一、sklearn.datasets数据集介绍
机器学习sklearn中的datasets模块提供了一些自带的小数据集。数据集是一个类似字典的对象,特征数据存储在 .data 成员中,它是 n_samples, n_features 数组。 在监督问题的情况下,一个或多个响应变量存储在 .target中,小白在入门时可以利用这些小数据集做一些简单的算法模型,初步感受下sklearn,随后再逐步深入。
1、常见的小数据集:
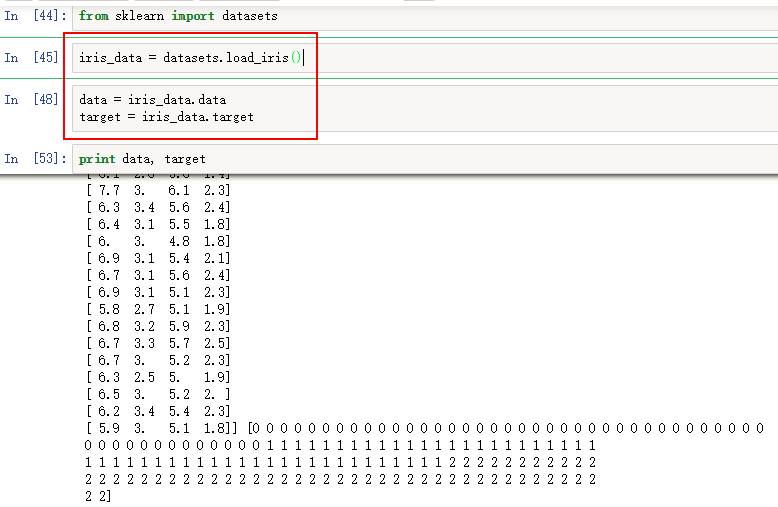
鸢尾花:load_iris()
乳腺癌:load_breast_cancer()
手写数字:load_digits()
糖尿病:load_diabetes()
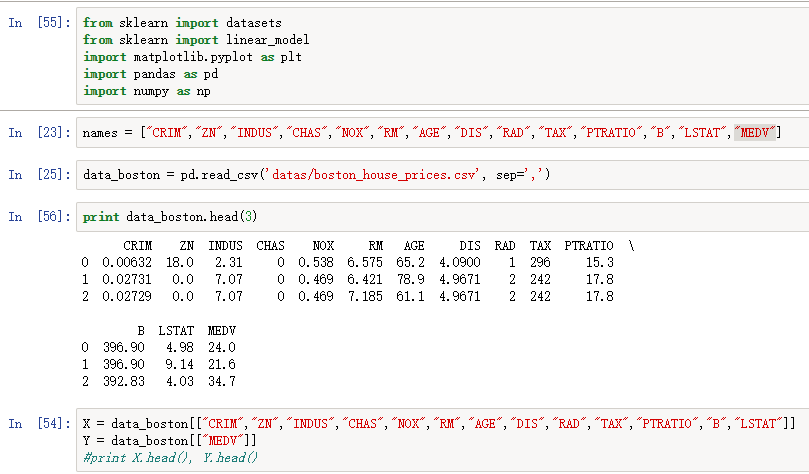
波士顿房价:load_biston()
体能训练:load_linnerud()
图像数据:load_sample_image(name)
2、数据集引入流程:
二、利用数据集构建算法模型
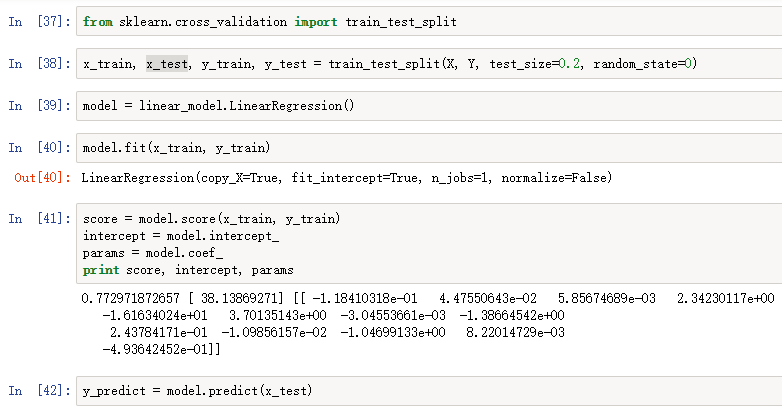
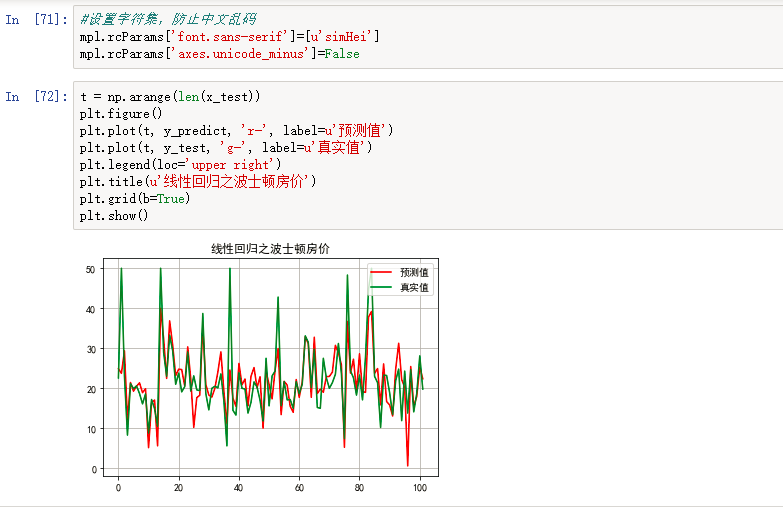
1、使用波士顿房价数据做线性回归,预测房价
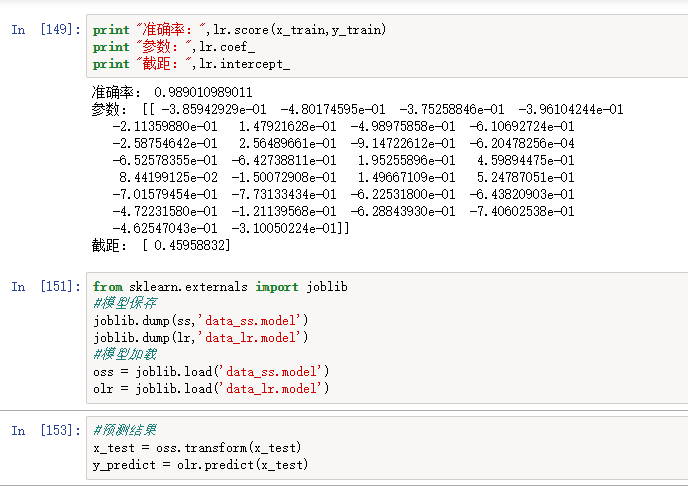
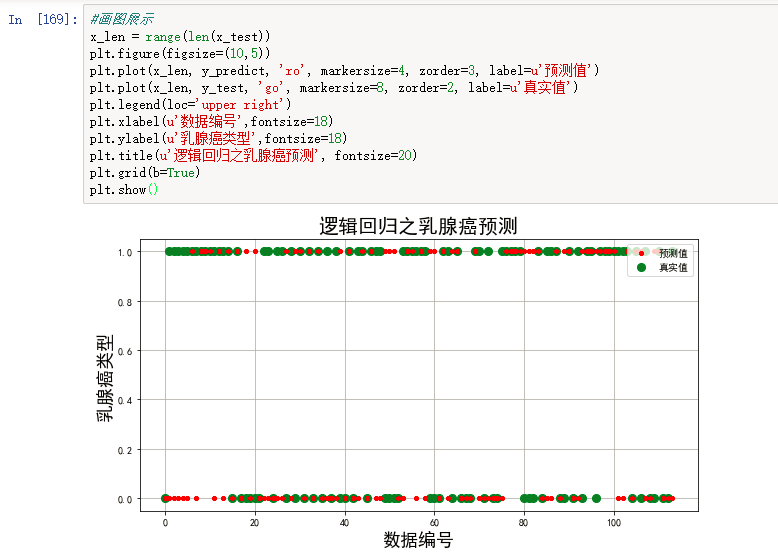
2、使用乳腺癌数据集做逻辑回归,预测癌症

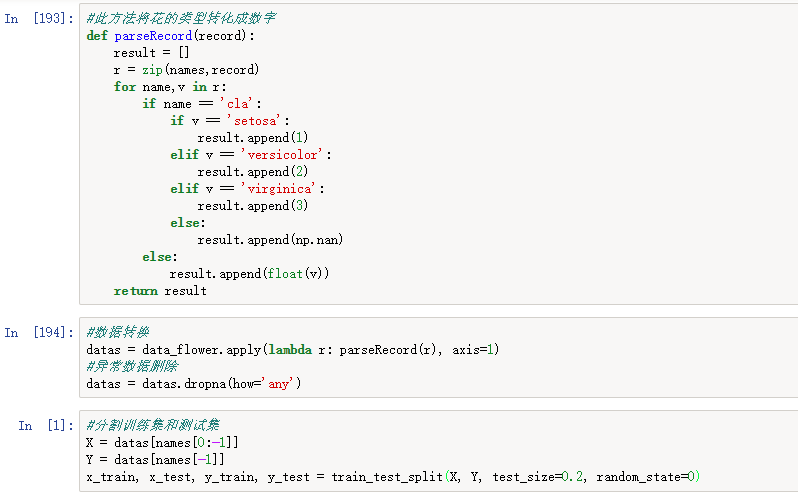
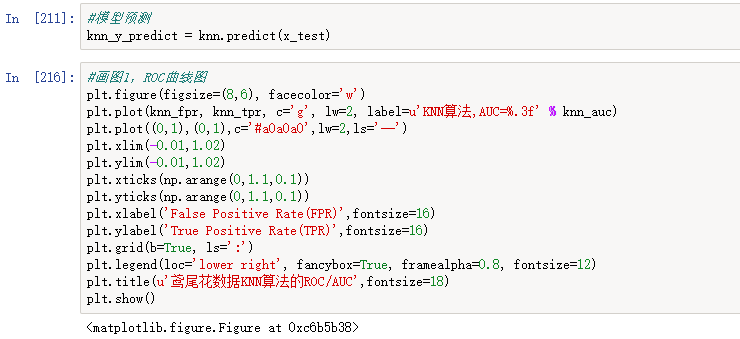
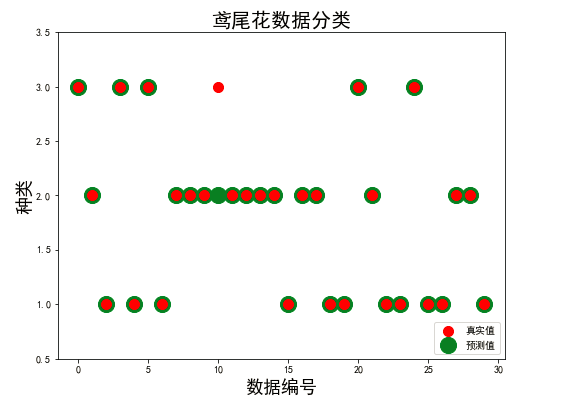
3、使用鸢尾花数据集进行分类模型(KNN)构建
(1)数据集特征

(2)代码




三、算法深入
利用这些小数据集敲几个模型之后,大概懂个所以然,然后深入了解每个算法的原理,公式推导,相关代码实现以及实际应用场景,知其然便会是一个很明朗的过程啦~
至于算法深入部分,待续。。。