今天上课谈到树链剖分,被机房某dalao嘲讽了一波,决定冒着不听课的风险学树剖
关于这篇blog的灵感来源:传送门,不妥删
1.0前置知识
1.1链式向前星
这个应该都会吧,但还是附上讲解,这个图很易懂啊,蒟蒻当时一直没学懂,看了图才发现自己有多弱智
1.2dfs序
这个学长上课讲的随便找了一个讲解,仅供参考:传送门
1.3线段树
线段树应该都学了,就不附连接了
1.4为什么要学树剖
小蒟蒻没怎么做过树上倍增和链剖的题,但据说树上倍增的题链剖都能做,但链剖的题树上倍增不一定能做,并且倍增跑的比树剖要慢,这很重要
1.5关于他能解决的问题
- 将树从x到y结点最短路径上所有节点的值都加上z
- 求树从x到y结点最短路径上所有节点的值之和
- 将以x为根节点的子树内所有节点值都加上z
- 求以x为根节点的子树内所有节点值之和
2.0正文(重链剖分)
ps:还有长链剖分(把size排换成depth),实链剖分(要用到lct),以后再谈
2.1模板题传送门:洛谷p3384
2.2一些定义
- 重儿子:父节点的所有儿子中子树结点数目最大的结点;
- 轻儿子:父节点中除了重儿子以外的儿子;
- 重边:父亲结点和重儿子连成的边;
- 轻边:父亲节点和轻儿子连成的边;
- 重链:由多条重边连接而成的路径;
- 轻链:由多条轻边连接而成的路径;
另:
- 如果一个点的一堆儿子所在子树大小相等且最大,那随便找一个做重儿子,这真的很严谨
- 叶节点没有重儿子,非叶节点有且仅有一个重儿子
图解(手绘不易,图丑勿喷,谢谢配合)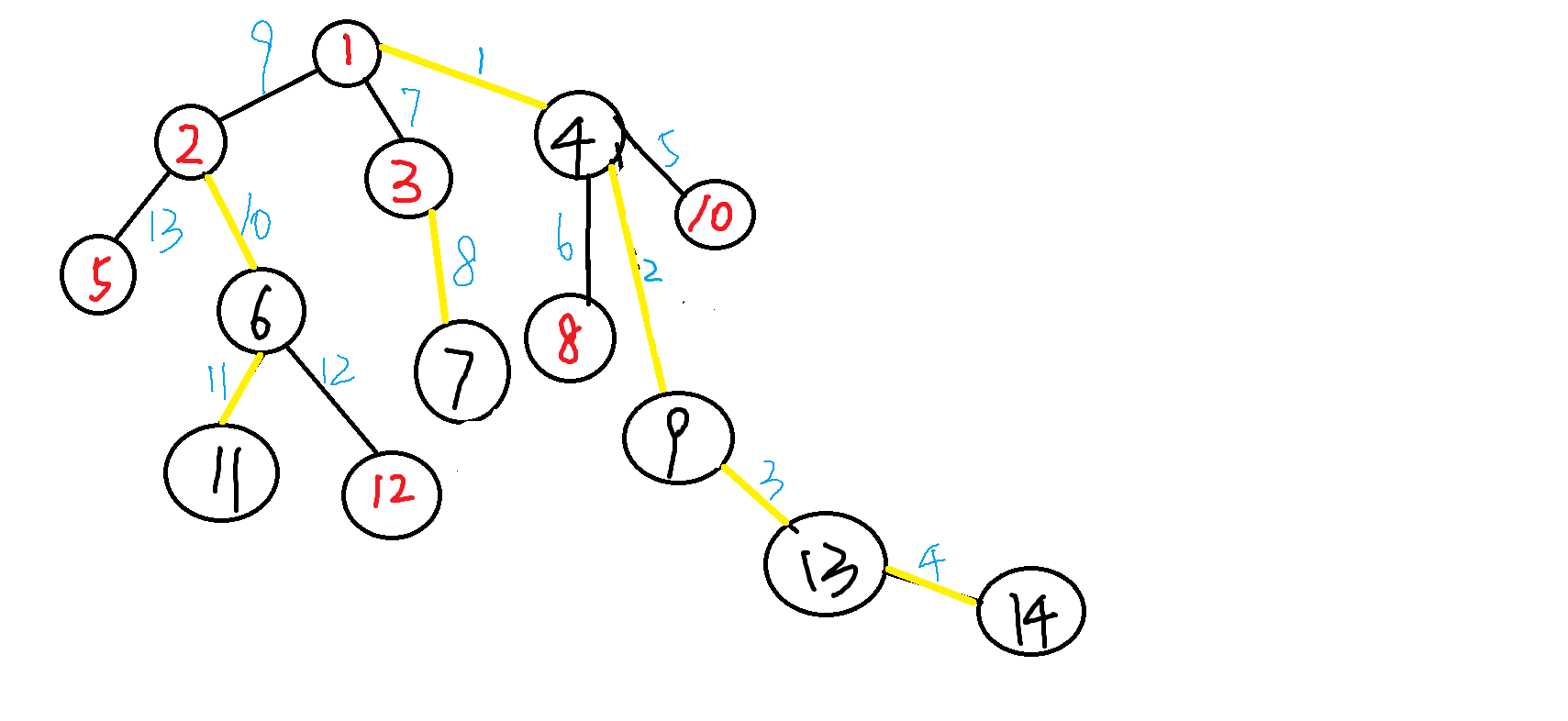
黄线:重边;黑线:轻边;
重链如1-4,2-11……轻链如2-5……
红色节点:重链所在起点(top[ ]);
重儿子重边连接的节点,其余为轻儿子;
每条边的值实为dfs顺序
2.3变量声明
struct node1{//邻接表,链式向前星 int next,to; #define next(i) e[i].next #define to(i) e[i].to }e[maxn*2]; struct node2{//线段树维护 int l,r,ls,rs,sum,lazy; #define l(i) a[i].l #define r(i) a[i].r #define sum(i) a[i].sum #define lazy(i) a[i].lazy #define ls(i) a[i].ls #define rs(i) a[i].rs }a[maxn*2]; int n,m,r,rt,mod,v[maxn],head[maxn],cnt,rk[maxn];//rk存当前dfs标号在树中所对应的节点 int fa[maxn],depth[maxn],son[maxn],size[maxn];//fa他爹,depth深度,son重儿子,size子树大小(包含自身) int top[maxn],id[maxn];//top是当前节点所在链的顶端节点(记得之前的红节点吗),id树中每个节点剖分以后的新编号(DFS的执行顺序)
酷爱宏定义的我,首先要说一下这里所有的int 都代表long long
是不是有一丝迷茫?O(∩_∩)O没关系看看下面
2.4一些函数讲解
(1)add加边操作,详见链式向前星
inline void add(int x,int y){//链式向前星加边 nex(++cnt)=head[x];to(cnt)=y;head[x]=cnt; }
(2)dfs1,作用:处理fa,depth,size
inline void dfs1(int p){
size[p]=1,depth[p]=depth[fa[p]]+1;//更新size,depth
for(int i=head[x];i;i=next(i)){
int q=to(i);
if(q==fa[p])continue;//找到爸爸就返回
fa[q]=p,dfs1(q),size[p]+=size[q];
if(size[son[p]]<size[q])son[p]=q;//更新重儿子
}}
上图跑完以后是这个样子(这个直接截了dalao的图代表和上面一样,f代表fa,d代表depth)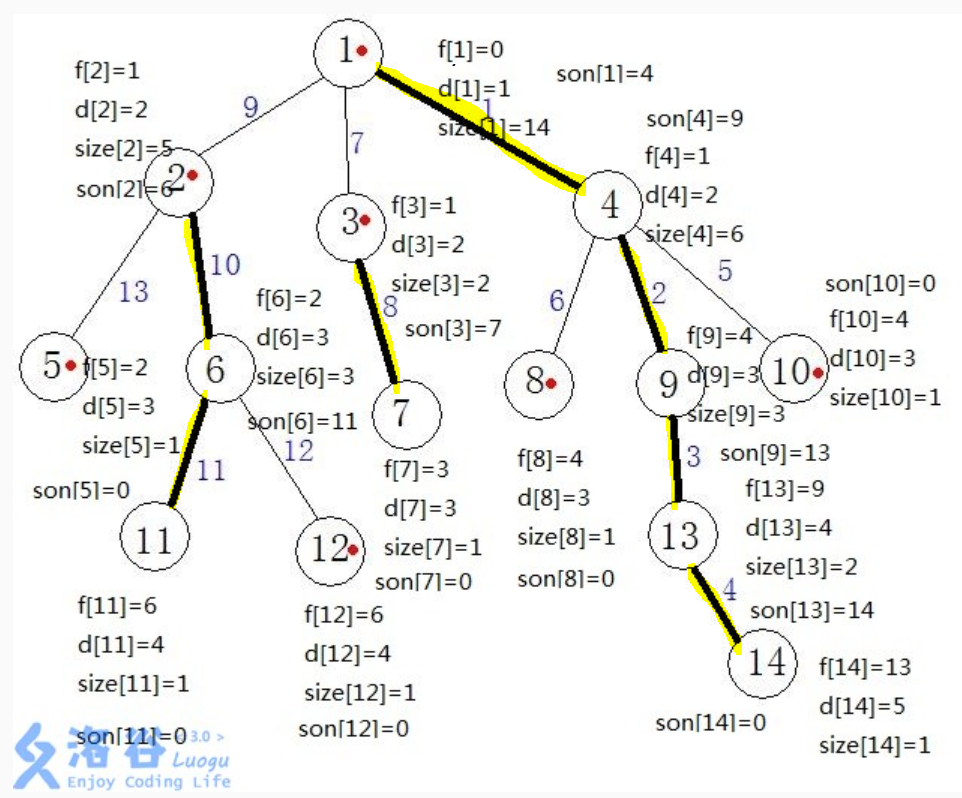
(3)dfs2 作用:处理top,rk,id
inline void dfs2(int p,int tp){ top[p]=tp,id[p]=++cnt,rk[cnt]=p;//更新数组 if(son[p])dfs2(son[p],tp);//有重儿子就继续递归更新下去 for(i=head[x];i;i=next(i)){ int q=to(i); if(q!=fa[p]&&q!=son[p]) dfs2(q,q);//显然位于轻链低端的点top为他本身 } }
如果对于id和rk仍然有些不懂,请看下图

其实rk和id就是反着的啦~
(4)pushup(p)操作用来更新以p为节点的子树的和
inline void pushup(int p){//左右子树更新和
sum(p)=sum(ls(p))+sum(rs(p));
sum(p)%=mod;
}
(5)build(l,r,p)建树
inline void build(int l,int r,int p){//建树,p当前节点 if(l==r){ sum(p)=v[rk[l]];//或v[rk[r]] l(p)=r(p)=l;return ;//或=r } int mid=(l+r)>>1; ls(p)=cnt++,rs(p)=cnt++; build(l,mid,ls(p)),build(mid+1,r,rs(p)); l(p)=l(ls(p)),r(p)=r(rs(p)); pushup(p);//建了子树当然要更新一下和 }
(6)len(p)求长度
inline int len(int p){ return r(p)-l(p)+1; }
(7)pushdown(p)传以p为节点的子树的懒标记
inline void pushdown(int p){//传懒标记 ,不太懂得可以先巩固一遍线段树 if(lazy(p)){ int ls=ls(p),rs=rs(p),lz=lazy(p); (lazy(ls)+=lz)%=mod;(lazy(rs)+=lz)%=mod; (sum(ls)+=lz*len(ls))%=mod; (sum(rs)+=lz*len(rs))%=mod; lazy(p)=0; } }
(8)update(l,r,d,p)修改某一子树
inline void update(int l,int r,int d,int p){//修改某一子树 if(l(p)>=l&&r(p)<=r){ lazy(p)+=d;lazy(p)%=mod; sum(p)+=len(p)*d;sum(p)%=mod; return ; } pushdown(p); int mid=(l(p)+r(p))>>1; if(mid>=l)update(l,r,d,ls(p)); if(mid<r)update(l,r,d,rs(p)); pushup(p); }
(9)updates(x,y,d)从lca往下跳到x调用update再从lca跳到y调用update
inline void updates(int x,int y,int d){ while(top[x]!=top[y]){ if(depth[top[x]]<depth[top[y]])swap(x,y);//我们假设x更深 update(id[top[x]],id[x],d,root); x=fa[top[x]]; } if(id[x]>id[y])swap(x,y); update(id[x],id[y],d,root); }
(10)query(l,r,p)询问某子树和
inline int query(int l,int r,int p){ if(l(p)>=l&&r(p)<=r)return sum(p); pushdown(p); int mid=(l(p)+r(p))>>1,tot=0; if(mid>=l)tot+=query(l,r,ls(p)); if(mid<r)tot+=query(l,r,rs(p)); return tot%mod; }
(11)ask(x,y)询问路径和(ask,query和updates,update道理是一样的)
inline int ask(int x,int y){//求路径和 int ans=0; while(top[x]!=top[y]){ if(depth[top[x]]<depth[top[y]])swap(x,y); ans+=query(id[top[x]],id[x],root); ans%=mod; x=fa[top[x]]; } if(id[x]>id[y])swap(x,y); return ans+query(id[x],id[y],root)%mod; }
(12)终于迎来了主函数!
signed main(){ scanf("%lld%lld%lld%lld",&n,&m,&root,&mod); for(int i=1;i<=n;i++)scanf("%lld",&v[i]); for(int i=1;i<=n-1;i++){ int x,y; scanf("%lld%lld",&x,&y); add(x,y);add(y,x); } cnt=0;dfs1(root);dfs2(root,root); cnt=0;build(1,n,root=cnt++); while(m--){ int type; scanf("%lld",&type); switch(type){ case 1:{ int x,y,d; scanf("%lld%lld%lld",&x,&y,&d); updates(x,y,d); break; } case 2:{ int x,y; scanf("%lld%lld",&x,&y); printf("%lld ",ask(x,y)); break; } case 3:{ int x,y; scanf("%lld%lld",&x,&y); update(id[x],id[x]+size[x]-1,y,root); break; } case 4:{ int x; scanf("%lld",&x); printf("%lld ",query(id[x],id[x]+size[x]-1,root)); break; } } } return 0; }
3.0后记
emmmm对于这道模板题……我死了,所以在这也就不发完整代码了,大家可以借鉴一下我在开头提到的dalao的blog
如果有dalao愿意把这些函数凑到一起帮我查个错,那就感激涕零了(✿◕‿◕✿)
国际惯例:撒花完结*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。