这个我们要下载视频,那么肯定首先去找抖音视频的url地址,那么这个地址肯定在json格式的数据包中,所以我们就去专门查看json格式数据包
这个怎么找我就不用了,直接看结果吧
你找json包,可以选大的去看,毕竟包含视频地址这些json包肯定不会小

视频播放地址可能有好多链接,这里我只是拿我的做一个例子。我原本用的是下面视频下载那个地址,但是会匹配到好多没用的地址
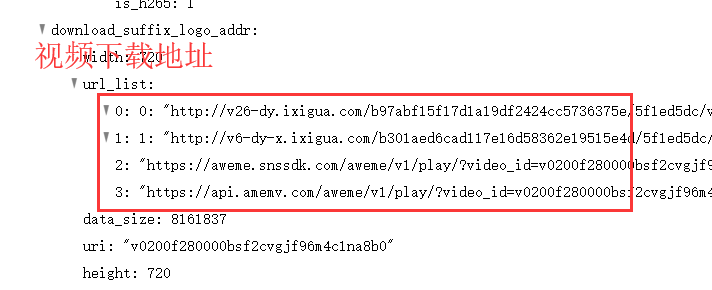
视频下载url和视频播放url,我们选择视频播放url,毕竟在抖音上有些视频不允许下载,但是可以播放(^_^)
你发现视频播放url里面包含0,1两个可以播放地址,2,3那两个地址我打开试了试没用。
0,1两个播放地址,随便选一个就行(这里我选的0号),数据包给出两个地址,应该是防止万一一个地址不能用(管它呢,随便用一个就行)
然后就需要把这个json数据弄到本地,不能通过python的request库访问来获取,因为我试了试,弄不到。。。
那这里有两种方法,一种是复制后,粘贴到txt文件中。第二种就是在fiddler中增添规则,让fiddler一遇见json数据包就保存到本地
抓取规则如下:
if (oSession.uriContains("https://api-eagle.amemv.com/aweme/v1/feed/")){ var strBody=oSession.GetResponseBodyAsString(); var sps = oSession.PathAndQuery.slice(-58,); //FiddlerObject.alert(sps) var filename = "C:/Users/HEXU/Desktop/抖音数据爬取/抖音爬取资料/raw_data" + "/" + sps + ".json"; var curDate = new Date(); var sw : System.IO.StreamWriter; if (System.IO.File.Exists(filename)){ sw = System.IO.File.AppendText(filename); sw.Write(strBody); } else{ sw = System.IO.File.CreateText(filename); sw.Write(strBody); } sw.Close(); sw.Dispose(); }
放到下图所示位置
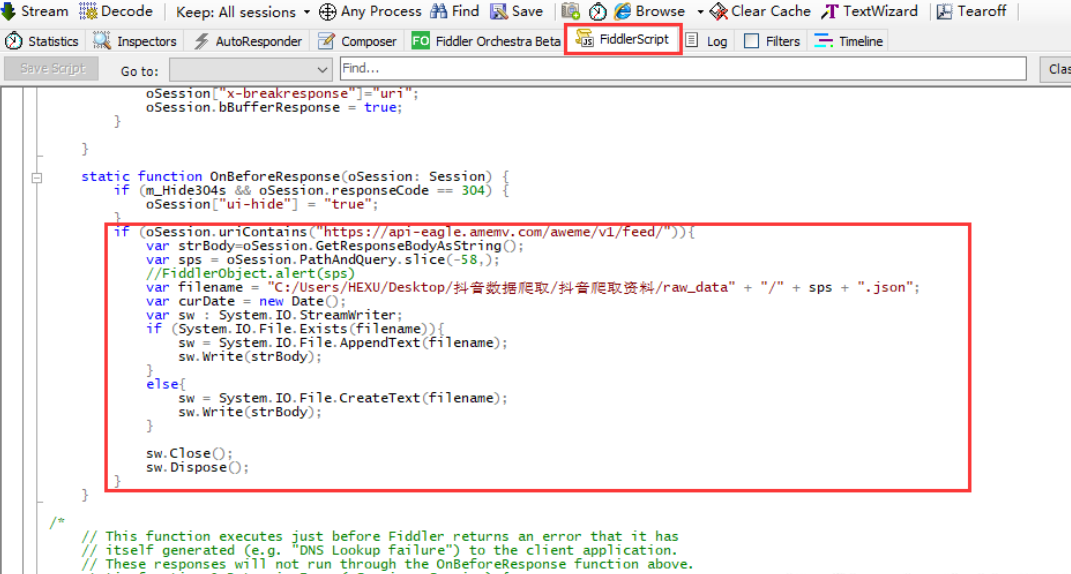
这个脚本有两点需要修改的:
(1)第一行的网址:
这个是从视频包的url中摘出来的,抖音会时不时更新这个url,所以不能用了也要去更新:

2)路径,那个是我设置json包保存的地址,自己一定要去修改,并创建文件夹,修改完记着点保存。
我这里用的是最lou的方法(也就是粘贴复制),这种方法我没弄好,具体请见:https://blog.csdn.net/weixin_43582101/article/details/89600007
之后我就是把json数据放到文本里面,在python中读入,然后用re模块的findall方法获取其中链接
代码:
import requests import re headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } def down_video(url,num): con = requests.get(url,headers=headers).content with open(str(num)+'.mp4','wb') as f: f.write(con) file =open('E:/pycharm/xiang1/python-json/2.json','r',encoding='utf-8',errors='ignore') context = file.read() pattern = 'play_addr_lowbr:.*?list:.*?"(.*?)"' result = re.findall(pattern,context,re.S) ans = 1 for i in result: print(i) down_video(i,ans) ans+=1
同时pycharm控制台也会输出链接:
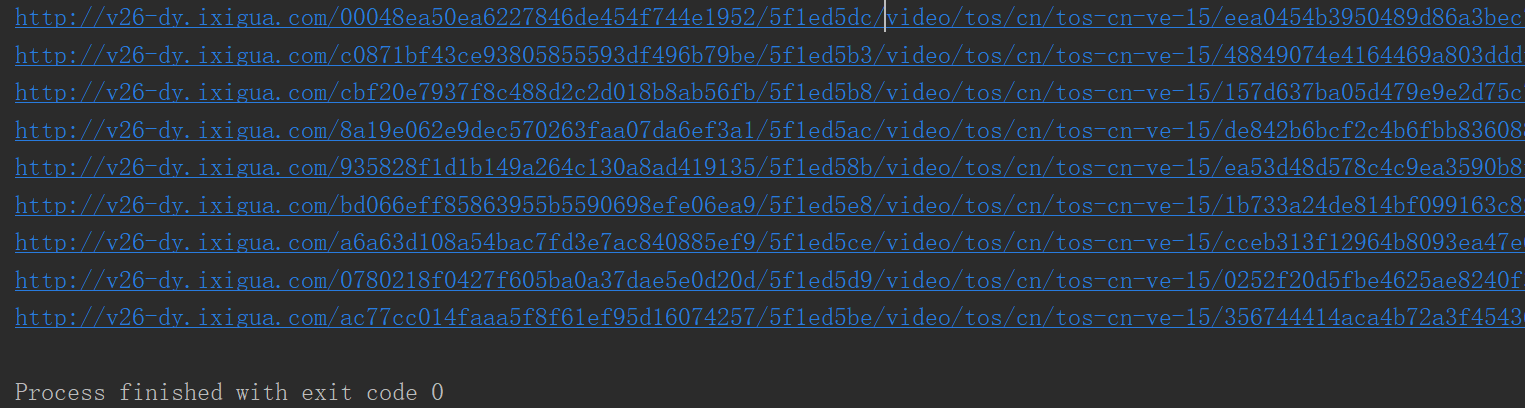
但是要注意,这些链接都有时效,过一段时间就不能用了
运行后结果: