并发编程知识点剖析
一.
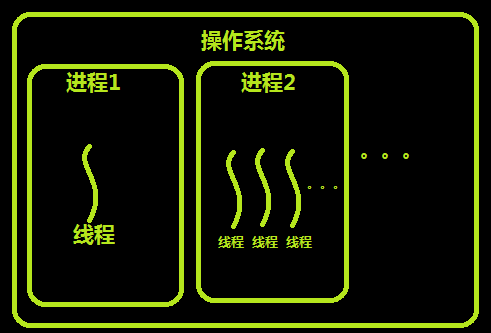
进程(Process):是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器。
线程(Threading): 一条流水线的工作过程,cpu最小执行单位
线程与进程的区别可以归纳为以下4点:
并行:同时运行,只有具备多个cpu才能实现并行,利用了多核,利用了多核,多个任务真正的在同时运行
将多个cpu必须成高速公路上的多个车道,进程就好比每个车道上行驶的车辆,并行就是说,大家在自己的车道上行驶,会不影响,同时在开车。这就是并行
并发:伪并行,也提高了效率,遇到IO就切换,充分的利用了IO时间
即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
同步 : 要等待任务执行结果,才能进行下一个任务,其实就是一个程序结束才执行另外一个程序,串行的,不一定两个程序就有依赖关系。
异步 : 不需要等待任务的执行结果,继续执行自己的任务,不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。
阻塞 : 等待某个事件的发生而无法继续执行,阻塞的方法:input、time.sleep,socket中的recv、accept等等。
非阻塞 : 不等待
二.创建方式


#当前文件名称为test.py # from multiprocessing import Process # # def func(): # print(12345) # # if __name__ == '__main__': #windows 下才需要写这个,这和系统创建进程的机制有关系,不用深究,记着windows下要写就好啦 # #首先我运行当前这个test.py文件,运行这个文件的程序,那么就产生了进程,这个进程我们称为主进程 # # p = Process(target=func,) #将函数注册到一个进程中,p是一个进程对象,此时还没有启动进程,只是创建了一个进程对象。并且func是不加括号的,因为加上括号这个函数就直接运行了对吧。 # p.start() #告诉操作系统,给我开启一个进程,func这个函数就被我们新开的这个进程执行了,而这个进程是我主进程运行过程中创建出来的,所以称这个新创建的进程为主进程的子进程,而主进程又可以称为这个新进程的父进程。 #而这个子进程中执行的程序,相当于将现在这个test.py文件中的程序copy到一个你看不到的python文件中去执行了,就相当于当前这个文件,被另外一个py文件import过去并执行了。 #start并不是直接就去执行了,我们知道进程有三个状态,进程会进入进程的三个状态,就绪,(被调度,也就是时间片切换到它的时候)执行,阻塞,并且在这个三个状态之间不断的转换,等待cpu执行时间片到了。 # print('*' * 10) #这是主进程的程序,上面开启的子进程的程序是和主进程的程序同时运行的,我们称为异步
class MyProcess(Process): #自己写一个类,继承Process类 #我们通过init方法可以传参数,如果只写一个run方法,那么没法传参数,因为创建对象的是传参就是在init方法里面,面向对象的时候,我们是不是学过 def __init__(self,person): super().__init__() self.person=person def run(self): print(os.getpid()) print(self.pid) print(self.pid) print('%s 正在和女主播聊天' %self.person) # def start(self): # #如果你非要写一个start方法,可以这样写,并且在run方法前后,可以写一些其他的逻辑 # self.run() if __name__ == '__main__': p1=MyProcess('Jedan') p2=MyProcess('太白') p3=MyProcess('alexDSB') p1.start() #start内部会自动调用run方法 p2.start() # p2.run() p3.start() p1.join() p2.join() p3.join()
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('太白',)) t.start() print('主线程')
import time from threading import Thread class Sayhi(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): time.sleep(2) print('%s say hello' % self.name) if __name__ == '__main__': t = Sayhi('太白') t.start() print('主线程'
三.守护进程,守护线程
一定要在p.start()前设置,设置p为守护进程(守护线程),禁止p创建子进程(子线程),并且父进程代码执行结束,p即终止运行
import os import time from multiprocessing import Process class Myprocess(Process): def __init__(self,person): super().__init__() self.person = person def run(self): print(os.getpid(),self.name) print('%s正在和女主播聊天' %self.person) time.sleep(3) if __name__ == '__main__': p=Myprocess('太白') p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() # time.sleep(1) # 在sleep时linux下查看进程id对应的进程ps -ef|grep id print('主')
from threading import Thread from multiprocessing import Process import time def func1(): while True: print(666) time.sleep(0.5) def func2(): print('hello') time.sleep(3) if __name__ == '__main__': # t = Thread(target=func1,) # t.daemon = True #主线程结束,守护线程随之结束 # # t.setDaemon(True) #两种方式,和上面设置守护线程是一样的 # t.start() # t2 = Thread(target=func2,) #这个子线程要执行3秒,主线程的代码虽然执行完了,但是一直等着子线程的任务执行完毕,主线程才算完毕,因为通过结果你会发现我主线程虽然代码执行完毕了, # 但是主线程的的守护线程t1还在执行,说明什么,说明我的主线程还没有完毕,只不过是代码执行完了,一直等着子线程t2执行完毕,我主线程的守护线程才停止,说明子线程执行完毕之后,我的主线程才执行完毕 # t2.start() # print('主线程代码执行完啦!') p = Process(target=func1,) p.daemon = True p.start() p2 = Process(target=func2,) p2.start() time.sleep(1) #让主进程等1秒,为了能看到func1的打印效果 print('主进程代码执行完啦!') #通过结果你会发现,如果主进程的代码运行完毕了,那么主进程就结束了,因为主进程的守护进程p随着主进程的代码结束而结束了,守护进程被回收了,这和线程是不一样的,主线程的代码完了并不代表主线程运行完毕了,需要等着所有其他的非守护的子线程执行完毕才算完毕
信号量(Semaphore)
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
from multiprocessing import Process,Semaphore import time,random def go_ktv(sem,user): sem.acquire() print('%s 占到一间ktv小屋' %user) time.sleep(random.randint(0,3)) #模拟每个人在ktv中待的时间不同 sem.release() if __name__ == '__main__': sem=Semaphore(4) p_l=[] for i in range(13): p=Process(target=go_ktv,args=(sem,'user%s' %i,)) p.start() p_l.append(p) for i in p_l: i.join() print('============》')
from threading import Thread,Semaphore import threading import time # def func(): # if sm.acquire(): # print (threading.currentThread().getName() + ' get semaphore') # time.sleep(2) # sm.release() def func(): sm.acquire() print('%s get sm' %threading.current_thread().getName()) time.sleep(3) sm.release() if __name__ == '__main__': sm=Semaphore(5) for i in range(23): t=Thread(target=func) t.start()
事件
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
from multiprocessing import Process,Semaphore,Event import time,random e = Event() #创建一个事件对象 print(e.is_set()) #is_set()查看一个事件的状态,默认为False,可通过set方法改为True print('look here!') # e.set() #将is_set()的状态改为True。 # print(e.is_set())#is_set()查看一个事件的状态,默认为False,可通过set方法改为Tr # e.clear() #将is_set()的状态改为False # print(e.is_set())#is_set()查看一个事件的状态,默认为False,可通过set方法改为Tr e.wait() #根据is_set()的状态结果来决定是否在这阻塞住,is_set()=False那么就阻塞,is_set()=True就不阻塞 print('give me!!') #set和clear 修改事件的状态 set-->True clear-->False #is_set 用来查看一个事件的状态 #wait 依据事件的状态来决定是否阻塞 False-->阻塞 True-->不阻塞
from threading import Thread,Event import threading import time,random def conn_mysql(): count=1 while not event.is_set(): if count > 3: raise TimeoutError('链接超时') #自己发起错误 print('<%s>第%s次尝试链接' % (threading.current_thread().getName(), count)) event.wait(0.5) # count+=1 print('<%s>链接成功' %threading.current_thread().getName()) def check_mysql(): print('�33[45m[%s]正在检查mysql�33[0m' % threading.current_thread().getName()) t1 = random.randint(0,3) print('>>>>',t1) time.sleep(t1) event.set() if __name__ == '__main__': event=Event() check = Thread(target=check_mysql) conn1=Thread(target=conn_mysql) conn2=Thread(target=conn_mysql) check.start() conn1.start() conn2.start()
数据共享(Manager模块)
from multiprocessing import Manager,Process,Lock def work(d,lock): with lock: #不加锁而操作共享的数据,肯定会出现数据错乱 d['count']-=1 if __name__ == '__main__': lock=Lock() with Manager() as m: dic=m.dict({'count':100}) p_l=[] for i in range(100): p=Process(target=work,args=(dic,lock)) p_l.append(p) p.start() for p in p_l: p.join() print(dic)
from threading import Thread from multiprocessing import Process import os def work(): global n #修改全局变量的值 n=0 if __name__ == '__main__': # n=100 # p=Process(target=work) # p.start() # p.join() # print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=1 t=Thread(target=work) t.start() t.join() #必须加join,因为主线程和子线程不一定谁快,一般都是主线程快一些,所有我们要等子线程执行完毕才能看出效果 print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据 # 通过一个global就实现了全局变量的使用,不需要进程的IPC通信方法
队列(queue)
q = Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
#看下面的队列的时候,按照编号看注释 import time from multiprocessing import Process, Queue # 8. q = Queue(2) #创建一个Queue对象,如果写在这里,那么在windows还子进程去执行的时候,我们知道子进程中还会执行这个代码,但是子进程中不能够再次创建了,也就是这个q就是你主进程中创建的那个q,通过我们下面在主进程中先添加了一个字符串之后,在去开启子进程,你会发现,小鬼这个字符串还在队列中,也就是说,我们使用的还是主进程中创建的这个队列。 def f(q): # q = Queue() #9. 我们在主进程中开启了一个q,如果我们在子进程中的函数里面再开一个q,那么你下面q.put('姑娘,多少钱~')添加到了新创建的这q里里面了 q.put('姑娘,多少钱~') #4.调用主函数中p进程传递过来的进程参数 put函数为向队列中添加一条数据。 # print(q.qsize()) #6.查看队列中有多少条数据了 def f2(q): print('》》》》》》》》') print(q.get()) #5.取数据 if __name__ == '__main__': q = Queue() #1.创建一个Queue对象 q.put('小鬼') p = Process(target=f, args=(q,)) #2.创建一个进程 p2 = Process(target=f2, args=(q,)) #3.创建一个进程 p.start() p2.start() time.sleep(1) #7.如果阻塞一点时间,就会出现主进程运行太快,导致我们在子进程中查看qsize为1个。 # print(q.get()) #结果:小鬼 print(q.get()) #结果:姑娘,多少钱~ p.join()
class queue.Queue(maxsize=0) #先进先出
先进先出示例代码 class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue
q=queue.LifoQueue() #队列,类似于栈,栈我们提过吗,是不是先进后出的顺序啊
q.put('first')
q.put('second')
q.put('third')
# q.put_nowait()
print(q.get())
print(q.get())
print(q.get())
# q.get_nowait()
'''
结果(后进先出):
third
second
first
'''
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue
q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((-10,'a'))
q.put((-5,'a')) #负数也可以
# q.put((20,'ws')) #如果两个值的优先级一样,那么按照后面的值的acsii码顺序来排序,如果字符串第一个数元素相同,比较第二个元素的acsii码顺序
# q.put((20,'wd'))
# q.put((20,{'a':11})) #TypeError: unorderable types: dict() < dict() 不能是字典
# q.put((20,('w',1))) #优先级相同的两个数据,他们后面的值必须是相同的数据类型才能比较,可以是元祖,也是通过元素的ascii码顺序来排序
q.put((20,'b'))
q.put((20,'a'))
q.put((0,'b'))
q.put((30,'c'))
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
'''
结果(数字越小优先级越高,优先级高的优先出队):
'''
管道
会导致数据不安全
from multiprocessing import Process, Pipe def f(conn): conn.send("Hello 妹妹") #子进程发送了消息 conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() #建立管道,拿到管道的两端,双工通信方式,两端都可以收发消息 p = Process(target=f, args=(child_conn,)) #将管道的一段给子进程 p.start() #开启子进程 print(parent_conn.recv()) #主进程接受了消息 p.join()
四.生产者消费者模型
#程序中有两类角色
一类负责生产数据(生产者)
一类负责处理数据(消费者)
#引入生产者消费者模型为了解决的问题是:
平衡生产者与消费者之间的工作能力,从而提高程序整体处理数据的速度
#如何实现:
生产者<-->队列<——>消费者
#生产者消费者模型实现类程序的解耦和
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('�33[45m%s 吃 %s�33[0m' %(os.getpid(),res)) def producer(name,q): for i in range(2): time.sleep(random.randint(1,3)) res='%s%s' %(name,i) q.put(res) print('�33[44m%s 生产了 %s�33[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=('包子',q)) p2=Process(target=producer,args=('骨头',q)) p3=Process(target=producer,args=('泔水',q)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) c2=Process(target=consumer,args=(q,)) #开始 p1.start() p2.start() p3.start() c1.start() p1.join() #必须保证生产者全部生产完毕,才应该发送结束信号 p2.join() p3.join() q.put(None) #有几个消费者就应该发送几次结束信号None q.put(None) #发送结束信号 print('主')
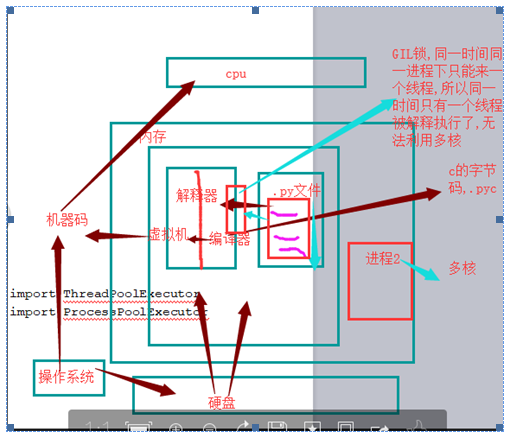
五.锁 GIL lock(同步锁互斥锁) 递归锁 (RLock),
GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责 这件事,只能用户自定义加锁处理,即Lock
#注意:首先在当前文件目录下创建一个名为db的文件 #文件db的内容为:{"count":1},只有这一行数据,并且注意,每次运行完了之后,文件中的1变成了0,你需要手动将0改为1,然后在去运行代码。 #注意一定要用双引号,不然json无法识别 #加锁保证数据安全,不出现混乱 from multiprocessing import Process,Lock import time,json,random #查看剩余票数 def search(): dic=json.load(open('db')) #打开文件,直接load文件中的内容,拿到文件中的包含剩余票数的字典 print('�33[43m剩余票数%s�33[0m' %dic['count']) #抢票 def get(): dic=json.load(open('db')) time.sleep(0.1) #模拟读数据的网络延迟,那么进程之间的切换,导致所有人拿到的字典都是{"count": 1},也就是每个人都拿到了这一票。 if dic['count'] >0: dic['count']-=1 time.sleep(0.2) #模拟写数据的网络延迟 json.dump(dic,open('db','w')) #最终结果导致,每个人显示都抢到了票,这就出现了问题~ print('�33[43m购票成功�33[0m') else: print('sorry,没票了亲!') def task(lock): search() #因为抢票的时候是发生数据变化的时候,所有我们将锁加加到这里 lock.acquire() get() lock.release() if __name__ == '__main__': lock = Lock() #创建一个锁 for i in range(3): #模拟并发100个客户端抢票 p=Process(target=task,args=(lock,)) #将锁作为参数传给task函数 p.start() #看结果分析:只有一个人抢到了票 # 剩余票数1 # 剩余票数1 # 剩余票数1 # 购票成功 #幸运的人儿 # sorry,没票了亲! # sorry,没票了亲!
import time from threading import Thread,RLock fork_lock = noodle_lock = RLock() def eat1(name): noodle_lock.acquire() print('%s 抢到了面条'%name) fork_lock.acquire() print('%s 抢到了叉子'%name) print('%s 吃面'%name) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() print('%s 抢到了叉子' % name) time.sleep(1) noodle_lock.acquire() print('%s 抢到了面条' % name) print('%s 吃面' % name) noodle_lock.release() fork_lock.release() for name in ['taibai','wulaoban']: t1 = Thread(target=eat1,args=(name,)) t1.start() for name in ['alex','peiqi']: t2 = Thread(target=eat2,args=(name,)) t2.start()
六.进程池,线程池
p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 '''需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()''' p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 '''此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。''' p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用 方法apply_async()和map_async()的返回值是AsyncResul的实例obj。实例具有以下方法 obj.get():返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发。 obj.ready():如果调用完成,返回True obj.successful():如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常 obj.wait([timeout]):等待结果变为可用。 obj.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数
#一:使用进程池(异步调用,apply_async) #coding: utf-8 from multiprocessing import Process,Pool import time def func(msg): print( "msg:", msg) time.sleep(1) return msg if __name__ == "__main__": pool = Pool(processes = 3) res_l=[] for i in range(10): msg = "hello %d" %(i) res=pool.apply_async(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去 res_l.append(res) # s = res.get() #如果直接用res这个结果对象调用get方法获取结果的话,这个程序就变成了同步,因为get方法直接就在这里等着你创建的进程的结果,第一个进程创建了,并且去执行了,那么get就会等着第一个进程的结果,没有结果就一直等着,那么主进程的for循环是无法继续的,所以你会发现变成了同步的效果 print("==============================>") #没有后面的join,或get,则程序整体结束,进程池中的任务还没来得及全部执行完也都跟着主进程一起结束了 pool.close() #关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束 print(res_l) #看到的是<multiprocessing.pool.ApplyResult object at 0x10357c4e0>对象组成的列表,而非最终的结果,但这一步是在join后执行的,证明结果已经计算完毕,剩下的事情就是调用每个对象下的get方法去获取结果 for i in res_l: print(i.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get #二:使用进程池(同步调用,apply) #coding: utf-8 from multiprocessing import Process,Pool import time def func(msg): print( "msg:", msg) time.sleep(0.1) return msg if __name__ == "__main__": pool = Pool(processes = 3) res_l=[] for i in range(10): msg = "hello %d" %(i) res=pool.apply(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去 res_l.append(res) #同步执行,即执行完一个拿到结果,再去执行另外一个 print("==============================>") pool.close() pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束 print(res_l) #看到的就是最终的结果组成的列表 for i in res_l: #apply是同步的,所以直接得到结果,没有get()方法 print(i)
from multiprocessing import Pool import time,random import requests import re def get_page(url,pattern): response=requests.get(url) if response.status_code == 200: return (response.text,pattern) def parse_page(info): page_content,pattern=info res=re.findall(pattern,page_content) for item in res: dic={ 'index':item[0], 'title':item[1], 'actor':item[2].strip()[3:], 'time':item[3][5:], 'score':item[4]+item[5] } print(dic) if __name__ == '__main__': pattern1=re.compile(r'<dd>.*?board-index.*?>(d+)<.*?title="(.*?)".*?star.*?>(.*?)<.*?releasetime.*?>(.*?)<.*?integer.*?>(.*?)<.*?fraction.*?>(.*?)<',re.S) url_dic={ 'http://maoyan.com/board/7':pattern1, } p=Pool() res_l=[] for url,pattern in url_dic.items(): res=p.apply_async(get_page,args=(url,pattern),callback=parse_page) res_l.append(res) for i in res_l: i.get() # res=requests.get('http://maoyan.com/board/7') # print(re.findall(pattern,res.text))
import os from multiprocessing import Pool def func1(n): print('func1>>',os.getpid()) print('func1') return n*n def func2(nn): print('func2>>',os.getpid()) print('func2') print(nn) # import time # time.sleep(0.5) if __name__ == '__main__': print('主进程:',os.getpid()) p = Pool(5) #args里面的10给了func1,func1的返回值作为回调函数的参数给了callback对应的函数,不能直接给回调函数直接传参数,他只能是你任务函数func1的函数的返回值 # for i in range(10,20): #如果是多个进程来执行任务,那么当所有子进程将结果给了回调函数之后,回调函数又是在主进程上执行的,那么就会出现打印结果是同步的效果。我们上面func2里面注销的时间模块打开看看 # p.apply_async(func1,args=(i,),callback=func2) p.apply_async(func1,args=(10,),callback=func2) p.close() p.join() #结果 # 主进程: 11852 #发现回调函数是在主进程中完成的,其实如果是在子进程中完成的,那我们直接将代码写在子进程的任务函数func1里面就行了,对不对,这也是为什么称为回调函数的原因。 # func1>> 17332 # func1 # func2>> 11852 # func2 # 100
#server>>>>>>>>>> #Pool内的进程数默认是cpu核数,假设为4(查看方法os.cpu_count()) #开启6个客户端,会发现2个客户端处于等待状态 #在每个进程内查看pid,会发现pid使用为4个,即多个客户端公用4个进程 from socket import * from multiprocessing import Pool import os server=socket(AF_INET,SOCK_STREAM) server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn): print('进程pid: %s' %os.getpid()) while True: try: msg=conn.recv(1024) if not msg:break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': p=Pool(4) while True: conn,*_=server.accept() p.apply_async(talk,args=(conn,)) # p.apply(talk,args=(conn,client_addr)) #同步的话,则同一时间只有一个客户端能访问 #client.>>>>>>>>>>>>>. from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
import time import os import threading from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def func(n): time.sleep(2) print('%s打印的:'%(threading.get_ident()),n) return n*n tpool = ThreadPoolExecutor(max_workers=5) #默认一般起线程的数据不超过CPU个数*5 # tpool = ProcessPoolExecutor(max_workers=5) #进程池的使用只需要将上面的ThreadPoolExecutor改为ProcessPoolExecutor就行了,其他都不用改 #异步执行 t_lst = [] for i in range(5): t = tpool.submit(func,i) #提交执行函数,返回一个结果对象,i作为任务函数的参数 def submit(self, fn, *args, **kwargs): 可以传任意形式的参数 t_lst.append(t) # # print(t.result()) #这个返回的结果对象t,不能直接去拿结果,不然又变成串行了,可以理解为拿到一个号码,等所有线程的结果都出来之后,我们再去通过结果对象t获取结果 tpool.shutdown() #起到原来的close阻止新任务进来 + join的作用,等待所有的线程执行完毕 print('主线程') for ti in t_lst: print('>>>>',ti.result()) # 我们还可以不用shutdown(),用下面这种方式 # while 1: # for n,ti in enumerate(t_lst): # print('>>>>', ti.result(),n) # time.sleep(2) #每个两秒去去一次结果,哪个有结果了,就可以取出哪一个,想表达的意思就是说不用等到所有的结果都出来再去取,可以轮询着去取结果,因为你的任务需要执行的时间很长,那么你需要等很久才能拿到结果,通过这样的方式可以将快速出来的结果先拿出来。如果有的结果对象里面还没有执行结果,那么你什么也取不到,这一点要注意,不是空的,是什么也取不到,那怎么判断我已经取出了哪一个的结果,可以通过枚举enumerate来搞,记录你是哪一个位置的结果对象的结果已经被取过了,取过的就不再取了 #结果分析: 打印的结果是没有顺序的,因为到了func函数中的sleep的时候线程会切换,谁先打印就没准儿了,但是最后的我们通过结果对象取结果的时候拿到的是有序的,因为我们主线程进行for循环的时候,我们是按顺序将结果对象添加到列表中的。 # 37220打印的: 0 # 32292打印的: 4 # 33444打印的: 1 # 30068打印的: 2 # 29884打印的: 3 # 主线程 # >>>> 0 # >>>> 1 # >>>> 4 # >>>> 9 # >>>> 16
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from multiprocessing import Pool import requests import json import os def get_page(url): print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} def parse_page(res): res=res.result() print('<进程%s> parse %s' %(os.getpid(),res['url'])) parse_res='url:<%s> size:[%s] ' %(res['url'],len(res['text'])) with open('db.txt','a') as f: f.write(parse_res) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] # p=Pool(3) # for url in urls: # p.apply_async(get_page,args=(url,),callback=pasrse_page) # p.close() # p.join() p=ProcessPoolExecutor(3) for url in urls: p.submit(get_page,url).add_done_callback(parse_page) #parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
七. 协程
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。、
总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
Greenlet
如果我们在单个线程内有20个任务,要想实现在多个任务之间切换,使用yield生成器的方式过于麻烦(需要先得到初始化一次的生成器,然后再调用 send。。。非常麻烦),而使用greenlet模块可以非常简单地实现这20个任务直接的切换
#安装
pip3 install greenlet

from greenlet import greenlet
def eat(name):
print('%s eat 1' %name) #2
g2.switch('taibai') #3
print('%s eat 2' %name) #6
g2.switch() #7
def play(name):
print('%s play 1' %name) #4
g1.switch() #5
print('%s play 2' %name) #8
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('taibai')#可以在第一次switch时传入参数,以后都不需要 1
Gevent
#安装
pip3 install gevent
用法 g1=gevent.spawn(func,1,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束,上面只是创建协程对象,这个join才是去执行 g2.join() #等待g2结束 有人测试的时候会发现,不写第二个join也能执行g2,是的,协程帮你切换执行了,但是你会发现,如果g2里面的任务执行的时间长,但是不写join的话,就不会执行完等到g2剩下的任务了 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
from gevent import monkey;monkey.patch_all() #必须写在最上面,这句话后面的所有阻塞全部能够识别了 import gevent #直接导入即可 import time def eat(): #print() print('eat food 1') time.sleep(2) #加上mokey就能够识别到time模块的sleep了 print('eat food 2') def play(): print('play 1') time.sleep(1) #来回切换,直到一个I/O的时间结束,这里都是我们个gevent做得,不再是控制不了的操作系统了。 print('play 2') g1=gevent.spawn(eat) g2=gevent.spawn(play_phone) gevent.joinall([g1,g2]) print('主')
from gevent import spawn,joinall,monkey;monkey.patch_all() import time def task(pid): """ Some non-deterministic task """ time.sleep(0.5) print('Task %s done' % pid) def synchronous(): for i in range(10): task(i) def asynchronous(): g_l=[spawn(task,i) for i in range(10)] joinall(g_l) if __name__ == '__main__': print('Synchronous:') synchronous() print('Asynchronous:') asynchronous() #上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
from gevent import monkey;monkey.patch_all() import gevent import requests import time def get_page(url): print('GET: %s' %url) response=requests.get(url) if response.status_code == 200: print('%d bytes received from %s' %(len(response.text),url)) start_time=time.time() gevent.joinall([ gevent.spawn(get_page,'https://www.python.org/'), gevent.spawn(get_page,'https://www.yahoo.com/'), gevent.spawn(get_page,'https://github.com/'), ]) stop_time=time.time() print('run time is %s' %(stop_time-start_time))
八.IO多路复用
同步:提交一个任务之后要等待这个任务执行完毕
异步:只管提交任务,不等待这个任务执行完毕就可以去做其他的事情
阻塞:recv、recvfrom、accept,线程阶段 运行状态-->阻塞状态-->就绪
非阻塞:没有阻塞状态
在一个线程的IO模型中,我们recv的地方阻塞,我们就开启多线程,但是不管你开启多少个线程,这个recv的时间是不是没有被规避掉,不管是多线程还是多进程都没有规避掉这个IO时间。
selectors模块
#服务端 from socket import * import selectors sel=selectors.DefaultSelector() def accept(server_fileobj,mask): conn,addr=server_fileobj.accept() sel.register(conn,selectors.EVENT_READ,read) def read(conn,mask): try: data=conn.recv(1024) if not data: print('closing',conn) sel.unregister(conn) conn.close() return conn.send(data.upper()+b'_SB') except Exception: print('closing', conn) sel.unregister(conn) conn.close() server_fileobj=socket(AF_INET,SOCK_STREAM) server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) server_fileobj.bind(('127.0.0.1',8088)) server_fileobj.listen(5) server_fileobj.setblocking(False) #设置socket的接口为非阻塞 sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept while True: events=sel.select() #检测所有的fileobj,是否有完成wait data的 for sel_obj,mask in events: callback=sel_obj.data #callback=accpet callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1) #客户端 from socket import * c=socket(AF_INET,SOCK_STREAM) c.connect(('127.0.0.1',8088)) while True: msg=input('>>: ') if not msg:continue c.send(msg.encode('utf-8')) data=c.recv(1024) print(data.decode('utf-8'))