1、直接插入排序
基本思想:
(1)首先对数组的前两个数据进行从小到大排序;
(2)接着将第3个数据与排好序的两个数进行比较,将第3个数据插入到合适的位置;
(3)然后将第4个数据插入到上述已排好序的前3个数中;
(4)不断重复上述过程,知道将最后一个数据插入到合适的位置,最后便完成了对原始数据的从小到大的排序。
测试程序:
#include<stdio.h> #include<stdlib.h> #include<time.h> #define SIZE 10 void InsertionSort(int a[], int len) //直接插入排序 { int temp;//临时变量 int i,j,k; for(i=1;i<len;i++) { temp=a[i]; j=i-1; while((j>=0) && (temp<a[j])) //这里while不能换成if,if只是一次判定,while具有循环判定的功能 { a[j+1]=a[j]; j--; } a[j+1]=temp; printf("第%d步直接插入排序的结果为:",i); for(k=0;k<len;k++) { printf("%d ",a[k]); } printf(" "); } } void main() { int arr[SIZE]; int i; srand(time(NULL)); //time(NULL)返回当前时间,意思是以当前系统时间作为随机数的种子来产生随机数! //至于NULL这个参数,只有设置成NULL才能获得系统的时间; //srand 是对随机数生成器进行初始化操作,设置随数种子 for(i=0;i<SIZE;i++) { arr[i]=rand()%(1000-100)+100; //产生100到1000之内的随机数 } printf("排序前的序列如下: "); for(i=0;i<SIZE;i++) { printf("%d ",arr[i]); } printf(" "); InsertionSort(arr,SIZE); printf("直接插入排序后的序列如下: "); for(i=0;i<SIZE;i++) { printf("%d ",arr[i]); } printf(" "); system("pause"); }
测试结果:
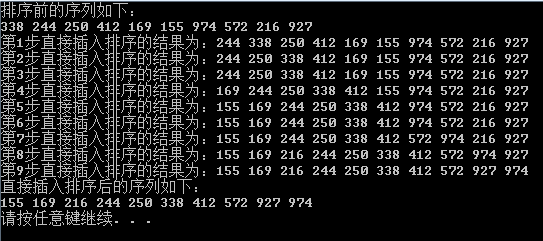
2、希尔排序(缩小增量排序)
基本思想:
(1)先选取一个小于n的整数(称之为步长)di,然后将n个待排序的数据序列划分成di个子序列;
(2)从第1个数据开始,间隔为di的数据为同一个序列,然后分别对每一个子序列进行直接插入排序;
(3)一趟之后,间隔为di的数据有序,随着有序性的改善,继续减小步长di,如此反复进行,知道步长di=1;
(4)此时再对所有记录进行一次直接插入排序即可。
测试程序:
这里步长取n/2,n/4....
/* 希尔排序(缩短增量排序) */ #include<stdio.h> #include<stdlib.h> #include<time.h> #define SIZE 10 void ShellSort(int a[],int len) //希尔排序(参数:数组,数组长度) { int i,j,k; int temp,r; int x=0; for(r=len/2;r>=1;r/=2) { for(i=r;i<len;i++) { temp=a[i]; j=i-r; while(j>=0 && temp<a[j]) { a[j+r]=a[j]; j-=r; } a[j+r]=temp; } x++; printf("第%d步希尔排序结果为:",x); for(k=0;k<len;k++) { printf("%d ",a[k]); } printf(" "); } } void main() { int i; int arr[SIZE]; srand(time(NULL)); for(i=0;i<SIZE;i++) { arr[i]=rand()%(1000-100)+100; } printf("排序前的数据序列如下: "); for(i=0;i<SIZE;i++) { printf("%d ",arr[i]); } printf(" "); ShellSort(arr,SIZE); printf("希尔排序后的数据序列如下: "); for(i=0;i<SIZE;i++) { printf("%d ",arr[i]); } printf(" "); system("pause"); }
测试结果:
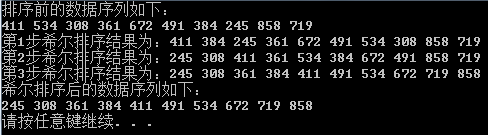
3、冒泡排序
基本思想:
(1)对数据序列中各数据,依次比较相邻的两个数据元素的大小;
(2)如果前面的数据大于后面的数据,就交换这两个数据,经过一轮的多次比较排序,就可将最小的数据排到首位;
(3)然后,再用同样的方法把剩下的数据逐个进行比较。
测试程序:
本测试程序从尾部开始进行两两比较
#include<stdio.h> #include<stdlib.h> #include<time.h> #define SIZE 10 void BubbleSort(int a[],int len) { int i,j,k; int temp; for(i=0;i<len-1;i++) { for(j=len-1;j>i;j--) { if(a[j-1]>a[j]) { temp=a[j-1]; a[j-1]=a[j]; a[j]=temp; } } printf("第%d步冒泡排序结果为:",i); for(k=0;k<len;k++) { printf("%d ",a[k]); } printf(" "); } } void main() { int i; int arr[SIZE]; srand(time(NULL)); //随机种子 for(i=0;i<SIZE;i++) { arr[i]=rand()%(1000-100)+100; //产生排序前的随机序列(100到1000内的三位数) } printf("排序前的数据序列如下: "); for(i=0;i<SIZE;i++) { printf("%d ",arr[i]); } printf(" "); BubbleSort(arr,SIZE); printf("冒泡排序后的数据序列如下: "); for(i=0;i<SIZE;i++) { printf("%d ",arr[i]); } printf(" "); system("pause"); }
测试结果:
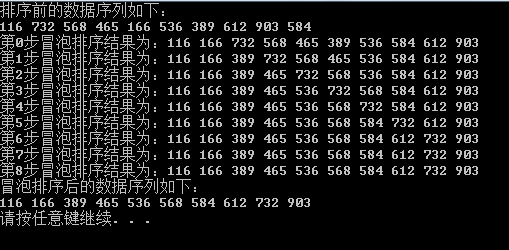
4、快速排序
基本思想:
注:快速排序与冒泡排序类似,都是基于交换排序思想,是冒泡排序的改进
- 首先设定一个分界值,提高该分界值将数组分成左右两部分
- 将大于等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于等于分界值,而右边部分中各元素都大于等于分界值
- 然后,左边和右边的数据可以再独立排序。对于左侧的数据,又可以去一个分界值,将该部分的数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以类似处理
- 重复上述过程,可以看出,这是一个递归过程。
测试程序:
/* 快速排序 */ #include <stdio.h> #include <stdlib.h> #include <time.h> #define SIZE 18 void QuickSort(int *arr, int left, int right) { int f,t; int rtemp,ltemp; ltemp=left; rtemp=right; f=arr[(left+right)/2]; //将中间值作为分界值 while(ltemp<rtemp) { while(arr[ltemp]<f) { ++ltemp; } while(arr[rtemp]>f) { --rtemp; } if(ltemp<=rtemp) { t=arr[ltemp]; arr[ltemp]=arr[rtemp]; arr[rtemp]=t; --rtemp; ++ltemp; } } if(ltemp==rtemp) { ltemp++; } if(left<rtemp) { QuickSort(arr,left,ltemp-1); //递归调用 } if(ltemp<right) { QuickSort(arr,rtemp+1,right); //递归调用 } } void main() { int i; int shuzu[SIZE]; srand(time(NULL)); //初始化数组 for(i=0;i<SIZE;i++) { shuzu[i]=rand()/1000+100; //随机产生个三位数的随机数,存在数组arr中 } printf("排序前: "); for(i=0;i<SIZE;i++) { printf("%d �",shuzu[i]); } printf(" "); QuickSort(shuzu,0,SIZE-1); //调用函数QuickSort,对数组进行排序 printf("排序后: "); for(i=0;i<SIZE;i++) { printf("%d �",shuzu[i]); } printf(" "); system("pause"); }
测试结果:

5、选择排序
基本思想:
- 首先从原始数据中选择最小的一个数据,将其和位于第一个位置的数据交换
- 接着从剩下的n-1个数据中选择次小的一个元素,将其和位于第二个位置的数据交换
- 然后,这样不断重复,知道最后两个数据交换完成。
测试程序:
/* 选择排序 */ #include <stdio.h> #include <stdlib.h> #include <time.h> #define SIZE 10 void SelectionSort(int *a,int len) { int i,j,k,h; int temp; for(i=0;i<len-1;i++) { k=i; for(j=i+1;j<len;j++) { if(a[j]<a[k]) k=j; } if(k!=i) { temp=a[i]; a[i]=a[k]; a[k]=temp; } printf("第%d步排序结果:",i); for(h=0;h<len;h++) { printf("%d �",a[h]); } printf(" "); } } void main() { int i; int shuzu[SIZE]; srand(time(NULL)); //初始化数组 for(i=0;i<SIZE;i++) { shuzu[i]=rand()/1000+100; //随机产生个三位数的随机数,存在数组arr中 } printf("排序前: "); for(i=0;i<SIZE;i++) { printf("%d �",shuzu[i]); } printf(" "); SelectionSort(shuzu,SIZE); printf("排序后: "); for(i=0;i<SIZE;i++) { printf("%d �",shuzu[i]); } printf(" "); system("pause"); }
测试结果:
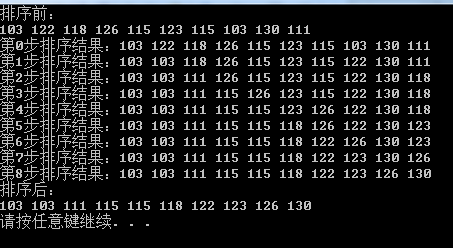
6、堆排序
基本概念:
堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
注意
测试程序:
// array是待调整的堆数组,i是待调整的数组元素的位置,nlength是数组的长度 //本函数功能是:根据数组array构建大根堆 void HeapAdjust(int array[], int i, int nLength) { int nChild; int nTemp; for (nTemp = array[i]; 2 * i + 1 < nLength; i = nChild) { // 子结点的位置=2*(父结点位置)+ 1 nChild = 2 * i + 1; // 得到子结点中较大的结点 if (nChild < nLength - 1 && array[nChild + 1] > array[nChild]) ++nChild; // 如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点 if (nTemp < array[nChild]) array[i] = array[nChild]; else // 否则退出循环 break; // 最后把需要调整的元素值放到合适的位置 array[nChild]= nTemp; } } // 堆排序算法 void HeapSort(int array[],int length) { // 调整序列的前半部分元素,调整完之后第一个元素是序列的最大的元素 //length/2-1是第一个非叶节点,此处"/"为整除 for (int i = length / 2 - 1; i >= 0; --i) HeapAdjust(array, i, length); // 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素 for (int i = length - 1; i > 0; --i) { // 把第一个元素和当前的最后一个元素交换, // 保证当前的最后一个位置的元素都是在现在的这个序列之中最大的 Swap(&array[0], &array[i]); // 不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值 HeapAdjust(array, 0, i-1); } }
7、归并排序
基本思想:
(1)将n个数据序列看成有n个长度为1的有序子序列;
(2)将上述子序列两两合并,得到长度为2的若干有序子表;
(3)然后,再对上述子表两两合并,得到长度为4的若干子表;
........
(4)重复上述过程,直到最后的子表长度为n。从而完成排序过程。
测试程序:
#include<stdio.h> #include<stdlib.h> #include<time.h> #define SIZE 15 void MergeOne(int a[],int b[],int n,int len) /* 完成一遍合并 参数a为一个数组,用来存放待排序数据,n表示数组a中数据总数 参数b为一个数组,用来存放排序后的数据,len表示每个有序子表的长度*/ { int i,j,k; int s,e; s=0; while(s+len<n) { e=s+2*len-1; if(e>=n) //最后一段可能少于len个节点 { e=n-1; } //相邻有序子表合并 k=s; i=s; j=s+len; while((i<s+len) && (j<=e)) //如果两个有序表都未结束时,循环比较 { if(a[i]<=a[j]) //将较小的数据复制到数组b中 { b[k++]=a[i++]; } else { b[k++]=a[j++]; } } while(i<s+len) { b[k++]=a[i++]; //未合并的部分复制到数组b中 } while(j<=e) { b[k++]=a[j++]; //未合并的部分复制到数组b中 } s=e+1; //下一段有序段左段的开始下标 } if(s<n) //将剩余的一个有序段从数组a中复制到数组b中 { for(;s<n;s++) { b[s]=a[s]; } } } void MergeSort(int a[],int n) /* 归并排序 */ { int *p; int h,count,len,f; count=0; //排序步骤计数器 len=1; //有序序列的长度 f=0; //标志 if(!(p=(int *)malloc(sizeof(int)*n))) { printf("内存分配失败! "); exit(0); } while(len<n) { if(f==1) //交替在a和p之间合并 { MergeOne(p,a,n,len); //p合并到a } else { MergeOne(a,p,n,len); //a合并到p } len=len*2; //增加有序序列长度为原来的2倍 f=1-f; //使f的值在0和1之间切换 count++; printf("第%d步为:",count); for(h=0;h<SIZE;h++) { printf("%d ",a[h]); } printf(" "); } if(f) //如果进行了排序 { for(h=0;h<n;h++) { a[h]=p[h]; //将内存p中的数据复制到数组a中 } free(p); //释放内存 } } void main() { int i; int shuzu[SIZE]; srand(time(NULL)); for(i=0;i<SIZE;i++) { shuzu[i]=rand()%(1000-100)+100; } printf("排序前为:"); for(i=0;i<SIZE;i++) { printf("%d ",shuzu[i]); } printf(" "); MergeSort(shuzu,SIZE); printf("排序后为:"); for(i=0;i<=SIZE;i++) { printf("%d ",shuzu[i]); } printf(" "); system("pause"); }
测试结果:

8、小结
排序效率的一个重要指标——速度
计算复杂度,一般依据数据量的大小n来度量,主要表征了算法的执行速度(算法优劣的一个重要指标)
(1)选择排序法:平均速度O(n2),最坏情况下的速度为O(n2);
(2)快速排序法:平均速度O(nlogn),最坏情况下的速度为O(n2);
(3)冒泡排序法:平均速度O(n2),最坏情况下的速度为O(n2);
(4)直接插入排序法:平均速度O(n2),最坏情况下的速度为O(n2);
(5)堆排序法:平均速度O(nlogn),最坏情况下的速度为O(nlogn):
(6)希尔排序法:平均速度O(n3/2),最坏情况下的速度为O(n2);
(7)归并排序法:平均速度O(nlogn),最坏情况下的速度为O(nlogn):