安装
Windows: pip install mechanize
Linux:pip install python-mechanize
个人感觉mechanize也只适用于静态网页的抓取,如果是异步的数据,则页面显示的结果与抓取的结果不一致,使用有比较大的局限性。
功能测试:百度搜索萧县房价
准备工作:
# _*_ coding:utf-8 _*_ import mechanize
# 创建一个浏览器实例 br = mechanize.Browser()
# 设置是否处理HTML http-equiv标头 br.set_handle_equiv(True)
# 设置是否处理重定向 br.set_handle_redirect(True)
# 设置是否向每个请求添加referer头 br.set_handle_referer(True)
# 设置是不遵守robots中的规则 br.set_handle_robots(False)
# 处理giz传输编码 br.set_handle_gzip(False)
# 设置浏览器的头部信息 br.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36')]
打开百度浏览器的主页
br.open("https://www.baidu.com")
for form in br.forms():
print form
执行结果如下:
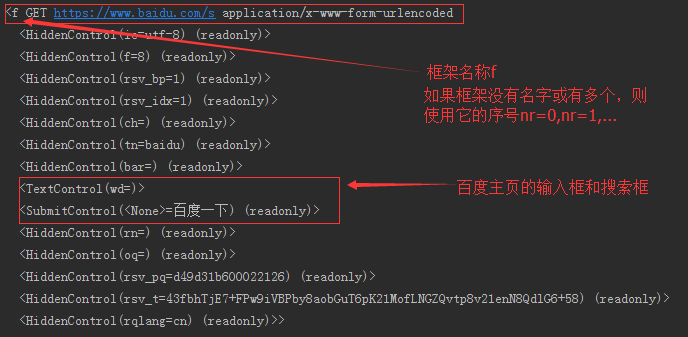
选择框架并提交要搜索的内容
br.select_form(name='f') br.form['wd'] = '萧县房价' br.submit() print br.response().read() 结果对比:
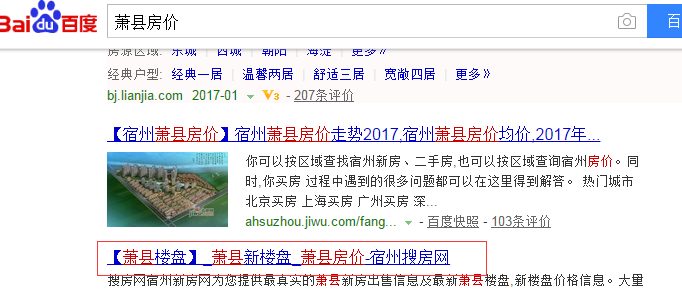

从以上对比结果可以看出,我们使用mechanize查询萧县房价,成功返回了查询结果。
查看返回页面的所有链接
for link in br.links():
print "%s:%s"%(link.text,link.url)
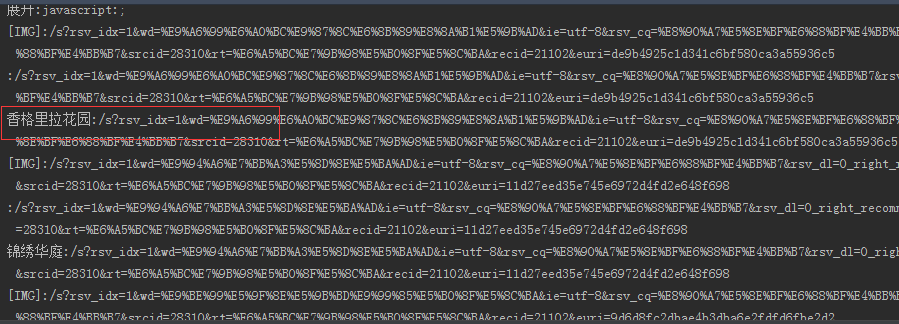
打开一个链接,并返回其值
# 发现一个链接并返回其请求对象
new_link = br.click_link(text='香格里拉花园')
# 发送一个链接请求 br.open(new_link) print br.response().read()

如果觉得打开的不对,使用br.back()返回上一个页面。
========================================
br的详细语法
Help on instance of Browser in module mechanize._mechanize:
class Browser(mechanize._useragent.UserAgentBase)
| Browser-like class with support for history, forms and links.
|
| BrowserStateError is raised whenever the browser is in the wrong state to
| complete the requested operation - e.g., when .back() is called when the
| browser history is empty, or when .follow_link() is called when the current
| response does not contain HTML data.
|
| Public attributes:
|
| request: current request (mechanize.Request)
| form: currently selected form (see .select_form())
|
| Method resolution order:
| Browser
| mechanize._useragent.UserAgentBase
| mechanize._opener.OpenerDirector
| mechanize._urllib2_fork.OpenerDirector
|
| Methods defined here:
|
| __getattr__(self, name)
|
| __init__(self, factory=None, history=None, request_class=None)
| Only named arguments should be passed to this constructor.
|
| factory: object implementing the mechanize.Factory interface.
| history: object implementing the mechanize.History interface. Note
| this interface is still experimental and may change in future.
| request_class: Request class to use. Defaults to mechanize.Request
|
| The Factory and History objects passed in are 'owned' by the Browser,
| so they should not be shared across Browsers. In particular,
| factory.set_response() should not be called except by the owning
| Browser itself.
|
| Note that the supplied factory's request_class is overridden by this
| constructor, to ensure only one Request class is used.
|
| __str__(self)
|
| back(self, n=1)
| Go back n steps in history, and return response object.
|
| n: go back this number of steps (default 1 step)
|
| clear_history(self)
|
| click(self, *args, **kwds)
| See mechanize.HTMLForm.click for documentation.
|
| click_link(self, link=None, **kwds)
| Find a link and return a Request object for it.
|
| Arguments are as for .find_link(), except that a link may be supplied
| as the first argument.
|
| close(self)
|
| encoding(self)
|
| find_link(self, **kwds)
| Find a link in current page.
|
| Links are returned as mechanize.Link objects.
|
| # Return third link that .search()-matches the regexp "python"
| # (by ".search()-matches", I mean that the regular expression method
| # .search() is used, rather than .match()).
| find_link(text_regex=re.compile("python"), nr=2)
|
| # Return first http link in the current page that points to somewhere
| # on python.org whose link text (after tags have been removed) is
| # exactly "monty python".
| find_link(text="monty python",
| url_regex=re.compile("http.*python.org"))
|
| # Return first link with exactly three HTML attributes.
| find_link(predicate=lambda link: len(link.attrs) == 3)
|
| Links include anchors (<a>), image maps (<area>), and frames (<frame>,
| <iframe>).
|
| All arguments must be passed by keyword, not position. Zero or more
| arguments may be supplied. In order to find a link, all arguments
| supplied must match.
|
| If a matching link is not found, mechanize.LinkNotFoundError is raised.
|
| text: link text between link tags: e.g. <a href="blah">this bit</a> (as
| returned by pullparser.get_compressed_text(), ie. without tags but
| with opening tags "textified" as per the pullparser docs) must compare
| equal to this argument, if supplied
| text_regex: link text between tag (as defined above) must match the
| regular expression object or regular expression string passed as this
| argument, if supplied
| name, name_regex: as for text and text_regex, but matched against the
| name HTML attribute of the link tag
| url, url_regex: as for text and text_regex, but matched against the
| URL of the link tag (note this matches against Link.url, which is a
| relative or absolute URL according to how it was written in the HTML)
| tag: element name of opening tag, e.g. "a"
| predicate: a function taking a Link object as its single argument,
| returning a boolean result, indicating whether the links
| nr: matches the nth link that matches all other criteria (default 0)
|
| follow_link(self, link=None, **kwds)
| Find a link and .open() it.
|
| Arguments are as for .click_link().
|
| Return value is same as for Browser.open().
|
| forms(self)
| Return iterable over forms.
|
| The returned form objects implement the mechanize.HTMLForm interface.
|
| geturl(self)
| Get URL of current document.
|
| global_form(self)
| Return the global form object, or None if the factory implementation
| did not supply one.
|
| The "global" form object contains all controls that are not descendants
| of any FORM element.
|
| The returned form object implements the mechanize.HTMLForm interface.
|
| This is a separate method since the global form is not regarded as part
| of the sequence of forms in the document -- mostly for
| backwards-compatibility.
|
| links(self, **kwds)
| Return iterable over links (mechanize.Link objects).
|
| open(self, url, data=None, timeout=<object object>)
|
| open_local_file(self, filename)
|
| open_novisit(self, url, data=None, timeout=<object object>)
| Open a URL without visiting it.
|
| Browser state (including request, response, history, forms and links)
| is left unchanged by calling this function.
|
| The interface is the same as for .open().
|
| This is useful for things like fetching images.
|
| See also .retrieve().
|
| reload(self)
| Reload current document, and return response object.
|
| response(self)
| Return a copy of the current response.
|
| The returned object has the same interface as the object returned by
| .open() (or mechanize.urlopen()).
|
| select_form(self, name=None, predicate=None, nr=None)
| Select an HTML form for input.
|
| This is a bit like giving a form the "input focus" in a browser.
|
| If a form is selected, the Browser object supports the HTMLForm
| interface, so you can call methods like .set_value(), .set(), and
| .click().
|
| Another way to select a form is to assign to the .form attribute. The
| form assigned should be one of the objects returned by the .forms()
| method.
|
| At least one of the name, predicate and nr arguments must be supplied.
| If no matching form is found, mechanize.FormNotFoundError is raised.
|
| If name is specified, then the form must have the indicated name.
|
| If predicate is specified, then the form must match that function. The
| predicate function is passed the HTMLForm as its single argument, and
| should return a boolean value indicating whether the form matched.
|
| nr, if supplied, is the sequence number of the form (where 0 is the
| first). Note that control 0 is the first form matching all the other
| arguments (if supplied); it is not necessarily the first control in the
| form. The "global form" (consisting of all form controls not contained
| in any FORM element) is considered not to be part of this sequence and
| to have no name, so will not be matched unless both name and nr are
| None.
|
| set_cookie(self, cookie_string)
| Request to set a cookie.
|
| Note that it is NOT necessary to call this method under ordinary
| circumstances: cookie handling is normally entirely automatic. The
| intended use case is rather to simulate the setting of a cookie by
| client script in a web page (e.g. JavaScript). In that case, use of
| this method is necessary because mechanize currently does not support
| JavaScript, VBScript, etc.
|
| The cookie is added in the same way as if it had arrived with the
| current response, as a result of the current request. This means that,
| for example, if it is not appropriate to set the cookie based on the
| current request, no cookie will be set.
|
| The cookie will be returned automatically with subsequent responses
| made by the Browser instance whenever that's appropriate.
|
| cookie_string should be a valid value of the Set-Cookie header.
|
| For example:
|
| browser.set_cookie(
| "sid=abcdef; expires=Wednesday, 09-Nov-06 23:12:40 GMT")
|
| Currently, this method does not allow for adding RFC 2986 cookies.
| This limitation will be lifted if anybody requests it.
|
| set_handle_referer(self, handle)
| Set whether to add Referer header to each request.
|
| set_response(self, response)
| Replace current response with (a copy of) response.
|
| response may be None.
|
| This is intended mostly for HTML-preprocessing.
|
| submit(self, *args, **kwds)
| Submit current form.
|
| Arguments are as for mechanize.HTMLForm.click().
|
| Return value is same as for Browser.open().
|
| title(self)
| Return title, or None if there is no title element in the document.
|
| Treatment of any tag children of attempts to follow Firefox and IE
| (currently, tags are preserved).
|
| viewing_html(self)
| Return whether the current response contains HTML data.
|
| visit_response(self, response, request=None)
| Visit the response, as if it had been .open()ed.
|
| Unlike .set_response(), this updates history rather than replacing the
| current response.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| default_features = ['_redirect', '_cookies', '_refresh', '_equiv', '_b...
|
| handler_classes = {'_basicauth': <class mechanize._urllib2_fork.HTTPBa...
|
| ----------------------------------------------------------------------
| Methods inherited from mechanize._useragent.UserAgentBase:
|
| add_client_certificate(self, url, key_file, cert_file)
| Add an SSL client certificate, for HTTPS client auth.
|
| key_file and cert_file must be filenames of the key and certificate
| files, in PEM format. You can use e.g. OpenSSL to convert a p12 (PKCS
| 12) file to PEM format:
|
| openssl pkcs12 -clcerts -nokeys -in cert.p12 -out cert.pem
| openssl pkcs12 -nocerts -in cert.p12 -out key.pem
|
|
| Note that client certificate password input is very inflexible ATM. At
| the moment this seems to be console only, which is presumably the
| default behaviour of libopenssl. In future mechanize may support
| third-party libraries that (I assume) allow more options here.
|
| add_password(self, url, user, password, realm=None)
|
| add_proxy_password(self, user, password, hostport=None, realm=None)
|
| set_client_cert_manager(self, cert_manager)
| Set a mechanize.HTTPClientCertMgr, or None.
|
| set_cookiejar(self, cookiejar)
| Set a mechanize.CookieJar, or None.
|
| set_debug_http(self, handle)
| Print HTTP headers to sys.stdout.
|
| set_debug_redirects(self, handle)
| Log information about HTTP redirects (including refreshes).
|
| Logging is performed using module logging. The logger name is
| "mechanize.http_redirects". To actually print some debug output,
| eg:
|
| import sys, logging
| logger = logging.getLogger("mechanize.http_redirects")
| logger.addHandler(logging.StreamHandler(sys.stdout))
| logger.setLevel(logging.INFO)
|
| Other logger names relevant to this module:
|
| "mechanize.http_responses"
| "mechanize.cookies"
|
| To turn on everything:
|
| import sys, logging
| logger = logging.getLogger("mechanize")
| logger.addHandler(logging.StreamHandler(sys.stdout))
| logger.setLevel(logging.INFO)
|
| set_debug_responses(self, handle)
| Log HTTP response bodies.
|
| See docstring for .set_debug_redirects() for details of logging.
|
| Response objects may be .seek()able if this is set (currently returned
| responses are, raised HTTPError exception responses are not).
|
| set_handle_equiv(self, handle, head_parser_class=None)
| Set whether to treat HTML http-equiv headers like HTTP headers.
|
| Response objects may be .seek()able if this is set (currently returned
| responses are, raised HTTPError exception responses are not).
|
| set_handle_gzip(self, handle)
| Handle gzip transfer encoding.
|
| set_handle_redirect(self, handle)
| Set whether to handle HTTP 30x redirections.
|
| set_handle_refresh(self, handle, max_time=None, honor_time=True)
| Set whether to handle HTTP Refresh headers.
|
| set_handle_robots(self, handle)
| Set whether to observe rules from robots.txt.
|
| set_handled_schemes(self, schemes)
| Set sequence of URL scheme (protocol) strings.
|
| For example: ua.set_handled_schemes(["http", "ftp"])
|
| If this fails (with ValueError) because you've passed an unknown
| scheme, the set of handled schemes will not be changed.
|
| set_password_manager(self, password_manager)
| Set a mechanize.HTTPPasswordMgrWithDefaultRealm, or None.
|
| set_proxies(self, proxies=None, proxy_bypass=None)
| Configure proxy settings.
|
| proxies: dictionary mapping URL scheme to proxy specification. None
| means use the default system-specific settings.
| proxy_bypass: function taking hostname, returning whether proxy should
| be used. None means use the default system-specific settings.
|
| The default is to try to obtain proxy settings from the system (see the
| documentation for urllib.urlopen for information about the
| system-specific methods used -- note that's urllib, not urllib2).
|
| To avoid all use of proxies, pass an empty proxies dict.
|
| >>> ua = UserAgentBase()
| >>> def proxy_bypass(hostname):
| ... return hostname == "noproxy.com"
| >>> ua.set_proxies(
| ... {"http": "joe:password@myproxy.example.com:3128",
| ... "ftp": "proxy.example.com"},
| ... proxy_bypass)
|
| set_proxy_password_manager(self, password_manager)
| Set a mechanize.HTTPProxyPasswordMgr, or None.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from mechanize._useragent.UserAgentBase:
|
| default_others = ['_unknown', '_http_error', '_http_default_error']
|
| default_schemes = ['http', 'ftp', 'file', 'https']
|
| ----------------------------------------------------------------------
| Methods inherited from mechanize._opener.OpenerDirector:
|
| add_handler(self, handler)
|
| error(self, proto, *args)
|
| retrieve(self, fullurl, filename=None, reporthook=None, data=None, timeout=<object object>, open=<built-in function open>)
| Returns (filename, headers).
|
| For remote objects, the default filename will refer to a temporary
| file. Temporary files are removed when the OpenerDirector.close()
| method is called.
|
| For file: URLs, at present the returned filename is None. This may
| change in future.
|
| If the actual number of bytes read is less than indicated by the
| Content-Length header, raises ContentTooShortError (a URLError
| subclass). The exception's .result attribute contains the (filename,
| headers) that would have been returned.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from mechanize._opener.OpenerDirector:
|
| BLOCK_SIZE = 8192
None
进程已结束,退出代码0