Accumulators and Broadcast Variables
这些不能从checkpoint重新恢复
如果想启动检查点的时候使用这两个变量,就需要创建这写变量的懒惰的singleton实例。
下面是一个例子:
def getWordBlacklist(sparkContext):if ('wordBlacklist' not in globals()):globals()['wordBlacklist'] = sparkContext.broadcast(["a", "b", "c"])return globals()['wordBlacklist']def getDroppedWordsCounter(sparkContext):if ('droppedWordsCounter' not in globals()):globals()['droppedWordsCounter'] = sparkContext.accumulator(0)return globals()['droppedWordsCounter']def echo(time, rdd):# Get or register the blacklist Broadcastblacklist = getWordBlacklist(rdd.context)# Get or register the droppedWordsCounter AccumulatordroppedWordsCounter = getDroppedWordsCounter(rdd.context)# Use blacklist to drop words and use droppedWordsCounter to count themdef filterFunc(wordCount):if wordCount[0] in blacklist.value:droppedWordsCounter.add(wordCount[1])Falseelse:Truecounts = "Counts at time %s %s" % (time, rdd.filter(filterFunc).collect())wordCounts.foreachRDD(echo)
DataFrame and SQL Operations
通过创建SparkSession的懒惰的singleton实例,可以从失败中恢复。
# Lazily instantiated global instance of SparkSessiondef getSparkSessionInstance(sparkConf):if ('sparkSessionSingletonInstance' not in globals()):globals()['sparkSessionSingletonInstance'] = SparkSession.builder.config(conf=sparkConf).getOrCreate()return globals()['sparkSessionSingletonInstance']...# DataFrame operations inside your streaming programwords = ... # DStream of stringsdef process(time, rdd):print("========= %s =========" % str(time))try:# Get the singleton instance of SparkSessionspark = getSparkSessionInstance(rdd.context.getConf())# Convert RDD[String] to RDD[Row] to DataFramerowRdd = rdd.map(lambda w: Row(word=w))wordsDataFrame = spark.createDataFrame(rowRdd)# Creates a temporary view using the DataFramewordsDataFrame.createOrReplaceTempView("words")# Do word count on table using SQL and print itwordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word")wordCountsDataFrame.show()except:passwords.foreachRDD(process)
MLlib Operations
streaming machine learning algorithms (e.g. Streaming Linear Regression, Streaming KMeans, etc.)
can simultaneously learn from the streaming data as well as apply the model on the streaming data
for a much larger class of machine learning algorithms
you can learn a learning model offline (i.e. using historical data) and then apply the model online on streaming data
Caching / Persistence
DStreams also allow developers to persist the stream’s data in memory
using the persist() method on a DStream will automatically persist every RDD of that DStream in memory
For window-based operations like reduceByWindow and reduceByKeyAndWindow and state-based operations like updateStateByKey, this is implicitly true(对这些操作,默认实现自动的缓存)
For input streams that receive data over the network (such as, Kafka, Flume, sockets, etc.), the default persistence level is set to replicate the data to two nodes for fault-tolerance.(网络数据,默认存两份来容错)
You can mark an RDD to be persisted using the persist() or cache() methods on it.
levels are set by passing a StorageLevel object to persist()
The cache() method is a shorthand for using the default storage level, which is StorageLevel.MEMORY_ONLY
unlike RDDs, the default persistence level of DStreams keeps the data serialized in memory
Checkpointing
Spark Streaming needs to checkpoint enough information to a fault- tolerant storage system such that it can recover from failures,There are two types of data that are checkpointed.
- Metadata checkpointing - Saving of the information defining the streaming computation to fault-tolerant storage like HDFS. This is used to recover from failure of the node running the driver of the streaming application. Metadata includes:Configuration - The configuration that was used to create the streaming application.DStream operations - The set of DStream operations that define the streaming application.Incomplete batches - Batches whose jobs are queued but have not completed yet.
- Data checkpointing - Saving of the generated RDDs to reliable storage.
When to enable Checkpointing
- Usage of stateful transformations - If either updateStateByKey or reduceByKeyAndWindow (with inverse function) is used in the application, then the checkpoint directory must be provided to allow for periodic(周期的) RDD checkpointing.
- Recovering from failures of the driver running the application - Metadata checkpoints are used to recover with progress information.
How to configure Checkpointing
Checkpointing can be enabled by setting a directory in a fault-tolerant, reliable file system (e.g., HDFS, S3, etc.) to which the checkpoint information will be saved
done by using streamingContext.checkpoint(checkpointDirectory)
if you want to make the application recover from driver failures, you should rewrite your streaming application to have the following behavior:
- When the program is being started for the first time, it will create a new StreamingContext, set up all the streams and then call start().
- When the program is being restarted after failure, it will re-create a StreamingContext from the checkpoint data in the checkpoint directory.
This behavior is made simple by using StreamingContext.getOrCreate
# Function to create and setup a new StreamingContextdef functionToCreateContext():sc = SparkContext(...) # new contextssc = new StreamingContext(...)lines = ssc.socketTextStream(...) # create DStreams...ssc.checkpoint(checkpointDirectory) # set checkpoint directoryreturn ssc# Get StreamingContext from checkpoint data or create a new onecontext = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)# Do additional setup on context that needs to be done,# irrespective of whether it is being started or restartedcontext. ...# Start the contextcontext.start()context.awaitTermination()
如果checkpointDirectory存在,会从检查点重新新建
如果路径不存在,函数functionToCreateContext会创建新的context
You can also explicitly(明确的) create a StreamingContext from the checkpoint data and start the computation by using
StreamingContext.getOrCreate(checkpointDirectory, None).
In addition to using getOrCreate one also needs to ensure that the driver process gets restarted automatically on failure,This is further discussed in the Deployment section
At small batch sizes (say 1 second), checkpointing every batch may significantly reduce operation throughput。
he default interval is a multiple of the batch interval that is at least 10 seconds
It can be set by using dstream.checkpoint(checkpointInterval)
Typically, a checkpoint interval of 5 - 10 sliding intervals of a DStream is a good setting to try.
Deploying Applications
Requirements
- Cluster with a cluster manager
- Package the application JAR
If you are using spark-submit to start the application, then you will not need to provide Spark and Spark Streaming in the JAR. However, if your application uses advanced sources (e.g. Kafka, Flume), then you will have to package the extra artifact they link to, along with their dependencies, in the JAR that is used to deploy the application. - Configuring sufficient memory for the executors
Note that if you are doing 10 minute window operations, the system has to keep at least last 10 minutes of data in memory. So the memory requirements for the application depends on the operations used in it. - Configuring checkpointing
- Configuring automatic restart of the application driver
- Spark Standalone
the Standalone cluster manager can be instructed to supervise the driver, and relaunch it if the driver fails either due to non-zero exit code, or due to failure of the node running the driver. - YARN automatically restarting an application
- Mesos Marathon has been used to achieve this with Mesos
- Configuring write ahead logs
If enabled, all the data received from a receiver gets written into a write ahead log in the configuration checkpoint directory. - Setting the max receiving rate
Upgrading Application Code
两种机制去更新代码
- 更新的应用和旧的应用并行的执行,Once the new one (receiving the same data as the old one) has been warmed up and is ready for prime time, the old one be can be brought down.这要求,数据源可以向两个地方发送数据。
- 优雅的停止,就是处理完接受到的数据之后再停止。ensure data that has been received is completely processed before shutdown。Then the upgraded application can be started, which will start processing from the same point where the earlier application left off.为了实现这个需要数据源的数据是可以缓存的。
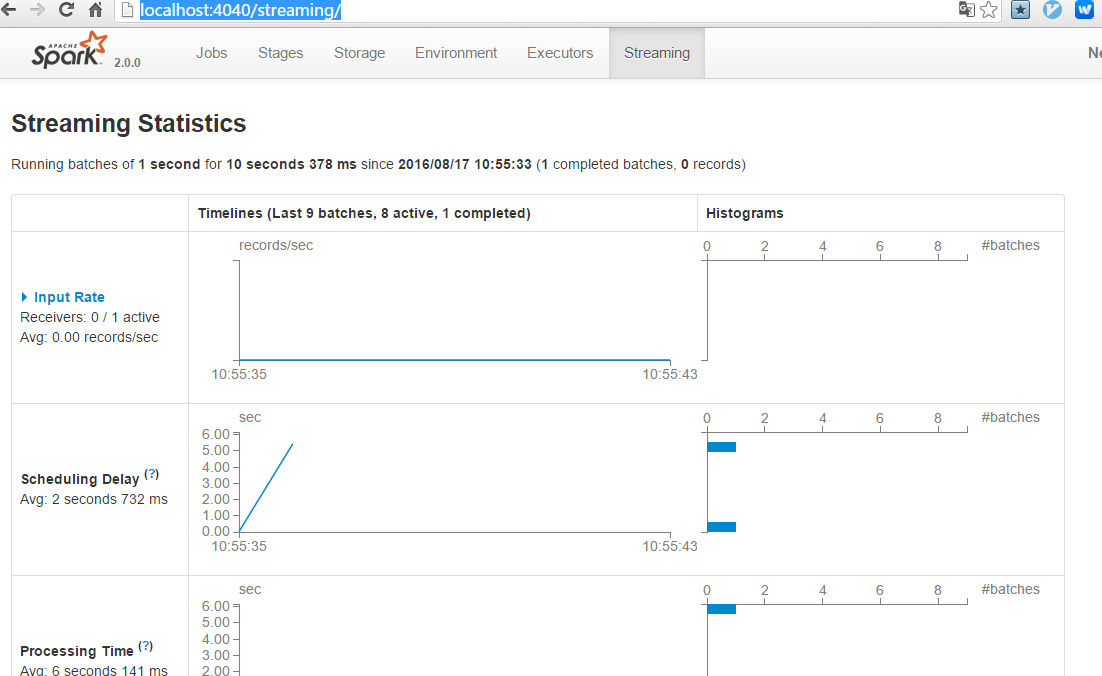
Monitoring Applications
Performance Tuning
目的或者方式
- Reducing the processing time of each batch of data by efficiently using cluster resources.
- Setting the right batch size such that the batches of data can be processed as fast as they are received (that is, data processing keeps up with the data ingestion).
Level of Parallelism in Data Receiving
Level of Parallelism in Data Processing