1、关联规则挖掘算法
关联规则挖掘算法可以实现从两种经典算法Apriori或FP-Growth中任意选取算法,输出各个频繁项集和强关联规则。输入文件由本地导入,可自行设置最小支持度计数和最小置信度参数值。
2、 Apriori算法设计思想
Apriori算法本质上使用一种称作逐层搜索的迭代方法,使用候选项集找频繁项集,其特点在于每找一次频繁项集就需要扫描一次数据库。
3、FP-growth算法设计思想
FP-growth算法将数据集存储在一个特定的称作FP树的结构,只需要遍历数据集2次,就能够完成频繁模式发现,其发现频繁项集的分为两个阶段,第一个阶是段构建FP树,第二个阶段从FP树中挖掘频繁项集。
4、用户界面
1)点击读取文件按钮,读取的文件时,如图4-1所示:
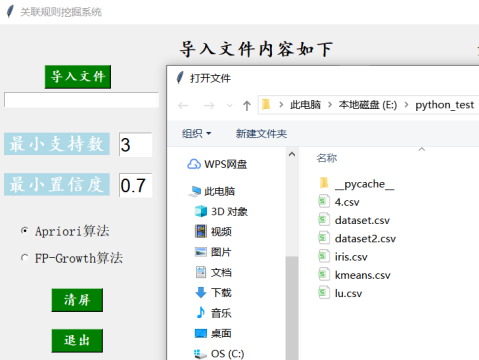
图4-1 关联规则挖掘系统导入文件
2)选择Apriori算法,单击按钮,读取的文件并运行,运行结果如图5-2所示:
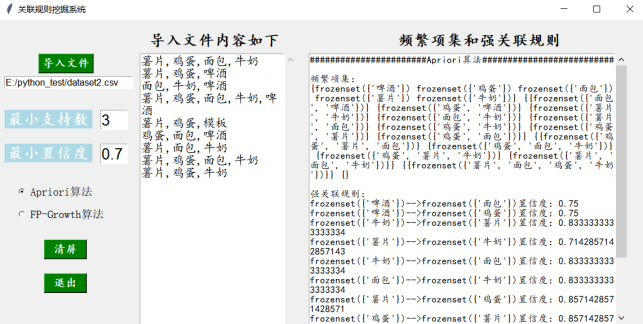
图4-2 关联规则挖掘系统的Apriori算法实现
3)在2)的基础上,单击“清屏”按钮,修改最小支持度和最小置信度,单击“Apriori算法”再次运行,运行结果如图5-3所示:
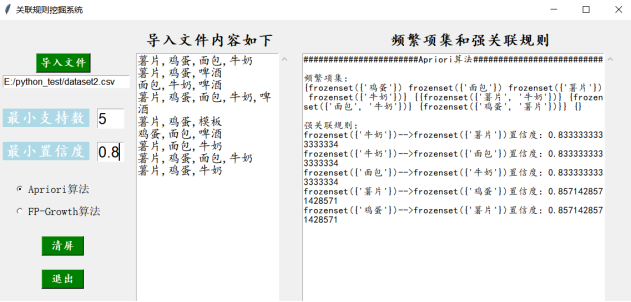
图4-3 关联规则挖掘系统的Apriori算法修改参数实现
4)选择FP-Growth算法,单击按钮,读取的文件并运行,运行结果如图5-4所示:

图4-4 关联规则挖掘系统的FP-Growth算法实现
5)在4)的基础上,单击“清屏”按钮,如图4-5修改最小支持度和最小置信度,单击“FP-Growth算法”再次运行,运行结果如图4-6所示:
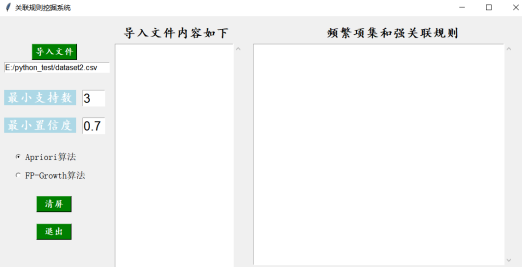
图4-5关联规则挖掘系统的清屏

图4-6关联规则挖掘系统的FP-Growth算法修改参数实现
6)点击“退出”,实现控制台清空和系统退出,如图4-7所示:
图4-7 关联规则挖掘系统的退出
5、实验源码
编译环境为Spyder,所用语言及版本为python3.7,GUI环境为tkinter。
1)主运行界面 GUI.py
# -*- coding: utf-8 -*-
import sys
import fp
import tkinter as tk
from tkinter import filedialog
from tkinter import scrolledtext
class GUI(object):
#布局界面
def __init__(self):
#设置初始界面
self.window=tk.Tk()
self.window.title('关联规则挖掘系统')
self.window.geometry('1150x550')
#导入文件按钮
self.botton1=tk.Button(self.window, text='导入文件',bg='green',fg='white', font=('楷体', 12, 'bold'), width=8, height=1,command=self.openfile)
self.botton1.place(x=70,y=60)
#标签配置
self.label2=tk.Label(self.window, text='最小支持数',bg='light blue',fg='white', font=('楷体', 16, 'bold'), width=10, height=1).place(x=10,y=160)
self.label3=tk.Label(self.window, text='最小置信度',bg='light blue',fg='white', font=('楷体', 16, 'bold'), width=10, height=1).place(x=10,y=220)
#导入文件内容的输出显示
self.label4=tk.Label(self.window, text='导入文件内容如下',font=('楷体', 16, 'bold'), width=16, height=1).place(x=260,y=20)
#创建结果显示框
self.text1=scrolledtext.ScrolledText(self.window, height=28, width=23,font=('楷体', 13))
self.text1.place(x=250,y=60)
self.text1.bind("<Button-1>",self.clear)
#各个频繁项集和强关联规则的输出显示
self.label5=tk.Label(self.window, text='频繁项集和强关联规则',font=('楷体', 16, 'bold'), width=20, height=1).place(x=700,y=20)
#创建结果显示框
self.text2=scrolledtext.ScrolledText(self.window, height=28, width=60,font=('楷体', 10))
self.text2.place(x=550,y=60)
self.text2.bind("<Button-1>",self.clear)
# self.text2.bind("<Button-1>",self.run)
#显示导入文件的路径
self.var0=tk.StringVar()
self.entry1=tk.Entry(self.window, show=None, width='25', font=('Arial', 10), textvariable=self.var0)
self.entry1.place(x=10,y=100)
#自行设置最小支持度计数值,默认为0.5
self.var1=tk.StringVar()
self.var1.set('3')
self.entry2=tk.Entry(self.window, show=None, width='3', font=('Arial', 16), textvariable=self.var1)
self.entry2.place(x=180,y=160)
#自行设置最小置信度参数值,默认为0.7
self.var2=tk.StringVar()
self.var2.set('0.7')
self.entry3=tk.Entry(self.window, show=None, width='3', font=('Arial', 16), textvariable=self.var2)
self.entry3.place(x=180,y=220)
#选择所需算法
self.btnlist=tk.IntVar()
self.radiobtn1=tk.Radiobutton(self.window, variable=self.btnlist, value=0, text='Apriori算法', font=('bold'), command=self.runApriori)
self.radiobtn1.place(x=30,y=290)
self.radiobtn2=tk.Radiobutton(self.window, variable=self.btnlist, value=1,text='FP-Growth算法', font=('bold'), command=self.runFPGrowth)
self.radiobtn2.place(x=30,y=330)
self.btnlist.set(0)
#开始运行按钮
# self.btn1=tk.Button(self.window, bg='green',fg='white', text='运行', font=('楷体', 12,'bold'), width=6, height=1, command=self.run)
# self.btn1.place(x=80,y=360)
#清空页面按钮
self.btn2=tk.Button(self.window, bg='green',fg='white', text='清屏', font=('楷体', 12,'bold'), width=6, height=1)
self.btn2.place(x=80,y=390)
self.btn2.bind("<Button-1>",self.clear)
#关闭页面按钮
self.btn3=tk.Button(self.window, bg='green',fg='white', text='退出', font=('楷体', 12,'bold'), width=6, height=1)
self.btn3.place(x=80,y=450)
self.btn3.bind("<Button-1>",self.close)
#主窗口循环显示
self.window.mainloop()
#清空所填内容
def clear(self,event):
# 连同导入文件一起删除的话,会影响操作的连贯性,故注释掉
# self.entry1.delete(0,tk.END)
# self.entry2.delete(0,tk.END)
# self.entry3.delete(0,tk.END)
self.text1.delete("1.0",tk.END)
self.text2.delete("1.0",tk.END)
#退出系统,对控制台清屏
def close(self,event):
e=tk.messagebox.askokcancel('询问','确定退出系统吗?')
if e==True:
exit()
self.window.destroy()
def __del__(self):
# 恢复sys.stdout
sys.stdout = sys.__stdout__
sys.stderr = sys.__stderr__
#从输入文本框中获取文本并返回数字列表
def getDataSupport(self):
entry_num1 = float(self.var1.get())
return entry_num1
def getDataConfidence(self):
entry_num2 =float(self.var2.get())
return entry_num2
def openfile(self):
nameFile = filedialog.askopenfilename(title='打开文件', filetypes=[('csv', '*.csv'),('txt', '*.txt')])
self.entry1.insert('insert', nameFile)
def getnamefile(self):
namefile=self.var0.get()
return namefile
#读取导入的文件并转化为列表
def loadDataSet(self):
nameFile=self.getnamefile()
with open(nameFile,"r",encoding='utf-8') as myfile:
data=myfile.read()
self.text1.insert("0.0",data)
self.text1.see("end")
list_result=data.split("
")# 以回车符
分割成单独的行
length=len(list_result)
for i in range(length):
list_result[i]=list_result[i].split(",") # csv文件中的元素是以逗号分隔的
return list_result
def runApriori(self):
loadDataSet = self.loadDataSet()
C1=self.createC1(loadDataSet)
D = list(map(set,loadDataSet))
minSupport = self.getDataSupport()
L1, suppData0 = self.scanD(D,C1,minSupport)
L,suppData = self.apriori(loadDataSet,minSupport)
minConf = self.getDataConfidence()
rules = self.generateRules(L,suppData,minConf)
s='#######################Apriori算法##########################
'
self.text2.insert('insert',s)
t1='
频繁项集:
'
self.text2.insert('insert',t1)
self.text2.insert('insert',L)
t2='
强关联规则:
'
self.text2.insert('insert',t2)
for line in rules:
r =str(line[0]) + '-->' + str(line[1]) + '置信度:' + str(line[2]) + '
'
self.text2.insert('insert',r)
def runFPGrowth(self):
dataSet = self.loadDataSet()
frozenDataSet = fp.transfer2FrozenDataSet(dataSet)
minSupport = self.getDataSupport()
s='#######################FP_Growth算法########################
'
self.text2.insert('insert',s)
t='
FP树:
'
self.text2.insert('insert',t)
fptree, headPointTable = fp.createFPTree(frozenDataSet, minSupport)
fptree.disp()
self.text2.insert('insert',fptree.display())
frequentPatterns = {}
prefix = set([])
fp.mineFPTree(headPointTable, prefix, frequentPatterns, minSupport)
t1='
频繁项集:
'
self.text2.insert('insert',t1)
t2=frequentPatterns
self.text2.insert('insert',t2)
minConf = self.getDataConfidence()
rules = []
fp.rulesGenerator(frequentPatterns, minConf, rules)
t3='
强关联规则:
'
self.text2.insert('insert',t3)
for line in rules:
r =str(line[0]) + '-->' + str(line[1]) + '置信度:' + str(line[2]) + '
'
self.text2.insert('insert',r)
#创建集合C1,C1是大小为1的所有候选项集合
def createC1(self,dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset,C1)) #对C1中每个项构建一个不变集合
#扫描数据集,返回最频繁项集的支持度supportData
def scanD(self,D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if can not in ssCnt:
ssCnt[can] = 1
else:
ssCnt[can] += 1
# numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
# support = ssCnt[key] / numItems #计算所有项集支持度
support = ssCnt[key]
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
#创建候选项集Ck
def aprioriGen(self,Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):#前k-2个项相同时,将两个集合合并
for j in range(i + 1, lenLk):
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList
#Apriori算法函数
def apriori(self,dataSet, minSupport):
minSupport = self.getDataSupport()
C1 = self.createC1(dataSet)
D = list(map(set, dataSet))
L1, supportData = self.scanD(D, C1, minSupport)
L = [L1]
k = 2
while (len(L[k - 2]) > 0):
Ck = self.aprioriGen(L[k - 2], k)
Lk, supK = self.scanD(D, Ck, minSupport)#扫描数据集,从Ck得到Lk
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
#生成关联规则
def generateRules(self,L, supportData, minConf):
minConf = self.getDataConfidence()
bigRuleList = []
for i in range(1, len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
self.rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
self.calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
#计算可信度值
def calcConf(self,freqSet, H, supportData, brl, minConf):
minConf = self.getDataConfidence()
prunedH = []
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf >= minConf:
# print (freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
#从最初的项集中生成更多的关联规则
def rulesFromConseq(self,freqSet, H, supportData, brl, minConf):
minConf = self.getDataConfidence()
m = len(H[0])
if (len(freqSet) > (m + 1)):
Hmp1 = self.aprioriGen(H, m+1)
Hmp1 = self.calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1):
self.rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
if __name__ == '__main__':
GUI()
2)导入的fp.py
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 24 10:48:56 2019
@author: 29493
"""
#import GUI
def transfer2FrozenDataSet(dataSet):
frozenDataSet = {}
for elem in dataSet:
frozenDataSet[frozenset(elem)] = 1
return frozenDataSet
res1=[]
res2=[]
res3=[]
class TreeNode:
def __init__(self, nodeName, count, nodeParent):
self.nodeName = nodeName
self.count = count
self.nodeParent = nodeParent
self.nextSimilarItem = None
self.children = {}
def increaseC(self, count):
self.count += count
def disp(self, ind=1):
res1.append(self.nodeName)
res2.append(self.count)
res3.append(ind)
for child in self.children.values():
child.disp(ind + 1)
def display(self):
s=''
for i in range(0,len(res1)):
s+=' ' * res3[i]+res1[i]+' '+str(res2[i])+'
'
return s
def createFPTree(frozenDataSet, minSupport):
#scan dataset at the first time, filter out items which are less than minSupport
headPointTable = {}
for items in frozenDataSet:
for item in items:
headPointTable[item] = headPointTable.get(item, 0) + frozenDataSet[items]
headPointTable = {k:v for k,v in headPointTable.items() if v >= minSupport}
frequentItems = set(headPointTable.keys())
if len(frequentItems) == 0: return None, None
for k in headPointTable:
headPointTable[k] = [headPointTable[k], None]
fptree = TreeNode("null", 1, None)
#scan dataset at the second time, filter out items for each record
for items,count in frozenDataSet.items():
frequentItemsInRecord = {}
for item in items:
if item in frequentItems:
frequentItemsInRecord[item] = headPointTable[item][0]
if len(frequentItemsInRecord) > 0:
orderedFrequentItems = [v[0] for v in sorted(frequentItemsInRecord.items(), key=lambda v:v[1], reverse = True)]
updateFPTree(fptree, orderedFrequentItems, headPointTable, count)
return fptree, headPointTable
def updateFPTree(fptree, orderedFrequentItems, headPointTable, count):
#handle the first item
if orderedFrequentItems[0] in fptree.children:
fptree.children[orderedFrequentItems[0]].increaseC(count)
else:
fptree.children[orderedFrequentItems[0]] = TreeNode(orderedFrequentItems[0], count, fptree)
#update headPointTable
if headPointTable[orderedFrequentItems[0]][1] == None:
headPointTable[orderedFrequentItems[0]][1] = fptree.children[orderedFrequentItems[0]]
else:
updateHeadPointTable(headPointTable[orderedFrequentItems[0]][1], fptree.children[orderedFrequentItems[0]])
#handle other items except the first item
if(len(orderedFrequentItems) > 1):
updateFPTree(fptree.children[orderedFrequentItems[0]], orderedFrequentItems[1::], headPointTable, count)
def updateHeadPointTable(headPointBeginNode, targetNode):
while(headPointBeginNode.nextSimilarItem != None):
headPointBeginNode = headPointBeginNode.nextSimilarItem
headPointBeginNode.nextSimilarItem = targetNode
def mineFPTree(headPointTable, prefix, frequentPatterns, minSupport):
#for each item in headPointTable, find conditional prefix path, create conditional fptree, then iterate until there is only one element in conditional fptree
headPointItems = [v[0] for v in sorted(headPointTable.items(), key = lambda v:v[1][0])]
if(len(headPointItems) == 0): return
for headPointItem in headPointItems:
newPrefix = prefix.copy()
newPrefix.add(headPointItem)
support = headPointTable[headPointItem][0]
frequentPatterns[frozenset(newPrefix)] = support
prefixPath = getPrefixPath(headPointTable, headPointItem)
if(prefixPath != {}):
conditionalFPtree, conditionalHeadPointTable = createFPTree(prefixPath, minSupport)
if conditionalHeadPointTable != None:
mineFPTree(conditionalHeadPointTable, newPrefix, frequentPatterns, minSupport)
def getPrefixPath(headPointTable, headPointItem):
prefixPath = {}
beginNode = headPointTable[headPointItem][1]
prefixs = ascendTree(beginNode)
if((prefixs != [])):
prefixPath[frozenset(prefixs)] = beginNode.count
while(beginNode.nextSimilarItem != None):
beginNode = beginNode.nextSimilarItem
prefixs = ascendTree(beginNode)
if (prefixs != []):
prefixPath[frozenset(prefixs)] = beginNode.count
return prefixPath
def ascendTree(treeNode):
prefixs = []
while((treeNode.nodeParent != None) and (treeNode.nodeParent.nodeName != 'null')):
treeNode = treeNode.nodeParent
prefixs.append(treeNode.nodeName)
return prefixs
def rulesGenerator(frequentPatterns, minConf, rules):
for frequentset in frequentPatterns:
if(len(frequentset) > 1):
getRules(frequentset,frequentset, rules, frequentPatterns, minConf)
def removeStr(set, str):
tempSet = []
for elem in set:
if(elem != str):
tempSet.append(elem)
tempFrozenSet = frozenset(tempSet)
return tempFrozenSet
def getRules(frequentset,currentset, rules, frequentPatterns, minConf):
for frequentElem in currentset:
subSet = removeStr(currentset, frequentElem)
confidence = frequentPatterns[frequentset] / frequentPatterns[subSet]
if (confidence >= minConf):
flag = False
for rule in rules:
if(rule[0] == subSet and rule[1] == frequentset - subSet):
flag = True
if(flag == False):
rules.append((subSet, frequentset - subSet, confidence))
if(len(subSet) >= 2):
getRules(frequentset, subSet, rules, frequentPatterns, minConf)