学习一项新知识的时候,最好的方法就是去实践它。
前言
《CLR via C#》这本神书真的是太有意思了!没错我的前言就是这个。
装箱
首先来看下,下面这段代码
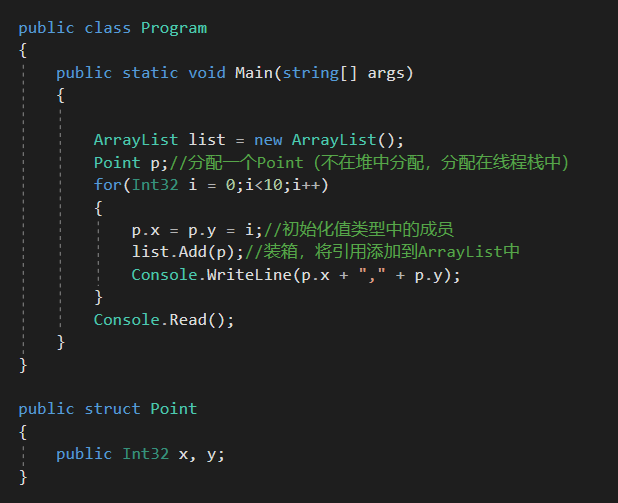
可以看到,每次循环迭代都会初始化一个Point的值类型字段,并将该Point存储到ArrayList中。
但是我们肯定有疑问,ArrayList中究竟存储了什么?是Point结构,Point结构的地址,还是其他完全不同的东西?
为了解答这个问题,我们必须研究一下ArrayList的Add方法,了解它的参数被定义成了什么类型。
可以知道,Add的原型如下:
1 public virtual Int32 Add(Object value);
说明Add获取的是一个Object参数。也就是说,Add获取对托管对上的一个对象的引用(或指针)来作为参数。但是之前的代码传递的是p,也就是一个Point,是一个值类型。
为了使代码能够正确的工作,Point值类型必须转换成真正的、在堆中托管的对象,而且必须获取对该对象的引用。
那么,这个将值类型转换成引用类型的操作,就叫做装箱。
当值类型的实力进行装箱时,发生了以下三件事情:
1、在托管堆中分配内存。分配的内存量是值类型各个字段所需要的内存量,还要加上托管堆所有对象都有的两个额外成员(类型对象指针和同步块索引)所需要的内存量。关于类型对象指针和同步块索引,可以看我的这边博文:https://www.cnblogs.com/knqiufan/p/10475186.html
2、值类型的字段复制到新分配的堆内存。
3、返回对象地址。现在该地址是对象引用;值类型成了引用类型。
C#编译器自动生成堆值类型实力进行装箱所需的IL代码。
所以在运行时,当前存在于Point值类型实力p中的字段复制到新分配的Point对象中。已经装箱的Point对象(现在是引用类型)的地址返回并传给Add方法。Point对象一直存在于堆中,直至被垃圾回收。
(所以之所以说相比于ArrayList,尽量用泛型List<T>,因为泛型集合List<T>允许开发人员在操作值类型的集合时不需要对集合中的项进行装箱或拆箱操作。这一改进,使性能提高了不少,因为托管堆中需要创建的对象减少了,进而减少了应用程序需要执行的垃圾回收的次数。)
拆箱
说完了装箱,现在来说说拆箱。假定我继续执行以下操作:
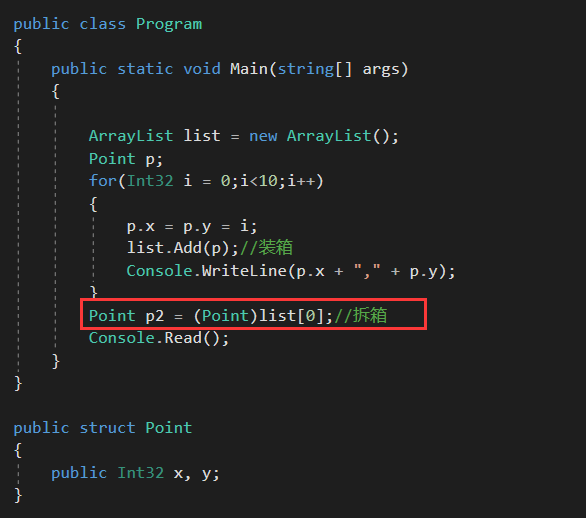
它获取ArrayList的元素0包含的引用(或指针),试图将其放到Point值类型的实力p2中。
为此,已经装箱的Point对象中的所有字段都必须复制到值类型变量p2中,后者在线程栈上。
CLR分为两步完成复制:
1、获取已经装箱Point对象中的各个Point字段的地址。这个过程就是拆箱。
2、将字段包含的值从堆复制到基于栈的值类型的实例中。
拆箱并不是直接将装箱过程倒过来,拆箱的代价要低的多。拆箱其实就是获取指针的过程,该指针指向包含在一个对象中的原始值类型(数据字段)。
其实指针指向的是已经装箱实例中的未装箱部分。所以和装箱不同,拆箱不要求在内存中复制任何字节。
已经装箱的值类型实例在进行拆箱时,内部发生了下面这些事情:
1、如果包含“对已经装箱值类型实例的引用”的变量为null,则抛出NullReferenceException异常。
2、如果引用的对象不是所需值类型的已装箱实例,抛出InvalidCastException异常。