在数字信号处理系统中,有限脉冲响应(finite impulse response,FIR)数字滤波器是一个非常重要的基本单元。近年来,由于FPGA具有高速度、高集成度和高可靠性的特点而得到快速发展。随着现代数字通信系统对于高精度、高处理速度的需求,越来越多的研究转向采用FPGA来实现FIR滤波器。而对于FIR滤波器要充分考虑其资源与运行速度的合理优化,各种不同的FIR滤波结构各具优缺点,在了解各种结构优
缺点后才能更好地选择合适结构来实现FIR滤波。
1 FIR数字滤波器
FIR数字滤波器由有限个采样值组成,设计中在满足幅值特性时,还能保证精确、严格的相位特性,因此在信号处理等领域得到广泛的应用。
对于FIR滤波器,其输出y(n)表示为如下形式:
![]()
式中:N为滤波器的阶数(或抽头数);x(i)表示第i时刻的输入样本;h(i)为FIR滤波器的第i级抽头系数。
由于FIR滤波器的冲击响应为一个有限序列,其系统函数可表示为:
![]()
FIR滤波器的基本结构如图1所示。FIR滤波器只在原点处存在极点,所以这使得FIR滤波器具有全局稳定性。同时FIR滤波器满足线性相位条件,其冲击响应序列为实数且满足奇对称或偶对称条件,即:
![]()

2 实现方法
运用FPGA来实现FIR数字滤波器的结构多种多样,但是主要有以下几类:串行结构、并行结构、转置型结构、基于FFT算法结构、分布式结构。其他类型的FIR滤波器结构都可以由以上几种结构衍生而来。
2.1 串行结构
由表达式(1)可知,FIR滤波器实质是做一个乘累加运算,其滤波器的阶数决定了一次乘累加的次数,其串行结构如图2所示。
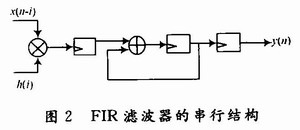
串行结构的FIR滤波器结构简单,硬件资源占用少,只需要复用1个乘法器和1个加法器,所以成本较低。但是,这种结构的FIR滤波器要经过多个时钟周期才有输出,同时,内部时钟周期还受到乘法器运算速度的影响,所以该结构的FIR滤波器处理速度慢,只适用于滤波阶数较低且处理速度要求低的系统。
2.2 并行结构
将串行结构的FIR滤波器展开就可以得到并行结构的FIR滤波器,并行FIR滤波器结构又称作直接型FIR滤波器结构,这种结构是直接根据图1的滤波器结构,用多个乘法器和加法器并行实现。通常考虑到其滤波器系数的对称性,先对输入值进行加法运算,再进行乘法运算,最后累加输出,以此来减少乘法器的个数,其结构如图3所示。
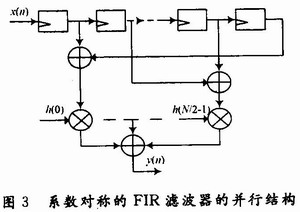
并行结构的FIR滤波器在1个周期内可以完成1次滤波,运行速度快,虽然利用滤波系数对称性,但仍要占用大量的乘法器和加法器,特别对于滤波阶数高的滤波器,其资源占用较多,如对于256阶的滤波器,其需要128个乘法器来实现。为提高滤波器速度,常引入流水线结构,即在每次加法或者乘法运算后加入1个寄存器存储数据,使得滤波器可以运行在更高的频率上。
2.3 转置型结构
根据转置定理,如果将网络中所有的支路方向倒转,并将输入x(n)和输出y(n)相互交换,则其系统函数H(z)不变。通过转置定理,将并行结构的FIR滤波器变换就可以得到转置型FIR滤波器,其结构如图4所示。
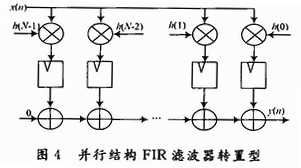
基于并行结构的转置型FIR滤波器实现了数据的并行输入,在1个周期内就能完成1次滤波,并且各级结构相同,在每个阶段都可以读出数据,可以对滤波阶数进行扩展或者缩减,实现任意阶数的滤波器。但是由于基于的是并行结构,便有着并行结构的一些缺点,主要是对于高阶的滤波器,其资源占用量是巨大的,设计成本高。虽然这样,转置型FIR滤波器仍是应用广泛的一种滤波器。
2.4 基于FFT的结构
应用快速傅里叶变换(fast fourier transform,FFT)实现FIR滤波器是一种快速实现滤波算法的重要途径。由式(1)可知,FIR滤波器的输出y(n)是输入x(n)与系统冲击响应序列h(n)的卷积,应用FFT可以快速实现卷积变换。如图5所示,先将输入信号x(n)通过FFT变换为它的频谱采样值X(k),然后再与FIR滤波器的频响采样值H(k)相乘,H(k)可事先存放在存储器中,最后再将乘积X(k)H(k)通过快速傅里叶反变换(IF-FT)还原为时域序列,即得到输出y(n)。

为实现FFT,根据两有限长序列的线性卷积可用其循环卷积代替而不发生混叠,必须选择循环卷积长度N≥N1+N2-1,即将x(n)和h(n)补零至长度为N的序列,即:
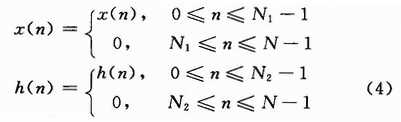
在基于FFT的FIR滤波器结构中,求X(k),H(k)以及反傅里叶变换y(n)需要的乘法次数均为N/2log2N,而计算X(k)H(k)需要N次乘法,所以基于FFT的总乘法次数为mf=3/2Nlog2N+N。由于h(n)满足式(3)条件,所以直接卷积所需的乘法次数为md=1/2N1N2。假设N1=N2,则比较这两种乘法计算量有:
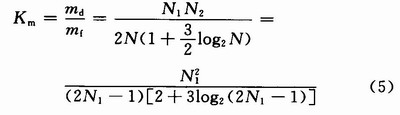
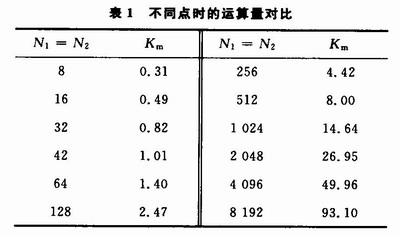
从表1可知,当N1<42时,FFT法的运算量小于直接卷积的运算量,当N1=42时,FFT法的运算量与直接卷积的运算量相当,当N1>42时,FFT法的运算量大于直接卷积的运算量,并且随着N1增加,FFT法的运算速度越来越快,特别是N1=8 192时,FFT法的运算速度与直接卷积相比快上将近100倍。
2.5 分布式结构
2.5.1 分布式算法原理
分布式算法(distributed arithmetic,DA)于1973年就由Croisier提出,但是直到FPGA出现,才广泛的被应用于FPGA中计算乘累积和。
对于有符号数x(n)可以用下式的补码形式表示:
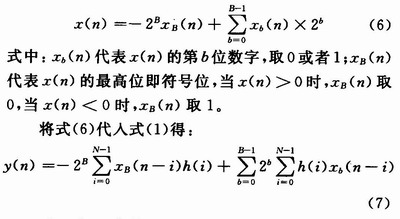
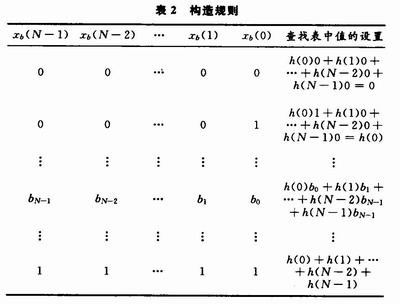
对于式(7)中的h(i)xb(n-i)代表着输入数据x(n-i)的第i位与抽头系数h(i)的乘积,对于FIR滤波器,其系数h(i)是常数,所以可以事先构造一个查找表。该查找表存储所有h(i)xb(n-i)的乘积值,通过输入(xb(N-1),xb(N-2),…,xb(0))对该表寻址,然后将查得的值乘上2b后移位累加便得到滤波器输出y(n)。该查找表构造规则如表2所示。
2.5.2 基于分布式算法的FIR滤波器结构
基于分布式算法的FIR滤波器主要有3种结构类型。
(1)第一种结构为串行分布式结构。串行分布式FIR滤波器的原理为,首先用所有N个输入量的最低位对DA查找表进行寻址查值,得到一个部分积,将部分积右移一位即相当于除以2后放到寄存器中暂存。同时,N个输入量的次低位开始对DA查找表进行寻址查值,得到另一个部分积,把该部分积与上一个储存在寄存器中的值进行相加,相加后的值再右移一位放到寄存器中。以此重复循环累加,直到所有位数都寻址完
成,注意最高位寻址后的部分积是相减,最后所得到的值就是所需要的结果。
当N过大,即FIR滤波器的滤波阶数很高时,采用一个查找表来实现将使得存储查找表的ROM变得十分庞大。为此可采用部分表结构,即将查找表划分为多个部分,N个输入量的同一位对应不同的部分表寻址。图6所示即为基于4输入部分表结构的串行DA结构。

(2)第二种结构为并行分布式结构。并行分布式结构就是将N个输入量的不同位进行同时查表,而相同位送入同一个ROM寻址,不同位有不同的ROM。其结构如图7所示。
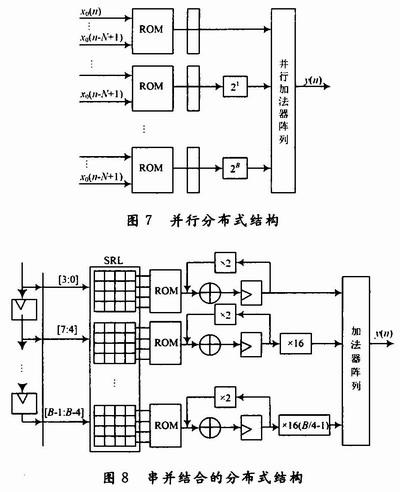
第三种结构为串并结合分布式结构。它是一种折中方案,既要求速度不太高又要求资源占用少。对于串行分布式算法,是一次一位(one bit-at-a-time,1BAAT)查找表,而并行分布式算法是一次B位(B bits-at-a-time)。所以串并结合分布式算法采用一次多位,如2BAAT,3BA-AT。图8所示为4BAAT查找表结构图。
图8中位数B是4的倍数,SRL为移位寄存器。SRL中第1行从右边数第1列为数据的0位,第2列为数据的1位,第3列为数据的2位,第4列为数据的3位。类似地,第2行右数第1列为数据的4位,第2列为数据的5位,第3列为数据的6位,第4列为数据的7位。以后各行按相似的数位顺序排列。在第一个时钟周期,数据的0,4,…,B-4位同时进入查找表ROM中,查出所要的数据,第二个时钟周期,1,5,…,B-3位同时进入ROM中,查出所要的数据,所查得的数据传递给下一级累加器进行累加,这样依次对剩下的各数据位进行同样的操作。由于每个块之间相差4位,即16倍,为了对应位相加,所以乘16。FIR滤波器的分布式算法结构比单独用乘法器实现的速度快,特别是滤波阶数越高,其优势更加明显。分布式结构中,串行结构是1次查询1位,所以对B位的数据在不算上移位寄存等的时间,完成1次滤波需要B个时钟周期;而并行结构只需要1个时钟周期便完成滤波,所以并行结构是速度最优的结构,但是并行结构需要B个DA查找表,需要大量的ROM来储存,加大了硬件资源的消耗,特别是阶数越高,硬件规模将十分膨大;串并结构综合两种结构优势,实现在速度和规模上的协调。实际应用中。需根据系统的要求来选择合适的结构。
3 结语
本文定性地分析了各种FIR滤波器的FPGA实现方法。对于低阶的FIR滤波器可采用串行结构、并行结构以及转置型结构来实现,而并行结构和转置型结构的FIR滤波器以牺牲资源损耗来实现了速度上优势;对于高阶的FIR滤波器,基于乘法器结构的串行结构、并行结构及转置型结构在速度上难以达到高速处理的要求,而分布式算法将乘法转换为查表和累加的结构,使得分布式结构的FIR滤波器在速度上得到了提高,
但三种不同形式的分布式结构要在综合考虑资源以及速度的基础上进行合理选择;同样采用FFT实现的FIR滤波器以减少运算量来获得了速度上的提高,特别是滤波阶数越高其速度提升越明显。
现代工程技术领域对滤波系统的带宽、高速、信号的实时性处理等方面要求越来越高,在运用FPGA来实现FIR滤波中,基于乘法器结构的FIR滤波器无法满足以上要求,而分布式结构的FIR滤波器巧妙地运用ROM查找表来实现固定系数的乘累加运算,避免了乘法运算,并且在随后的每级加法运算中引入流水线结构,提高了速度。因此采用分布式算法实现FIR滤波器是目前研究的热点,同时无论哪种分布式算法都要使用ROM来做查找表,但是随着滤波阶数的增加,ROM的数量将会增加,在进一步提高速度的情况下如何减少ROM的数量是今后亟待解决的问题。
1 /********************************************************************************* 2 * Company : 3 * Engineer : 空气微凉 4 * 5 * Create Date : 00:00:00 22/03/2013 6 * Design Name : 7 * Module Name : 8 * Project Name : 9 * Target Devices : 10 * Tool versions : 11 * Description : 12 * http://www.cnblogs.com/kongqiweiliang/ 13 * Dependencies : 14 * 直接型 15 * Revision : 16 * Revision : 0.01 - File Created 17 * Additional Comments : 18 ********************************************************************************/ 19 `timescale 1ns/1ps 20 `define UD #1 21 /*******************************************************************************/ 22 module FIR 23 ( 24 //system interface 25 input iCLK ,// 26 //Interface package 27 input [`DSIZE1-1:0] iDAT ,// 28 output reg [`DSIZE2-1:0] oDAT // 29 ); 30 //------------------------------------------------------------------------------- 31 `define DSIZE1 8 32 `define DSIZE2 16 33 34 reg [`DSIZE1-1:0] TAP0,TAP1,TAP2,TAP3,TAP4,TAP5,TAP6,TAP7,TAP8,TAP9,TAP10; 35 reg [`DSIZE1-1:0] T0 ,T1 ,T2 ,T3 ,T4 ,T5 ; 36 reg [`DSIZE2-1:0] SUM; 37 38 /* 0.0036,-0.0127,0.0417,-0.0878 ,0.1318 ,0.8500 ,0.1318 ,-0.0878,0.0417,-0.0127,0.0036, 39 0.4608,-1.6256,5.3376,-11.2384,16.8704,108.800,16.8704,-11.238,5.3376,-1.6256,0.4608 */ 40 always@(posedge iCLK)begin 41 TAP0 <= iDAT; 42 TAP1 <= TAP0; 43 TAP2 <= TAP1; 44 TAP3 <= TAP2; 45 TAP4 <= TAP3; 46 TAP5 <= TAP4; 47 TAP6 <= TAP5; 48 TAP7 <= TAP6; 49 TAP8 <= TAP7; 50 TAP9 <= TAP8; 51 TAP10 <= TAP9; 52 53 T0 <= TAP0 + TAP10; //h(0) 54 T1 <= TAP1 + TAP9; //h(1) 55 T2 <= TAP2 + TAP8; //h(2) 56 T3 <= TAP3 + TAP7; //h(3) 57 T4 <= TAP4 + TAP6; //h(4) 58 T5 <= TAP5 ; //h(5) 59 //T0 128-4*4-4+0.5+0.25+0.0625=108.8125 = 128 * 0.8500 h(0) 60 //T1 16+0.5+0.25+0.125=16.875 = 128 * 0.1318 h(1) 61 //T2 8+4-1+0.25=11.25 = 128 * -0.0878 h(2) 62 //T3 4+1+0.25+0.0625+0.03125=5.34375 = 128 * 0.0417 h(3) 63 //T4 1+0.5+0.125=1.625 = 128 * -0.0127 h(4) 64 //T5 0.5-0.03125=0.46875 = 128 * 0.0036 h(5) 65 SUM <= (T0<<7)-(T0<<4)-(T0<<2)+{{1{T0[`DSIZE1-1]}},T0[`DSIZE1-1:1]}+{{2{T0[`DSIZE1-2]}},T0[`DSIZE1-1:2]}+{{4{T0[`DSIZE1-1]}},T0[`DSIZE1-1:4]} + 66 (T1<<4)+{{1{T1[`DSIZE1-1]}},T1[`DSIZE1-1:1]} + {{2{T1[`DSIZE1-1]}},T1[`DSIZE1-1:2]}+{{3{T1[`DSIZE1-1]}},T1[`DSIZE1-1:3]} - 67 (T2<<3)+(T2<<2) - T2 + {{2{T2[`DSIZE1-1]}},T2[`DSIZE1-1:2]} + 68 (T3<<2)+T3+{{2{T3[`DSIZE1-1]}},T3[`DSIZE1-1:2]}+{{4{T3[`DSIZE1-1]}},T3[`DSIZE1-1:4]}+{{5{T3[`DSIZE1-1]}},T3[`DSIZE1-1:5]} - 69 T4+{{1{T4[`DSIZE1-1]}},T4[`DSIZE1-1:1]}+{{3{T4[`DSIZE1-1]}},T4[`DSIZE1-1:3]} + 70 {{1{T5[`DSIZE1-1]}},T5[`DSIZE1-1:1]}-{{5{T5[`DSIZE1-1]}},T5[`DSIZE1-1:5]}; 71 72 oDAT <= {{7{SUM[15]}},SUM[15:7]}; 73 end 74 75 //------------------------------------------------------------------------------- 76 endmodule
