线性回归(Linear Regression),亦称为直线回归,即用直线表示的回归,与曲线回归相对。若因变量Y对自变量X1、X2…、Xm的回归方程是线性方程,即μy=β0 +β1X1 +β2X2 +…βmXm,其中β0是常数项,βi是自变量Xi的回归系数,M为任何自然数。这时就称Y对X1、X2、…、Xm的回归为线性回归。
简单回归:
只有一个自变量的线性回归称为简单回归,如下面示例:
X表示某商品的数量,Y表示这些不同数量商品的总价格
x=[0, 1, 2, 3, 4, 5]
y=[0, 17, 45, 55, 85, 99]
二维坐标中绘图如下图:
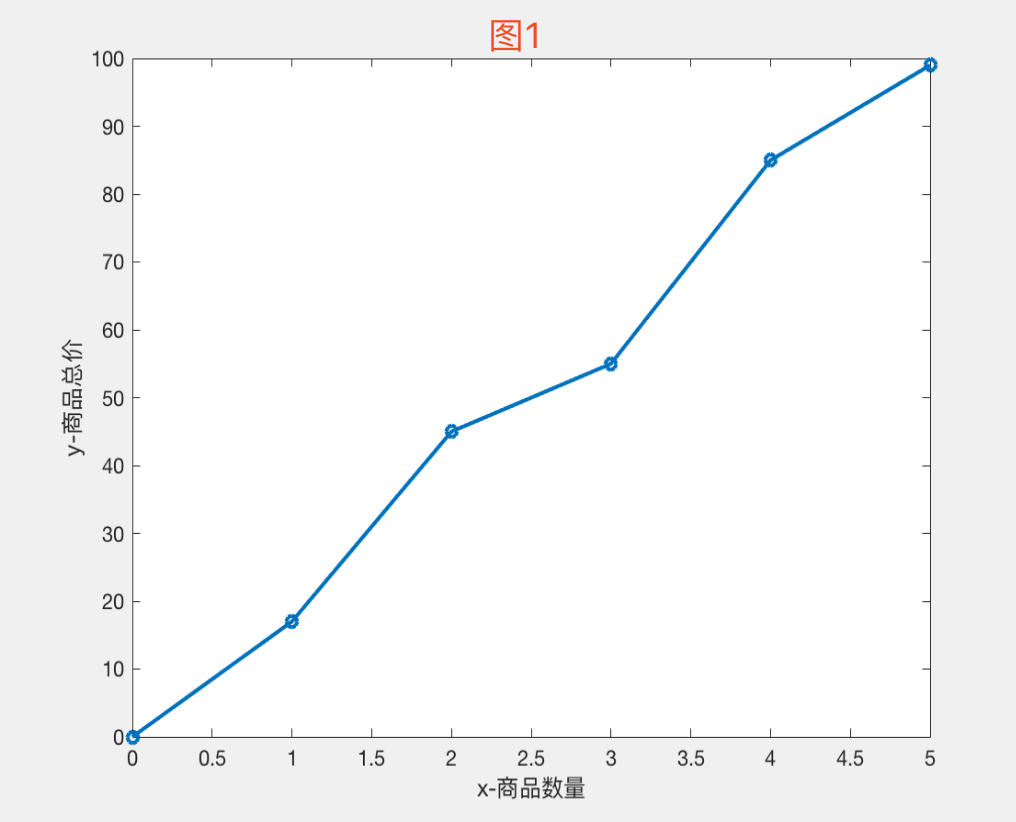
现在当商品数量 X = 6时,估计商品总价是多少?
我们可以很明显的看到,商品总价随商品的数量上升而上升,这是一个典型的线性回归。
因为只有一个自变量X,我们假设线性回归模型: Y = a * X + b
我们需要求出最合适的a,b值,使得直线:Y = a * X + b 与上图的趋势相拟合,这时候才能去预测不同商品数量X下的总价Y。
最小二乘法:
为了求出最合适的a b ,我们引入最小二乘法。
最小二乘法,亦称最小二乘法估计。由样本观测值估计总体参数的一种常用方法。它用于从n对观测数据(x1,y1),(x2,y2),……,(xn,yn)确定x与y之间对应关系y=f(x)的一种最佳估计,使得观测值与估计值之差(即偏差)的平方和 H为最小。
![]()
最小二乘法能尽量消除偶然误差的影响,从而由一组观测数据求出最可靠、最可能出现的结果。
由上图我们可以很明显的看出直线Y = a * X + b过原点,即 b = 0
我们尝试不同的a值 得到的结果如下:
a = 19 时 H = 154
a = 20 时 H = 85
a = 21 时 H = 126
图像分别如下:
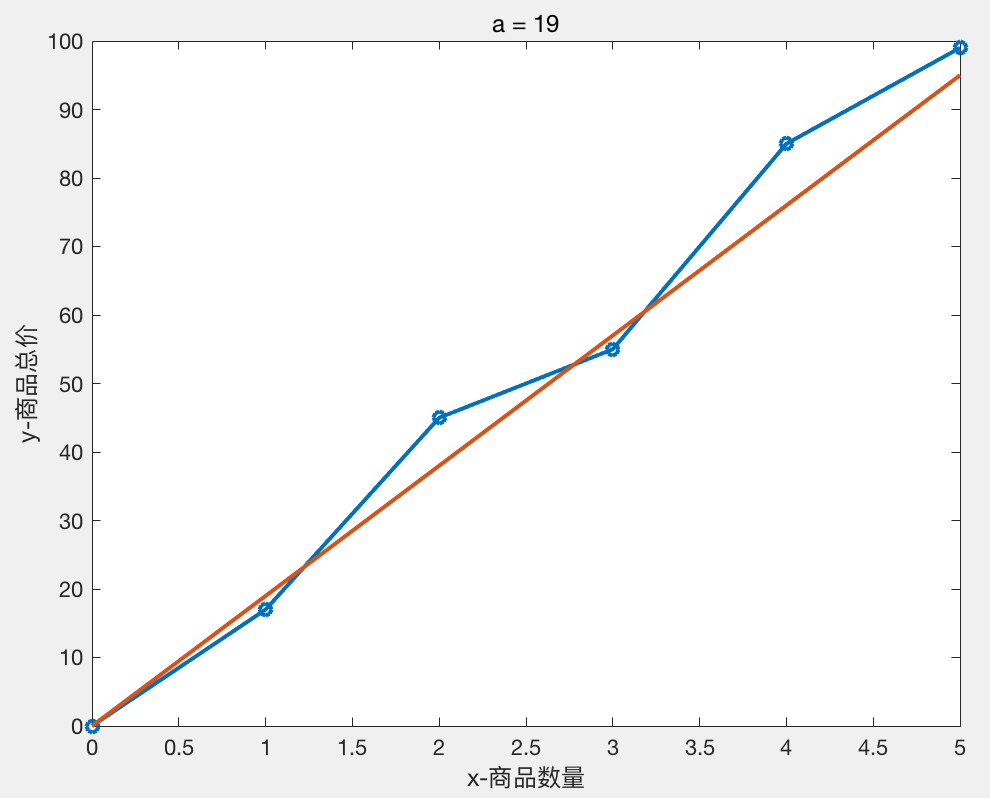
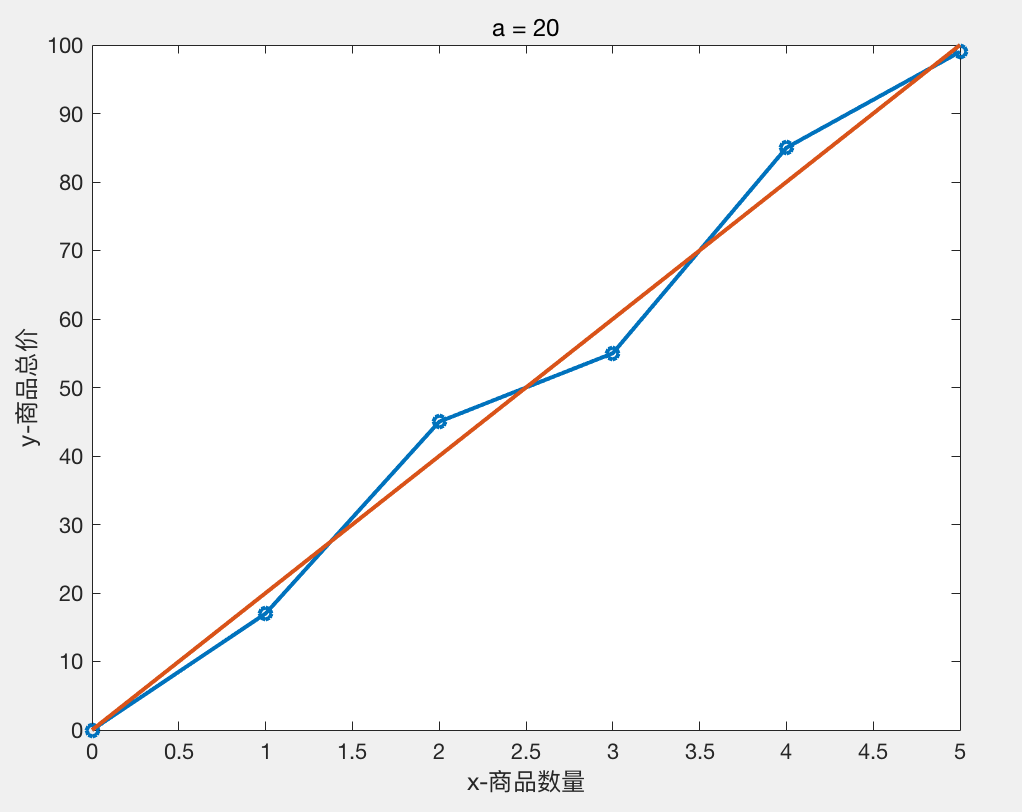
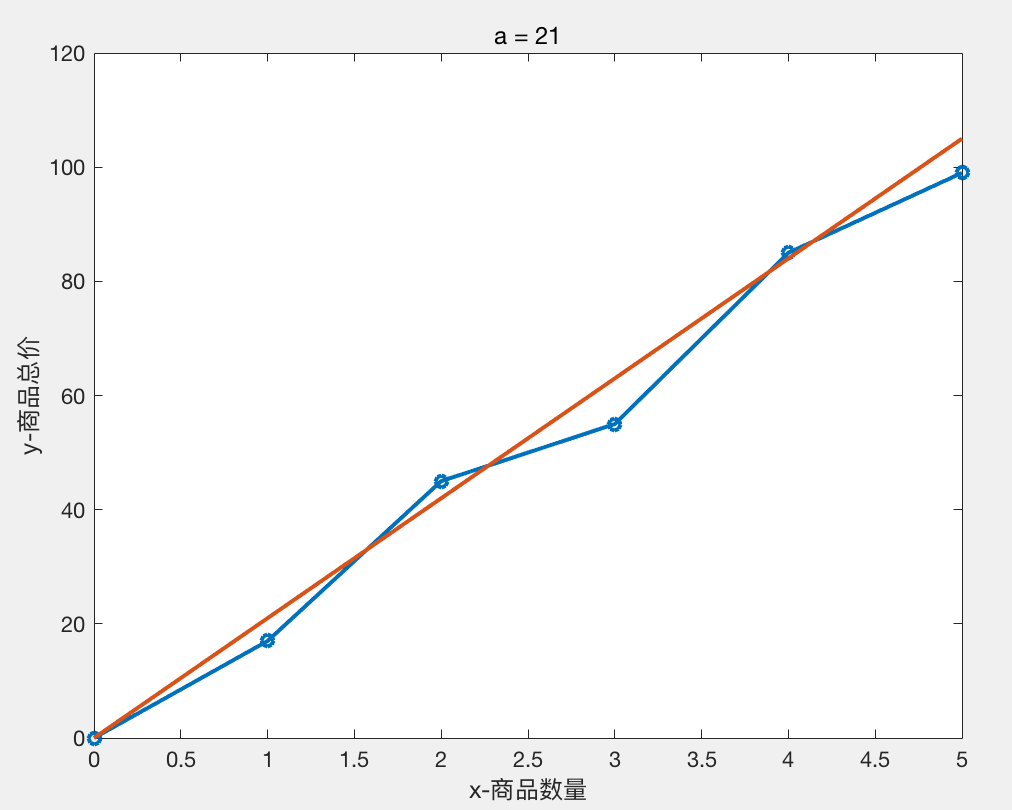
我们可以粗略得出结论 a = 20,b = 0 时,线性模型 Y = 20 * X 与样本数据拟合的比较好。
所以当商品数量 X = 6 时,我们可以粗略估计总价Y = 20 * 6 = 120
多元回归:
大于一个自变量的线性回归叫做多元回归。
上面的例子只是一个自变量,处理起来比较简单,但是若自变量有很多,假设自变量有m个,为 [ x1,x2,x3,x4.....xm ]
这时候我们假设的回归系数(即权重)也需要有m个,即我们假设的线性模型是 Y = X0 + X1*W1 + X2*W2 + X3*W3 + ....... + Xm*Wm
为了计算方便,我们去W0 = 1
这样:Y = X0*W0 + X1*W1 + X2*W2 + X3*W3 + ....... + Xm*Wm
写成向量形式:
W = [W0,W1 , W2 ,W3 , .... ,Wm]
X = [ X0, X1 , X2 , X3 , .... , Xm]
Y = WT * X (WT为向量W的转置)
观测值与估计值之差(即偏差)的平方和:
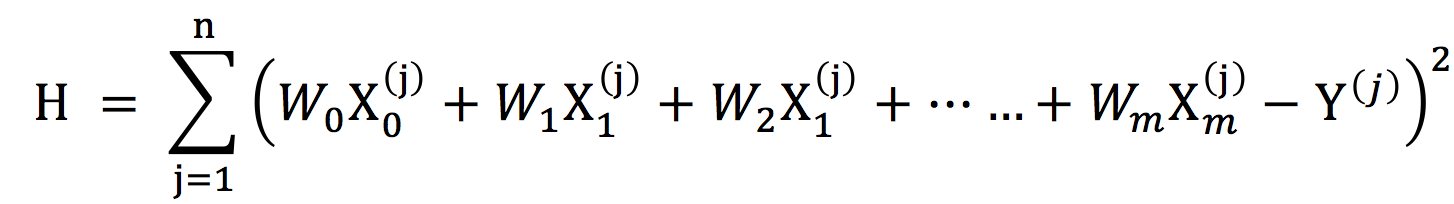
为了方便后面计算,我们在H的左边乘上二分之一,即:
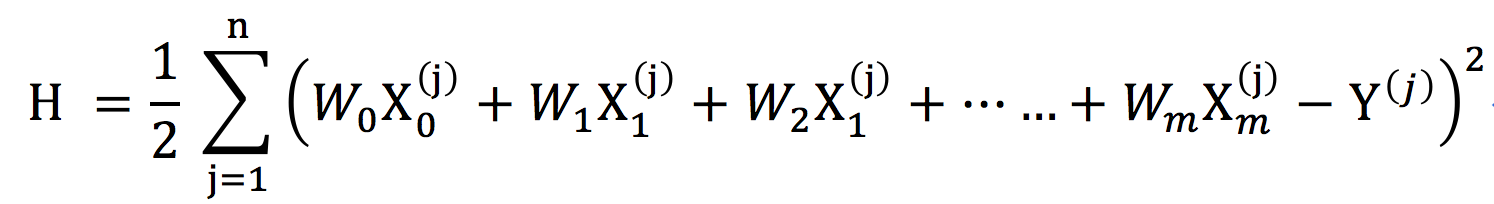
上面公式中 n 表示训练样本的数目,m 表示每条训练样本 的特征(自变量)个数,![]() 上标表示属于第 j 个 样本,下标表示第 i 个特征(自变量值),
上标表示属于第 j 个 样本,下标表示第 i 个特征(自变量值),![]() 表示第 j 个样本总价观测值
表示第 j 个样本总价观测值
现在H是关于W0,W1,W2....Wm的函数,我们需要通过合适的方法求出最适合的W值,才能得出一个比较好的线性回归方程。与简单回归相比,这里我们很难通过观察与尝试不同的w值来求解,我们需要采用最优化算法。
梯度算法:
常见的最优化算法有梯度下降法(Gradient Descent)、牛顿法和拟牛顿法(Newton's method & Quasi-Newton Methods)、共轭梯度法(Conjugate Gradient)、 启发式优化方法等,本文详细介绍梯度算法。
明确下我们现在的目标:我们需要通过梯度算法求出---当在H取得最小的情况下,W0 ,W1 ,W2 ,W3 , ....... ,Wm的值,从而写出回归方程。
梯度算法分为梯度上升算法 和 梯度下降算法。梯度下降算法的基本思想是:要找到某函数的最小值,最好的方法是沿着该函数的梯度方向探寻,梯度上升则相反。对于一个有两个未知数x,y的函数f(x,y),梯度表示为:
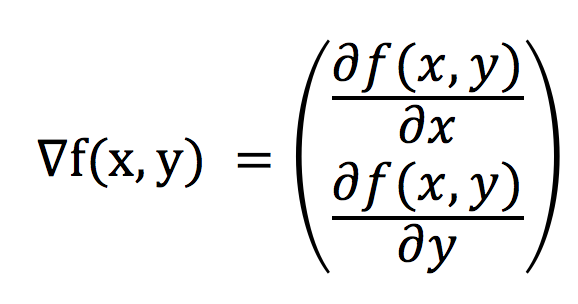
对于Z = f(x,y),使用梯度下降算法的意味着 沿X轴方向移动![]() ,沿Y的方向移动
,沿Y的方向移动![]() ,函数f(x,y)必须要在待计算的点上有定义并且可微。
,函数f(x,y)必须要在待计算的点上有定义并且可微。
可以通俗理解为:
用梯度下降法找出最小H
我们前面看到:
H是关于W = [W0 ,W1 ,W2 ,W3 , ....... ,Wm]的函数,H的梯度如下:
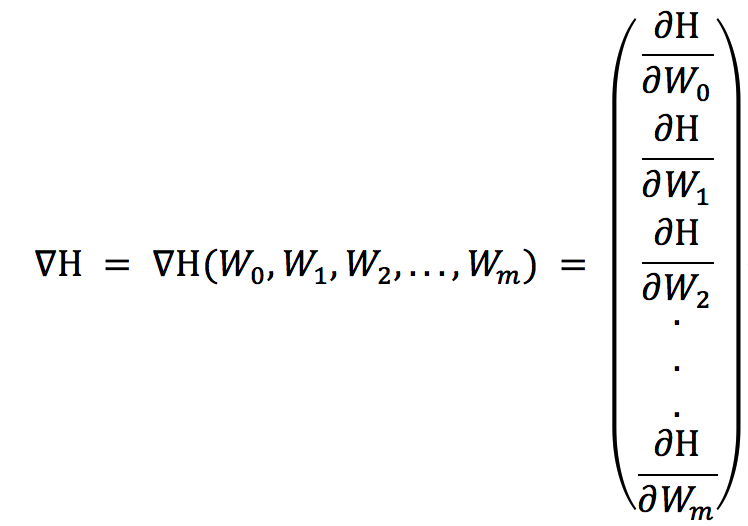
这个时候对于每一个Wi的梯度:
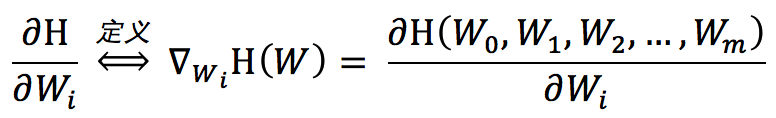
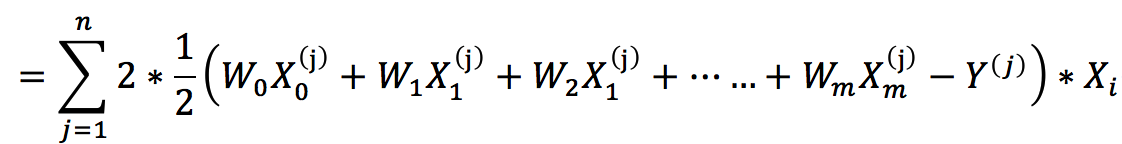
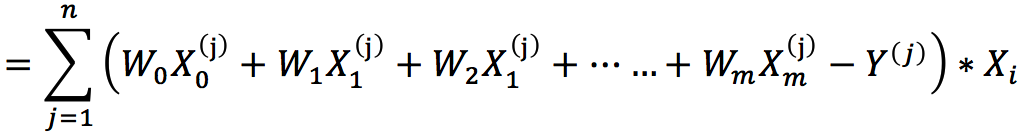
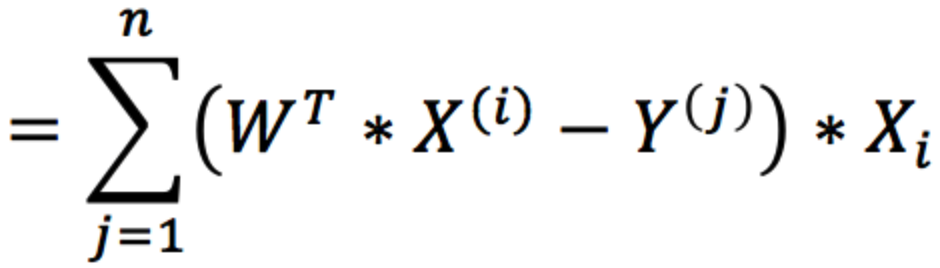
我们假设每次沿着梯度方向更新的步长为 α,所以W的值更新公式可写为:
![]()
所以梯度下降算法的伪代码如下:
每个回归系数(即每个W值)的每个值都为1
重复R次:
计算整个数据集的梯度![]()
使用![]() 更新回归系数W
更新回归系数W
实例:
用梯度下降 算法求下面商品数据的线性回归方程
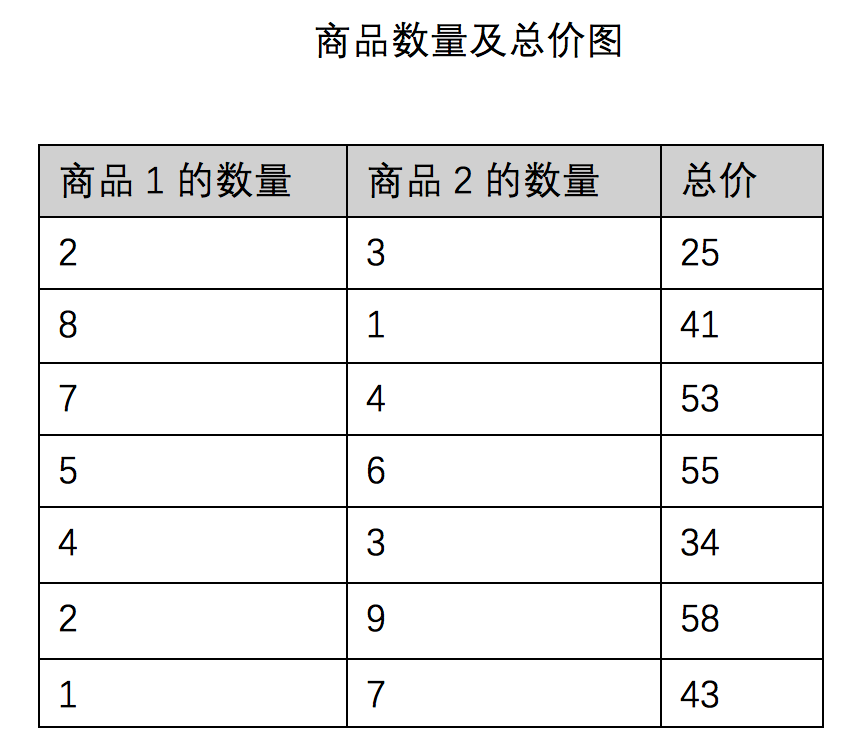
我们假设线性回归模型为总价Y = a + b * X1 + c * X2 (X1 X2 分别表示商品1,2的数量)
我们需要求出回归系数W = [ a, b, c]
梯度下降算法如下:
import numpy as np def grad_desc(train_data, train_labels): """梯度下降""" data_mat = np.matrix(train_data) label_mat = np.matrix(train_labels).transpose() n = np.shape(data_mat)[1] # 步长 alpha = 0.001 # 最大循环次数 max_cycles = 100 # 初始化回归系数weights weights = np.ones((n, 1)) for index in range(max_cycles): h = data_mat * weights-label_mat weights = weights - alpha * data_mat.transpose() * h # 返回压平的系数数组 return np.asarray(weights).flatten()
我们用上面算法得到的回归系数为
使用![]() 更新回归系数W
更新回归系数W
修改后的算法如下:
import numpy as np def advanced_random_grad_desc(train_data, train_labels): """随机梯度下降改进""" data_mat = np.asarray(train_data) label_mat = np.asarray(train_labels) m, n = np.shape(data_mat) # 步长 alpha = 0.001 # 初始化回归系数weights weights = np.ones(n) max_cycles = 500 for j in range(max_cycles): data_index = list(range(m)) for i in range(m): random_index = int(np.random.uniform(0, len(data_index))) h = sum(data_mat[random_index] * weights)-label_mat[random_index] weights = weights - alpha * h * data_mat[random_index] del data_index[random_index] return weights
计算得到的回归系数为:
我们可以得到线性回归方程为:
Y = 1.27 + 4.31 * X1 + 5.28 * X2
def grad_ascent(data_mat, data_labels, num_iter=200): 26 """随机梯度上升算法""" 27 data_mat = np.array(data_mat) 28 m, n = np.shape(data_mat) 29 30 weights = np.ones(n).astype(np.float) 31 for j in range(num_iter): 32 data_index = list(range(m)) 33 for i in range(m): 34 alpha = 0.001 + 4 / (1.0 + j + i) 35 36 random_index = int(np.random.uniform(0, len(data_index))) 37 h = sigmoid(sum(data_mat[random_index] * weights)) 38 error = data_labels[random_index] - h 39 weights = weights + alpha * error * data_mat[random_index] 40 del (data_index[random_index]) 41 42 return weights
Sigmoid函数
对于二分类问题,我们想要一个函数能够接受所有输入然后预测出两种类别,可以通过输出0或者1。这个函数就是sigmoid函数,它是一种阶跃函数具体的计算公式如下:
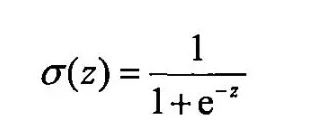
Sigmoid函数的性质: 当x为0时,Sigmoid函数值为0.5,随着x的增大对应的Sigmoid值将逼近于1; 而随着x的减小, Sigmoid函数会趋近于0。
def sigmoid(x): # 阶跃函数 return 1.0 / (1 + np.exp(-x))