存储引擎
不同的数据有不同的处理机制
mysql存储引擎
Innodb:默认的存储引擎 支持事务,支持行锁,支持外键 查询速度较myisam慢 但是更安全
myisam:mysql老版本用的存储引擎,在查询速度上,比Innodb快
memory:内存引擎(数据全部存在内存中)
blackhole:无论存什么 都立马消失(黑洞)
Innodb 建表时会建俩个文件,第一个是表结构,第二个是真实数据
myisam 建表时会建三个文件,第一个是表结构,第二个是真实数据,第三个是索引,类似于书的目录,加快查找速度
memory 和 blackhole 都只有一个表结构文件
查看所有的存储引擎
show engines;
查看不同存储引擎存储表结构文件特点
create table t1(id int)engine=innodb;
create table t2(id int)engine=myisam;
create table t3(id int)engine=blackhole;
create table t4(id int)engine=memory;
插入数据
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
创建表的完整语法
创建表的完整语法
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
注意:
1.字段名和字段类型是必须的 中括号内的参数都是可选参数
2.同一张表中字段名不能重复
3.最后一个字段后面不能加逗号
create table t6(
id int,
name char,
);
宽度:
使用数据库的准则:能尽量让它少干活就尽量少干活,减少压力
对存储数据的限制
char(1) 只能存一个字符
如果超了 mysql会自动帮你截取
1.插入的时候 mysql自动截取
2.会直接报错(mysql严格模式)
alter table t5 modify name char not null;
not null该字段不能插空
类型和中括号内的约束
类型约束的是数据的存储类型
而约束是基于类型之上的额外限制
整型
SMALLINT TINYINT INT BIGINT
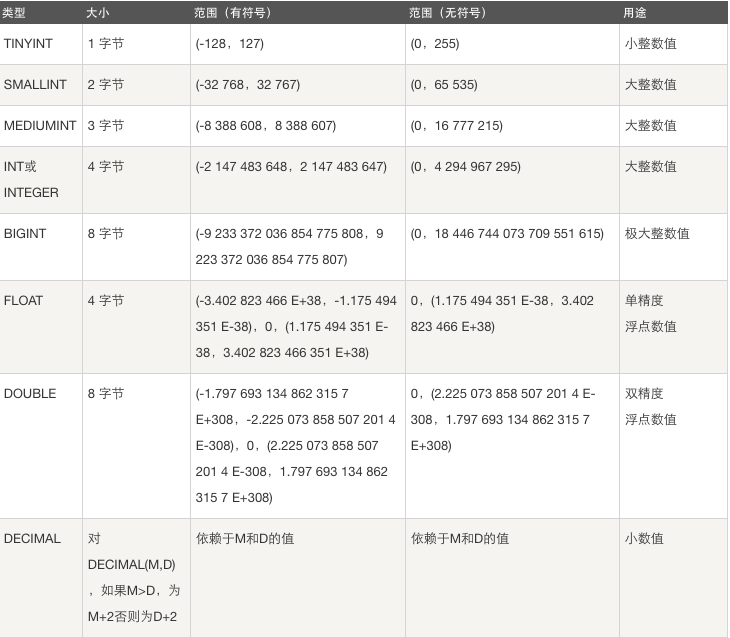
TINYINT
默认是否有符号 默认是带有符号的(-128,127)
超出限制会如何 超出之后只会存最大值或者最小值
create table t6(id TINYINT);
not null 不能为空
unsigned 无正负符号
zerofill 0填充多余的位数
char后面的数字是用来限制存储数据的长度的
特例:只有整型后面的数字不是用来限制存储数据的长度 而是用来控制展示的数据的位数
int(8) 够/超8位有几位存几位,不够8位空格填充
修改约束条件 不够8位的情况下 用0填充
强调:**对于整型来说,数据类型后的宽度并不是存储限制,
而是显示限制,所以在创建表时,
如果字段采用的是整型类型,完全无需指定显示宽度, 默认的显示宽度,足够显示完整当初存放的数据
只要是整型 都不需要指定宽度 因为有默认的宽度 足够显示对应的数据
严格模式
在上面设置了char,tinyint,存储数据时超过它们的最大存储长度,发现数据也能正常存储进去,只是mysql帮我们自动截取了最大长度。但在实际情况下,我们应该尽量减少数据库的操作,缓解数据库的压力,让它仅仅只管理数据即可,这样的情况下就需要设置安全模式.
show variables like "%mode%"; # 查看数据库配置中变量名包含mode的配置参数
# 修改安全模式
set session # 只在当前操作界面有效
set global # 全局有效
set global sql_mode ='STRICT_TRANS_TABLES'
# 修改完之后退出当前客户端重新登陆即可
浮点型
float(255,30) 总共255位 小数部分占30位
double(255,30) 总共255位 小数部分占30位
decimal(65,30) 总共65位 小数部分占30位
create table t12(id FLOAT(255,30));
create table t13(id DOUBLE(255,30));
create table t14(id DECIMAL(65,30));
insert into t12 values(1.111111111111111111111111111111);
insert into t13 values(1.111111111111111111111111111111);
insert into t14 values(1.111111111111111111111111111111);
精确度
float < double < decimal
字符类型
char(4) # 最大只能存四个字符 超出来会直接报错 如果少了 会自动用空格填充
varchar(4) # 最大只能存四个字符 超出来会直接报错 如果少了 有几个存几个
#验证存储限制
create table t15(name char(4));
create table t16(name varchar(4));
#验证存储长度
insert into t12 values('a'); #'a '
insert into t13 values('a'); #'a'
select * from t12
select * from t13 # 无法查看真正的结果
char_length()
select char_length(name) from t12
select char_length(name) from t13 # 仍然无法查看到真正的结果
mysql在存储char类型字段的时候 硬盘上确确实实存的是固定长度的数据
但是再取出来的那一瞬间 mysql会自动将填充的空格去除
可以通过严格模式 来修改该机制 让其不做自动去除处理
char与varchar的区别
char定长
1.浪费空间
2.存取速度快
varchar变长
1.节省空间
2.存取速度慢(较于char比较慢)
存的时候 需要给数据讲一个记录长度的报头
取的时候 需要先读取报头才能读取真实数据
char(4) varchar(4)
取的时候方便 取的时候比较繁琐了 无法知道数据到底多长
直接按固定的长度取即可
时间类型
分类:
date : 2019-08-19
time : 20:20:20
datetime: 2019-08-19 20:20:20
year :2019
测试:
create table student(
id int,
name char(16),
born_year year,
birth date,
study_time time,
reg_time datetime
);
insert into student values(1,'egon','2019','2019-08-19','20:11:00','2019-10-11 10:12:11');
枚举与集合类型
枚举(enum) 限制某个字段能够存储的数据内容
集合(set) 限制某个字段能够存储的数据内容
create table user(
id int,
name char(16),
gender enum('male','female','others')
);
insert into user values(1,'jason','xxx') # 报错
insert into user values(2,'egon','female') # 正确!
create table teacher(
id int,
name char(16),
gender enum('male','female','others'),
hobby set('read','sleep','sanna','dbj')
);
insert into teacher values(1,'egon','male','read,sleep,dbj') # 集合也可以只存一个
约束条件
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
not null + default 非空 + 默认
not null 不能为空
default 给某个字段设置默认值(当用户写了的时候用用户的,当用户没有写就用默认值)
create table user(
id int,
name char(16)
);
insert into user values(1,null) # 可以修改
alter table user modify name char(16) not null;
insert into user(name,id) values(null,2); # 报错 插入数据可以在表名后面指定插入数据对应的字段
create table student(
id int,
name char(16) not null,
gender enum('male','female','others') default 'male'
)
insert into student(id,name) values(1,'jason') # 成功
往表中插入数据的时候 可以指定字段进行插入 不需要全部都插
unique 唯一
# 单列唯一 限制某一个字段是唯一的
create table user1(
id int unique,
name char(16)
);
insert into user1 values(1,'jason'),(1,'egon') # 报错
insert into user1 values(1,'jason'),(2,'egon') # 成功
# 联合唯一 (在语句的最后 用括号的形式 表示哪几个字段组合的结果是唯一的)
create table server(
id int,
ip char(16),
port int,
unique(ip,port)
)
insert into server values(1,'127.0.0.1',8080);
insert into server values(2,'127.0.0.1',8080); # 报错
insert into server values(1,'127.0.0.1',8081);
primary key 主键
限制效果跟 not null + unique 组合效果一致 非空且唯一
create table t17(id int primary key);
desc t11;
insert into t17 values(1),(1); # 报错
insert into t17 values(1),(2);
# 除了约束之外,它还是innodb引擎组织数据的依据,提升查询效率
innodb引擎在创建表的时候 必须要有一个主键
当你没有指定主键的时候
1.会将非空切唯一的字段自动升级成主键
2.当你的表中没有任何的约束条件 innodb会采用自己的内部默认的一个主键字段
该主键字段你在查询时候是无法使用的
查询数据的速度就会很慢
类似于一页一页的翻书
create table t18(
id int,
name char(16),
age int not null unique,
addr char(16) not null unique
)engine=innodb;
desc t18;
联合主键:多个字段联合起来作为表的一个主键,本质还是一个主键
create table t19(
ip char(16),
port int,
primary key(ip,port)
);
desc t19;
主键字段应该具备自动递增的特点
每次添加数据 不需要用户手动输入
auto_increment 自动递增
create table t21(id int primary key auto_increment,name varchar(16));
create table t22(id int primary key,name varchar(16));
补充
delete from tb1;
强调:上面的这条命令确实可以将表里的所有记录都删掉,但不会将id重置为0,
所以收该条命令根本不是用来清空表的,delete是用来删除表中某一些符合条件的记录
delete from tb1 where id > 10;
如果要清空表,使用truncate tb1;
作用:将整张表重置,id重新从0开始记录