我理解的推荐系统本质是一种排序方式。排序的规则是按照我们预测的用户喜好程度的一个排序的列表,而如何定义用户的喜好程度是推荐系统要解决的核心问题。机器学习的算法只是推荐系统的一部分。构建一个完整的推荐系统将会使用到多个大数据的组件,从而在实际的项目中实现数据的存储,计算,模型更新。
一、什么是推荐系统
举个例子,我使用读书,如果是去传统的图书馆,面对一个个的书架我会迷茫拿出哪一本来阅读。但是现在登录个阅读软件或者使用kindle,他们会给出一些阅读建议。
这些建议的基础就是推荐系统,底层通常是使用一些机器学习的方法提供推荐结果。推荐系统通过记录我们不断的阅读,收藏等操作,预测我们的需求或者喜好给予合适的建议。
二、推荐系统总览
推荐系统是一整个技术架构,并非仅仅是花哨的机器学习算法。推荐系统根据不同的业务会有不同的技术架构,但大多数的推荐系统一般遵循以下的技术架构。后边将会从宏观上介绍着各个组成部分的作用。
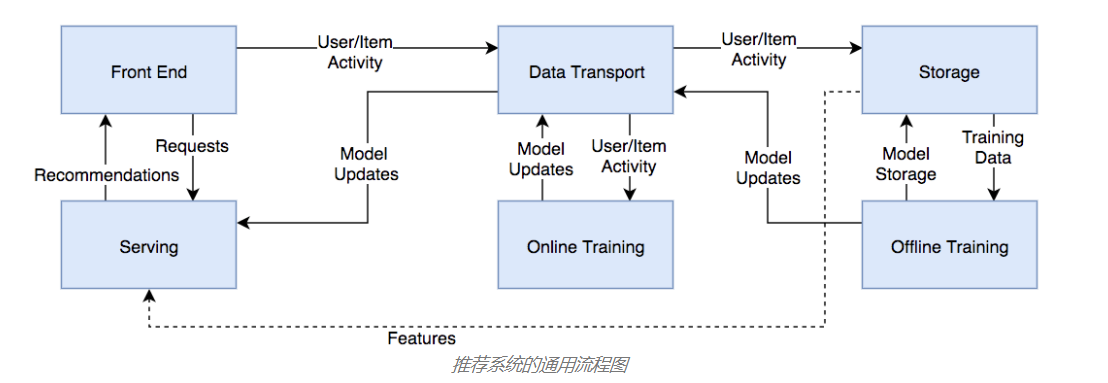
当下深度学习的流行,使得计算机视觉和自然语言处理技术更加成熟,因此在推荐系统中使用深度学习技术会有较好的效果。本文也将介绍除了使用协同过滤构建传统的推荐系统,也会介绍如何整合目前比较流行的深度学习技术来获得更好的推荐效果。
三、机器学习
机器学习的组件需要完成推荐模型的训练。选择适用的算法从历史数据学习并生成可以部署的推荐模型,调用推荐模型从而向用户提供个性化建议。值得注意的是,推荐算法的输出类型将会影响后续对它的调用和存储,因为用户通过不断的使用我们的产品会不断产生新的行为数据。
理想情况下,我们希望每产生新数据后可以重新优化我们的已有模型,但实际上难以实现,因为训练模型需要一定的时长。目前在实践中比较通用的解决方案是使用Lambda体系结构。
Lambda体系结构适用于在线学习也适用于离线学习。在线学习使用的数据是新产生的数据,数据量较小训练更快可以提供接近实时推荐结果。离线学习使用所有的历史数据,训练的频次较低。
离线训练
离线训练是机器学习推荐算法的主要学习机制。此过程通常涉及传统的机器学习算法,即在训练集上训练模型,进行交叉验证以选择最佳超参数,并将该模型导出为可供服务层使用的模型。
系统应该实现自动训练模型和选择最佳模型。并且能够按照合适的频率定时进行训练。因为离线模型训练使用所有的历史数据通常训练过程需要较长的时间,所以可以使用作业调度来完成,如使用oozie或者自己写定时启动训练程序的脚本。目前常用的方法有使用Spark DStream操作,使用用户近期产生的新数据与Hadoop文件系统(HDFS)的历史数据相结合。使用Spark MLlib中交替最小二乘(ALS)算法训练数据。 
ALS是一种矩阵分解算法,它可以用数字表示每个用户和每个物品。将用户和物品在k维空间中表示,在此空间中的距离用来表示用户的偏好。因此靠近某个用户的物品可能是该用户可能感兴趣的物品。ALS模型的输出是每个用户和每个物品的k维向量,通常存储为两个矩阵,一个用于用户向量一个用于物品向量。
选择MLlib中的ALS算法只是举个例子,也可以选择其他的推荐算法或者自己设计算法,使用ALS的优点是相对比较简单,易于实现,通用性也较好。
在线训练

在线训练的过程是将根据最近产生的数据训练出来的模型作为数据流更新到系统中,这隐含着两个需求,一是我们需要在内存中快速更新模型,当新数据到达时可以从中学习新的模型参数。二是我们需要一个支持增量更新的算法。
使用ALS算法利用最小二乘对用户和物品参数进行近似的在线更新,这种方式可以用来实时合并新数据,具体做法就是我们将当前的用户和物品矩阵放在内存中,通过SparkStreaming进行实时更新,训练后对模型进行更新。
在线更新模型可以在一定程度上解决冷启动问题,当用户第一次登陆时,我们没有用户行为数据,可能会使用一些普适性较好的推荐,然而使用在线更新意味着用户只要与第一个商品有了行为,就可以立即改善预测模型提供个性化推荐。
四、Web服务
Web服务用于建立用户和应用程序的交互关系,Web服务常用的可以选择使用JavaEE,需要满足能够向多个用户提供建议,并应该设有埋点,将新的用户行为数据采集下来推送到kafka用于在线训练更新模型。
五、部署
部署推荐模型需要考虑应用程序的时效性要求和数据规模,通常的做法是将ALS矩阵存储在内存中,使用LSH(局部敏感散列)+KNN(近邻搜索,可用于快速预测)。通过读取离线训练模型并整合在线训练的模型。
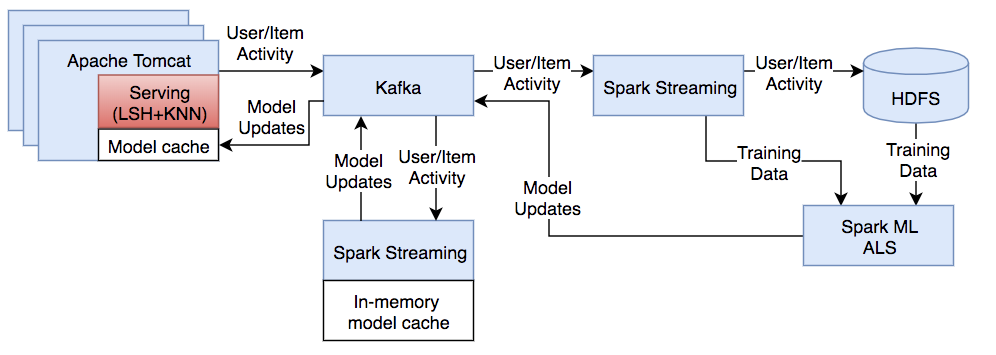
如上图是整个推荐系统的基本架构。
六、集成深度学习
我们构建一个推荐应用程序,可能会需要使用不同的机器学习算法去试验,从中选择最佳的推荐模型,深度学习技术虽然先进,但是使用传统的算法模型如ALS迭代会更简单。
更换模型时,如果模型的输入输出一致,可以直接替换,在架构中可以直接使用心得深度学习模型替换ALS,对于离线部分,我们可以在集群中配置一个或者多个GPU,使用TensorFlow或者Keras进行离线批量训练,或者使用基于Spark的深度学习框架如deeplearning4j。并将离线训练的程序在Spark集群上提交运行,神经网络默认是使用梯度下降逐步进行训练,因此在线模型训练也可以替换,在每个时间间隔内新产生的数据作为小批量的训练数据,并且可以通过向前和向后传递模型来更新模型。这部分不需要GPU加速。
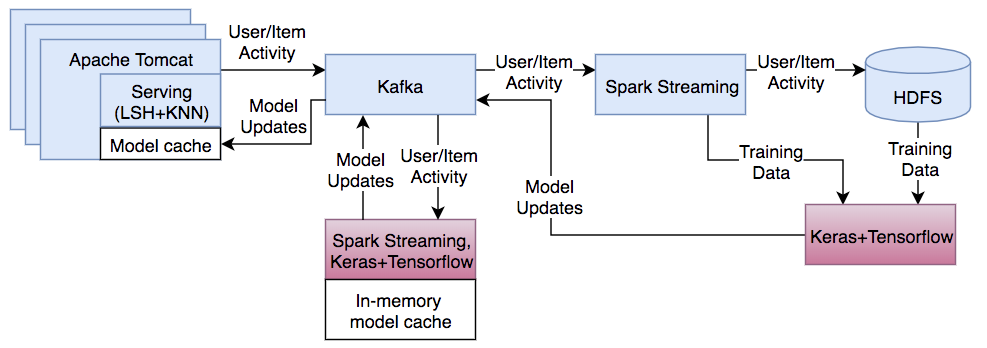
在生产环境构建推荐系统时,最好是通过使用矩阵分解这种简单模型入手,如果简单模型达不到好的推荐效果,再考虑转向使用更复杂的技术,在大多数情况下,不会使用深度学习取代矩阵分解,而是使用深度学习模型与协同过滤方法结合使用构建混合模型。
一个好的推荐系统不仅仅是只需要一个好的推荐算法,而且还需要一个能根据用户需求随时调整适应的基础架构,如果说不能有效的结合生产环境,再复杂再高端的算法也是无用的。我认为建模技术固然重要,但我们首先应该关注的整个系统的基础架构,随着业务发展,系统的需求发生变化难以避免。所以推荐系统架构应该支持扩展和修改现有的算法模型,如果说需要更多的个性化推荐,我们可以在不影响基础架构设计的前提下,增加深度学习模型用于提升推荐效果。