首先感谢教程 http://blog.csdn.net/ruotianxia/article/details/78331964 很全面很详细
1.配置好deeplab_v2 source code:https://bitbucket.org/aquariusjay/deeplab-public-ver2/src 配置过程不做描述了。。
2.建立一个项目文件夹,文件夹里包括子文件夹config feature feature2 list log model res 为了方便可以复制这个git里的voc2012后做修改 https://github.com/xmojiao/deeplab_v2
3.数据的准备。 数据主要包括图片以及图片对应的label(也为png图片),可以存放在任意你喜欢的位置,后续只需给定路径即可。将数据分为训练和验证集制作list 具体格式参照voc2012 list文件夹中的格式。 为了后续测试最好也留一部分做test set。 另外还有val跟test的图片id list 只要id 不要前缀
4.训练的protxt文件存放在config/deeplab_largeFOV中,在这里使用的shell文件 run_pascal.sh 训练故 trainval.pt 不用修改, 在solver.pt中可修改lr及模型存放位置等。。
5.修改run_pascal.sh
#!/bin/sh
## MODIFY PATH for YOUR SETTING
ROOT_DIR=/home/aigrp/kai/segmentation_data ##数据根目录
CAFFE_DIR=/home/aigrp/kai/deeplab/deeplab-public-ver2 ##deeplab_v2根目录
CAFFE_BIN=${CAFFE_DIR}/build/tools/caffe.bin ##deeplab caffe.bin
EXP=.
if [ "${EXP}" = "." ]; then
NUM_LABELS=2 ## 类别数
DATA_ROOT=${ROOT_DIR}
else
NUM_LABELS=0
echo "Wrong exp name"
fi
## Specify which model to train
########### voc12 ################
NET_ID=deeplab_largeFOV
## Variables used for weakly or semi-supervisedly training
#TRAIN_SET_SUFFIX=train
TRAIN_SET_SUFFIX=_aug
#TRAIN_SET_STRONG=train
#TRAIN_SET_STRONG=train200
#TRAIN_SET_STRONG=train500
#TRAIN_SET_STRONG=train1000
#TRAIN_SET_STRONG=train750
#TRAIN_SET_WEAK_LEN=5000
DEV_ID=3 ## 指定GPU
#####
## Create dirs
CONFIG_DIR=${EXP}/config/${NET_ID}
MODEL_DIR=${EXP}/model/${NET_ID}
mkdir -p ${MODEL_DIR}
LOG_DIR=${EXP}/log/${NET_ID}
mkdir -p ${LOG_DIR}
export GLOG_log_dir=${LOG_DIR}
## Run
RUN_TRAIN=1 ##1时train
RUN_TEST=0 ##1时test
RUN_TRAIN2=0
RUN_TEST2=0
## Training #1 (on train_aug)
if [ ${RUN_TRAIN} -eq 1 ]; then
#
LIST_DIR=${EXP}/list
TRAIN_SET=train${TRAIN_SET_SUFFIX}
if [ -z ${TRAIN_SET_WEAK_LEN} ]; then
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
else
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}_head${TRAIN_SET_WEAK_LEN}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt | head -n ${TRAIN_SET_WEAK_LEN} > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
fi
#
MODEL=${EXP}/model/${NET_ID}/init.caffemodel
#
echo Training net ${EXP}/${NET_ID}
for pname in train solver; do
sed "$(eval echo $(cat sub.sed))"
${CONFIG_DIR}/${pname}.prototxt > ${CONFIG_DIR}/${pname}_${TRAIN_SET}.prototxt
done
CMD="${CAFFE_BIN} train
--solver=${CONFIG_DIR}/solver_${TRAIN_SET}.prototxt
--gpu=${DEV_ID}"
if [ -f ${MODEL} ]; then
CMD="${CMD} --weights=${MODEL}"
fi
echo Running ${CMD} && ${CMD}
fi
## Test #1 specification (on val or test)
if [ ${RUN_TEST} -eq 1 ]; then
#
for TEST_SET in val; do
TEST_ITER=`cat ${EXP}/list/${TEST_SET}.txt | wc -l`
MODEL=${EXP}/model/${NET_ID}/test.caffemodel
if [ ! -f ${MODEL} ]; then
MODEL=`ls -t ${EXP}/model/${NET_ID}/train_m2_iter_80000.caffemodel | head -n 1`
fi
#
echo Testing net ${EXP}/${NET_ID}
FEATURE_DIR=${EXP}/features/${NET_ID}
mkdir -p ${FEATURE_DIR}/${TEST_SET}/fc8
mkdir -p ${FEATURE_DIR}/${TEST_SET}/fc9
mkdir -p ${FEATURE_DIR}/${TEST_SET}/seg_score
sed "$(eval echo $(cat sub.sed))"
${CONFIG_DIR}/test.prototxt > ${CONFIG_DIR}/test_${TEST_SET}.prototxt
CMD="${CAFFE_BIN} test
--model=${CONFIG_DIR}/test_${TEST_SET}.prototxt
--weights=${MODEL}
--gpu=${DEV_ID}
--iterations=${TEST_ITER}"
echo Running ${CMD} && ${CMD}
done
fi
## Training #2 (finetune on trainval_aug)
if [ ${RUN_TRAIN2} -eq 1 ]; then
#
LIST_DIR=${EXP}/list
TRAIN_SET=trainval${TRAIN_SET_SUFFIX}
if [ -z ${TRAIN_SET_WEAK_LEN} ]; then
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
else
修改后保存,运行 sh run_pascal.sh
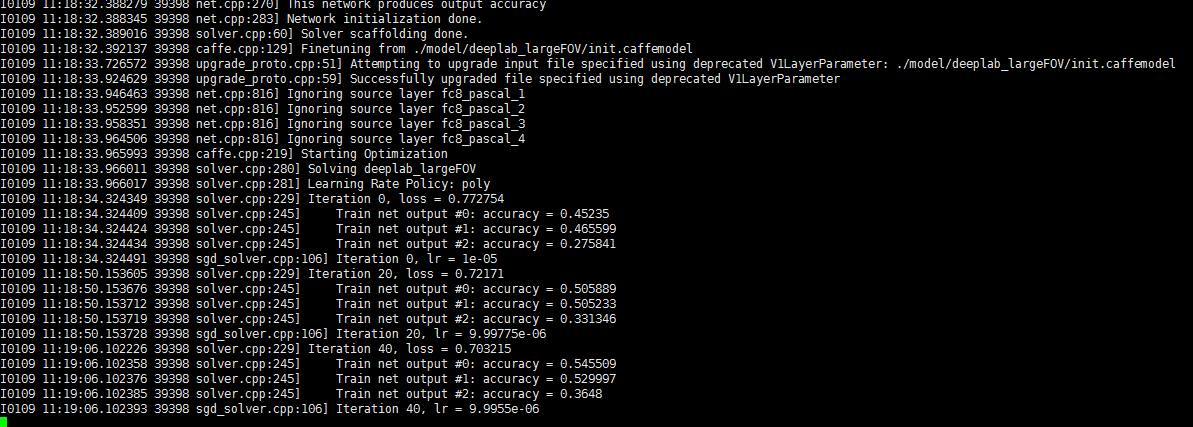
过程比较缓慢。
6.训练完成后再次修改run_pascal.sh test =1 做测试。
后续的crf部分还没有在自己的数据集上尝试,目前就到这里