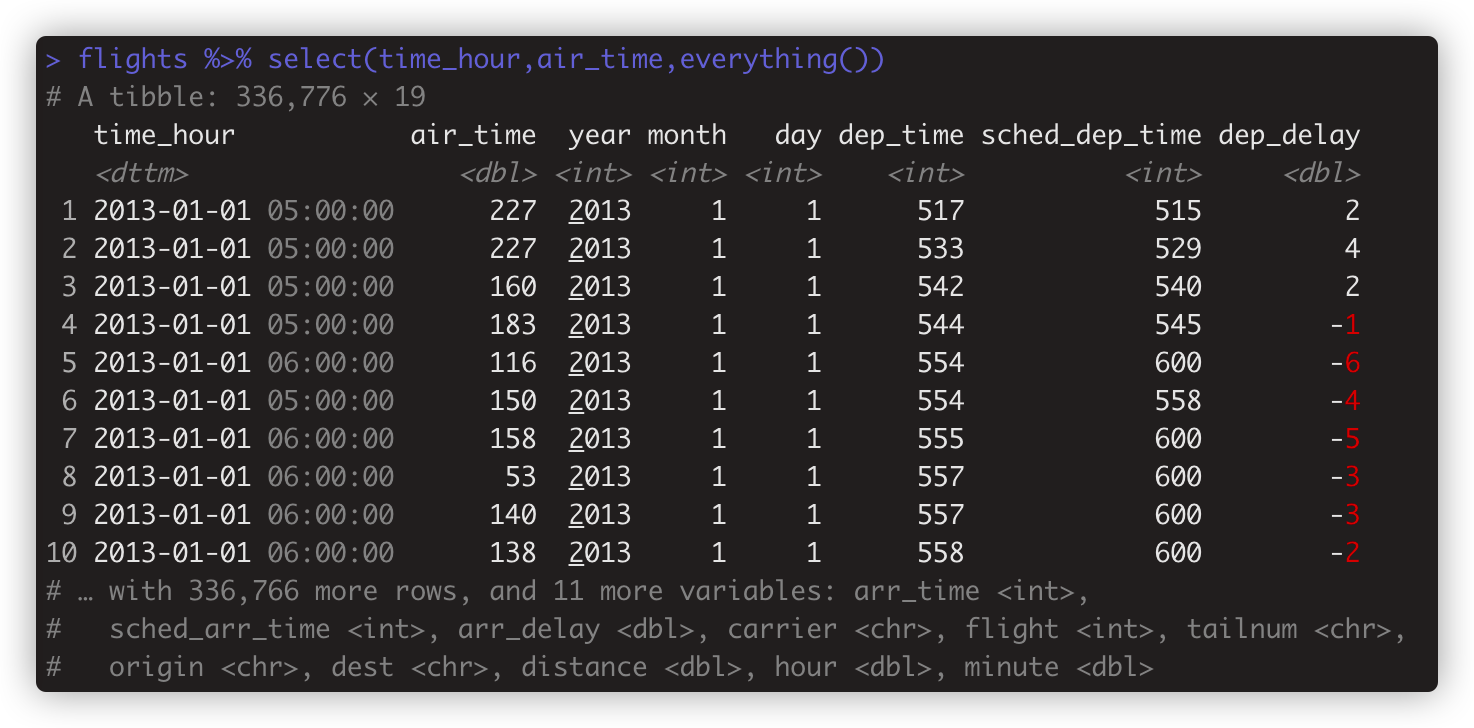
flights %>% select(time_hour,air_time,everything()) #把time_hour,air_time两个变量列移动数据集开头,其他列跟在后面。
-
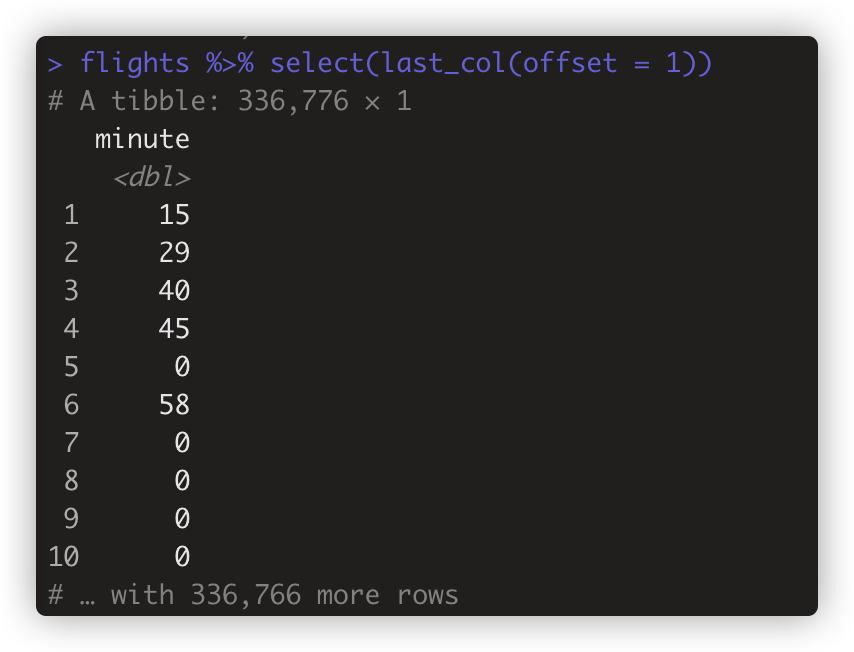
last_col(offset=n),取倒数第几列。不设置offset或设置为0时是最后一列。如flights %>% select(last_col(offset = 1)) #取倒数第二列
-
select 内可以设置多个条件,用逗号分隔,“或” 的关系。如flights %>% select(starts_with("arr"),ends_with("time")) #取以arr开头或time结尾的列名
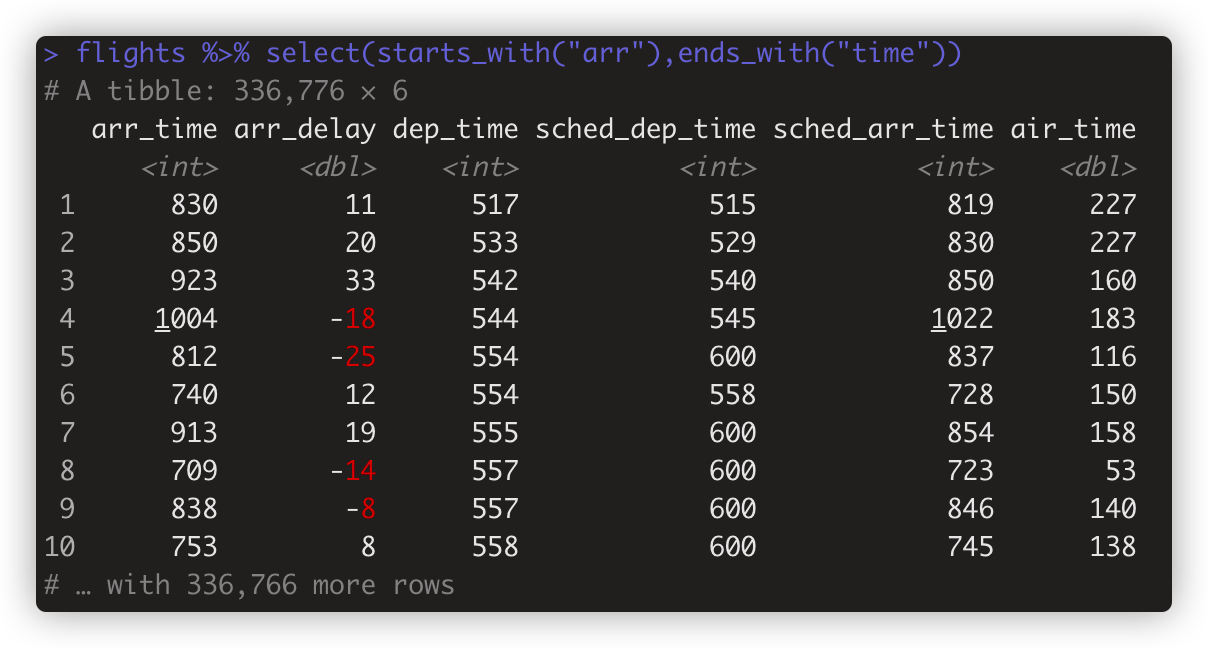
- 注意:
- starts_with,ends_with,contains,matches 这四个函数有ignore_case参数,默认是TRUE,是忽略大小写的,需要识别得话设为FASLE.
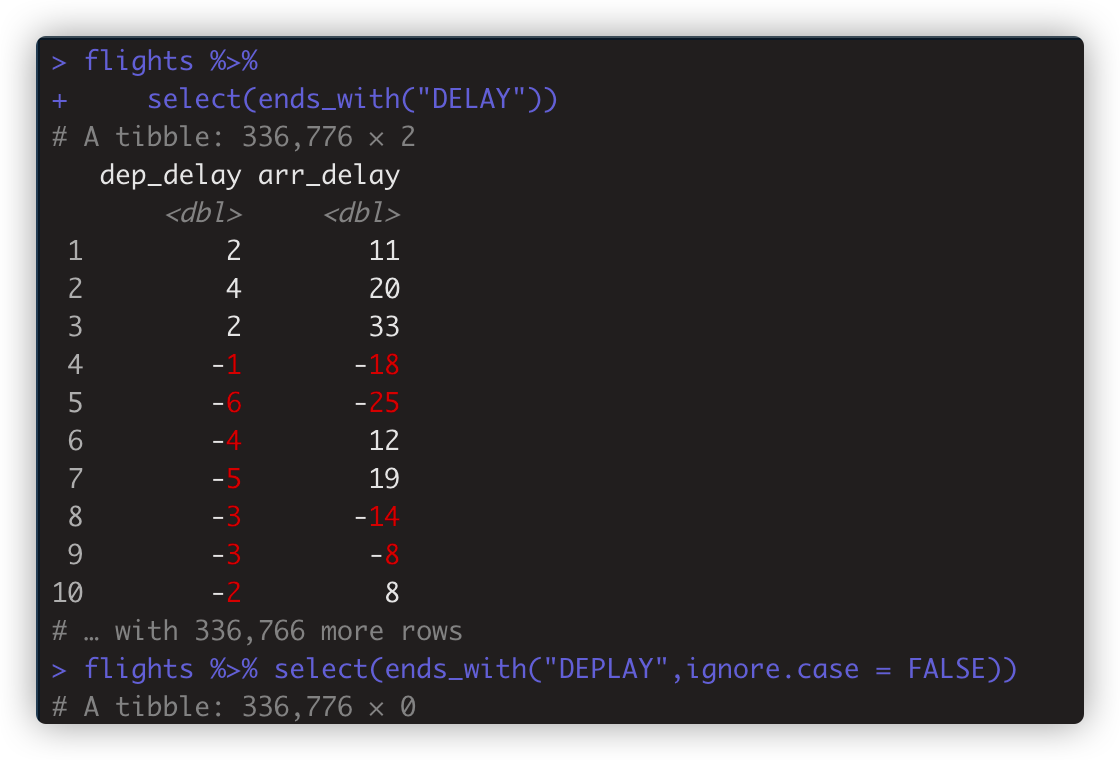
-
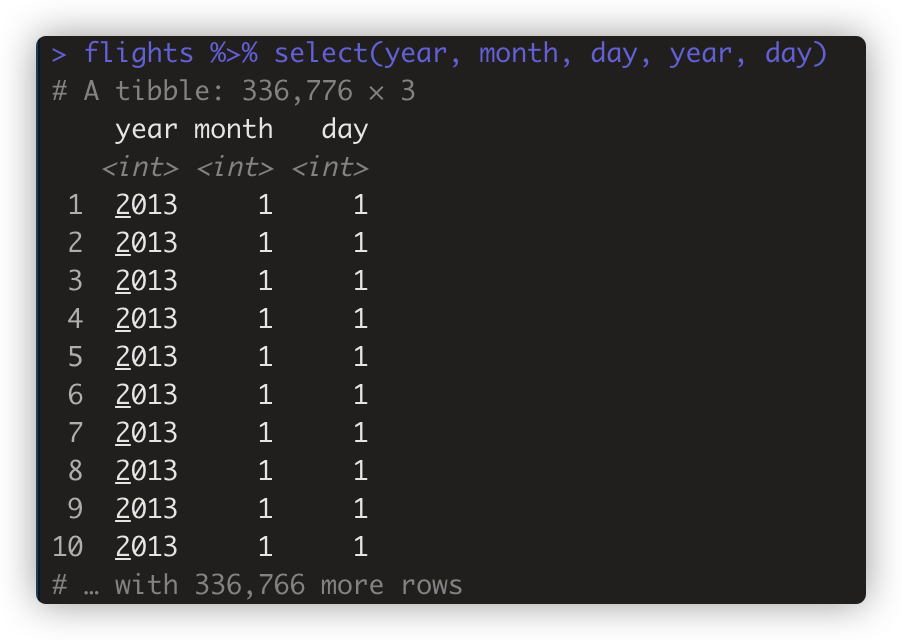
select多次选择同一变量名时只选择一次。如 flights %>% select(year, month, day, year, day)
-
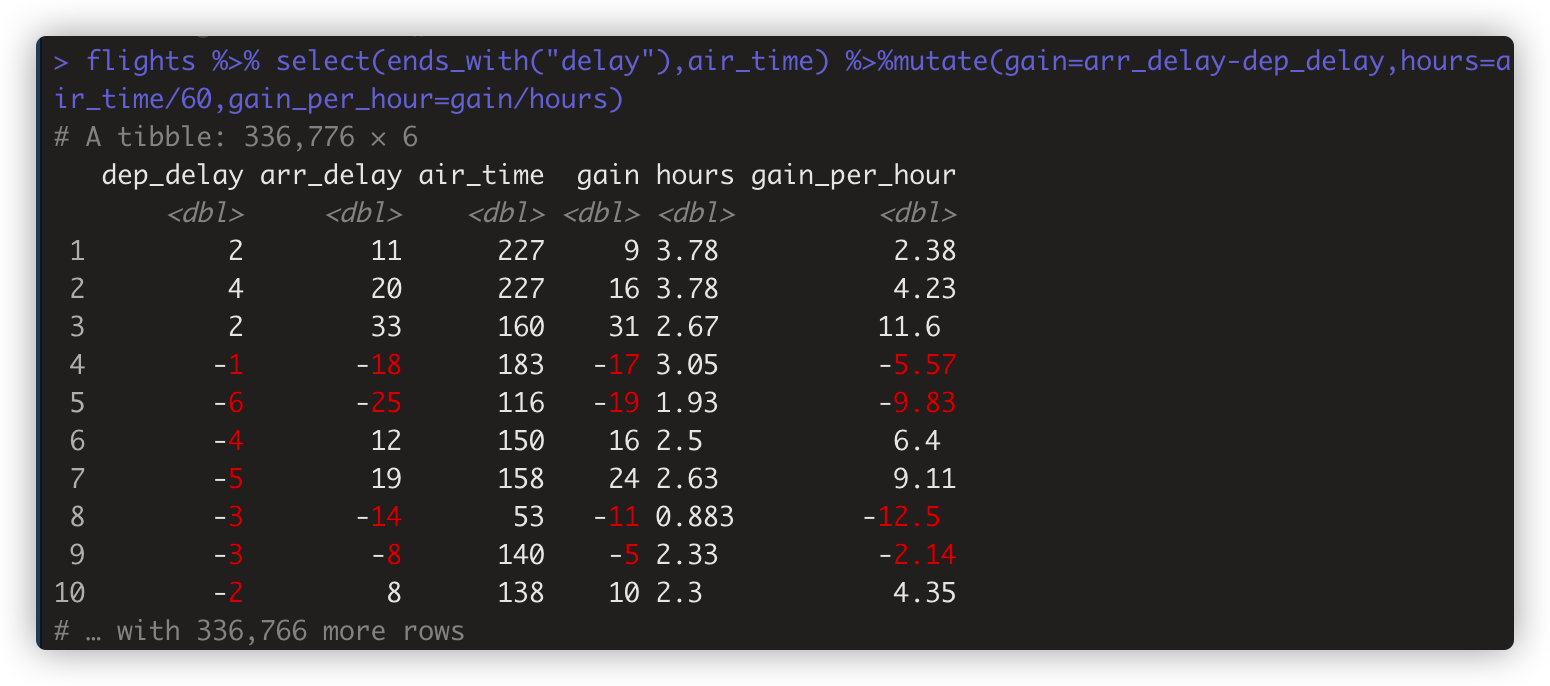
- select()搭配mutate()选择列,然后增加新列。mutate新列变量一经创建,就可以立即使用。如:
- flights %>% select(ends_with("delay"),air_time) %>% mutate(gain=arr_delay-dep_delay,hours=air_time/60,gain_per_hour=gain/hours)
-
-
-
如果只保留新变量,则用transmute() 如:flights %>% select(ends_with("delay"),air_time) %>%transmute(gain=arr_delay-dep_delay,hours=air_time/60,gain_per_hour=gain/hours)
-
- 用rname()重命名列名(变量名) 如rename(flights,tail_num=tailnum) # 将数据框flights中的原tail_num列变量重命名为tailnum,其他列不改动。