为什么需要Service?
在 K8s 集群里面会通过 pod 去部署应用,与传统的应用部署不同,传统应用在给定的机器上面去部署,我们知道怎么去调用别的机器的 IP 地址。但是在 K8s 集群里面应用是通过 pod 去部署的, 而 pod 生命周期是短暂的。在 pod 的生命周期过程中,比如它创建或销毁,它的 IP 地址都会发生变化,这样就不能使用传统的部署方式,不能指定Pod IP 去访问指定的应用。
另外在 K8s 的应用部署里,之前虽然学习了 deployment 的应用部署模式,但还是需要创建一个 pod 组,然后这些 pod 组需要提供一个统一的访问入口,以及怎么去控制流量负载均衡到这个组里面。比如说测试环境、预发环境和线上环境,其实在部署的过程中需要保持同样的一个部署模板以及访问方式。因为这样就可以用同一套应用的模板在不同的环境中直接发布。
什么是Service?
Service服务是Kubernetes里的核心资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个微服务。Service向上提供了外部网络的访问和Pod网络的访问;向下则通过负载均衡把请求分配到不同的Pod中去,如下图所示:
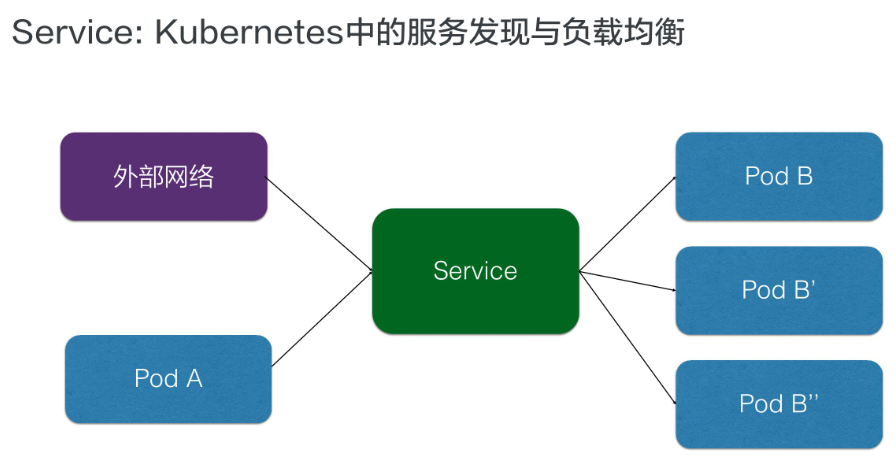
由于每个 Pod 都会被分配一个单独的 IP 地址,而且每个Pod都提供了一个独立的Endpoint(所谓Endpoint,即:Pod IP+Container Port)以被客户端访问。现在通过Deployment的方式部署,会创建多个Pod副本,那么客户端该如何访问它们呢?
运行在每个Node上的 kube-proxy 进程起到了负载均衡的作用,负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。每个Service都被分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。这样一来,每个服务就变成了具备唯一IP地址的通信节点,服务调用就变成了最基础的TCP网络通信问题。随着Pod的销毁和重新创建,新Pod的IP地址与之前旧Pod的不同。而Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的Cluster IP不会发生改变。
集群内访问Service
在集群里面,其他 pod 要怎么访问到我们所创建的这个 service 呢?有三种方式:
- 通过 service 的虚拟 IP 去访问。
- 直接访问服务名,依靠 DNS 解析。
- 通过环境变量访问,在同一个 namespace 里的 pod 启动时,K8s 会把 service 的一些 IP 地址、端口,以及一些简单的配置,通过环境变量的方式放到 K8s 的 pod 里面。
(具体的通过下面的演示加以说明)
Headless Service
在某些应用场景中,开发人员希望自己控制负载均衡的策略,不使用Service提供的默认负载均衡的功能,或者应用程序希望知道属于同组服务的其他实例。Kubernetes提供了Headless Service来实现这种功能, 即不为Service设置ClusterIP(入口IP地址),仅通过Label Selector将后端的Pod列表返回给调用的客户端。例如:
apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx
spec:
ports:
- port: 80
protocol: TCP
clusterIP: None # 表示不分配 clusterIP
selector:
run: nginx
这样,Service就不再具有一个特定的ClusterIP地址,对其进行访问将获得包含Label“app=nginx”的全部Pod列表,然后客户端程序自行决定 如何处理这个Pod列表。
向集群外暴露Service
前面介绍的都是在集群里面 node 或者 pod 去访问 service,service 怎么去向外暴露呢?怎么把集群内的应用暴露给公网去访问呢?这里 service 也有两种类型去解决这个问题,一个是 NodePort,一个是 LoadBalancer。
在继续讲解之前,需要先弄明白Kubernetes里的3种IP,这3种IP分别如下:
- Node IP:Node 的 IP 地址。Node IP 是 k8s 集群中每个节点的物理网卡的 IP 地址,是一个真实存在的物理网络。集群之外的节点访问集群内的某个节点或某个服务时,都必须通过 Node IP 通信。
- Pod IP:Pod 的 IP 地址。它是Docker Engine根据docker0 网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。Kubernetes里一个Pod里的容器访问另外一个Pod里的容器时,就是通过 Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量是通过 Node IP所在的物理网卡流出的。
- Cluster IP:Service 的 IP 地址,也是一种虚拟的IP。Cluster IP仅仅作用于Kubernetes Service这个对象,并由 Kubernetes管理和分配IP地址,它不存在一个“实体网络对象”与之对应,和我们熟知的网络很不一样,因此单独的 Cluster IP 也不具备 TCP/IP 通信基础。它只属于k8s集群这个封闭的空间,集群之外的节点无法直接使用Cluster IP进行访问。(搞清楚这一点至关重要,由此也才会引出“服务暴露”之类的问题)
理解了Cluster IP后,回到“外部系统如何访问Service”这个问题中来,即如何理解 NodePort 和 LoadBalancer?
NodePort 方式
这种方式就是暴露出节点上的一个端口,这样相当于在节点的一个端口上面访问到之后就会再去做一层转发,转发到虚拟的 IP 地址上面,就是刚刚宿主机上面 service 虚拟 IP 地址。
apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx
spec:
type: NodePort # 新增Service Type为NodePort(默认为ClusterIP)
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 81 #
selector:
run: nginx
通过物理机的 IP 地址和 nodePort 81端口号访问服务,就可以访问到某一个被代理的 Pod 的 targetPort 80 端口了。
LoadBalancer 方式
这种方式适用于公有云上的 Kubernetes 服务,对应的 Service.yaml 如下:
apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer # 新增Service Type为LoadBalancer(默认为ClusterIP)
该Service的访问请求将会通过LoadBalancer转发到后端Pod上,负载分发的实现方式则依赖于云服务商提供的LoadBalancer的实现机制。(具体的暂不理解)
示例演示
实验步骤:
1、创建一个Deployment 来产生一组服务pod
2、创建一个Service 来负载均衡这一组Pod
3、在集群中创建一个Pod以不同的方式来访问Service
4、修改服务类型,通过NodePort和Loadbalancer类型来暴露服务到外部
所需的文件包括service.yaml 和deploy.yaml,如下:
Service定义文件,service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx # 定义服务的名称
spec:
ports: # 表示通过前端(port)的80端口均衡负载到后端(targetPort)的80端口,默认targetPort与port相同
- port: 80 # port属性定义了Service的虚端口
protocol: TCP
targetPort: 80 # 即具体业务进程在容器内的targetPort上提供TCP/IP接入
selector: # 表示拥有“run=nginx”的label的pod都隶属于这个Service
run: nginx
Deployment定义文件,deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: nginx
name: nginx
spec:
replicas: 2
selector:
matchLabels:
run: nginx
template:
metadata:
labels:
run: nginx # 拥有“run=nginx”的label的pod都隶属于之前创建的 nginx Service
spec:
containers:
- image: nginx:alpine
name: nginx
imagePullPolicy: IfNotPresent
1)创建Deployment
# kubectl create -f deploy.yaml
创建好后,通过kubectl get查看相应相应资源是否已经创建完成,如下:
# kubectl get pod -o wide -l run=nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-686449ff6b-4dclq 1/1 Running 0 14h 192.168.125.175 k8sslave2 <none> <none>
nginx-686449ff6b-n5gsz 1/1 Running 0 14h 192.168.157.89 k8sslave1 <none> <none>
可以看到这两个pod暴露出来的IP分别是192.168.125.175 和 192.168.157.89,并且分别运行在slave2和slave1节点上。
2)创建Service
#kubectl create -f service.yaml
创建好后,通过kubectl get查看一下是否成功创建
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 119s # 这个是系统默认的
nginx ClusterIP 10.102.53.115 <none> 80/TCP 111s # 这是刚刚创建好的
我们看一下其具体信息,如下:
# kubectl describe svc nginx
Name: nginx
Namespace: default
Labels: run=nginx
Annotations: <none>
Selector: run=nginx
# 注意此时的服务类型是 ClusterIP,也就是只允许集群内部访问,不对外暴露服务
Type: ClusterIP
# 这个IP就是服务发现的IP(通过访问这个虚拟IP地址来访问服务,由负载均衡机制分配到后端的相应Pod上)
IP: 10.102.53.115
Port: <unset> 80/TCP
TargetPort: 80/TCP
# endpoint就是Pod IP:Container Port,这个Pod IP就是上面已经查看过的
Endpoints: 192.168.125.175:80,192.168.157.89:80
Session Affinity: None
Events: <none>
3)创建一个Pod作为client来访问这个服务(通过前面所说的3种方式)
首先,我们随意创建一个Pod(这步未显示),并进入相应的容器中。
# kubectl exec -it sise-7cfd9b6578-55h4w bash
在该容器内部访问Service,执行curl 10.102.53.115(这里的ip就是nigix这个Service的cluster ip),但是显示 curl 命令未安装,故使用wget命令。
方式1:直接通过IP地址访问
root@sise-7cfd9b6578-55h4w:/usr/src/app# wget -O- 10.102.53.115
输出如下,表示正常访问。
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p>
方式2:通过服务名称进行访问
root@sise-7cfd9b6578-55h4w:/usr/src/app# wget -O- nginx
输出如下:它会自动把服务名称解析成对应的虚拟IP。
--2019-11-11 05:44:03-- http://nginx/
Resolving nginx (nginx)... 10.102.53.115
Connecting to nginx (nginx)|10.102.53.115|:80... connected.
HTTP request sent, awaiting response... 200 OK
...
方式3:通过环境变量的方式进行访问
先通过env命令查看一下环境变量是否已经成功设置:
root@sise-7cfd9b6578-55h4w:/usr/src/app# env
HOSTNAME=sise-7cfd9b6578-55h4w
GPG_KEY=C01E1CAD5EA2C4F0B8E3571504C367C218ADD4FF
KUBERNETES_PORT=tcp://10.96.0.1:443
KUBERNETES_PORT_443_TCP_PORT=443
TERM=xterm
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_HOST=10.96.0.1
NGINX_SERVICE_HOST=10.102.53.115 # 说明已经成功注入
NGINX_PORT_80_TCP_PROTO=tcp
...
然后执行wget -O- $NGINX_SERVICE_HOST,效果是一样的。
4)修改服务类型,从集群外部访问服务
上面实验中的Service Type是ClusterIP,现在把它修改成LoadBalancer,修改Service.yaml文件如下:
apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer # 新增Service Type为LoadBalancer(默认为ClusterIP)
然后更新该service:
#kubectl apply -f service.yaml
现在再看一下这个service有什么不同
# kubectl get svc nginx -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx LoadBalancer 10.102.53.115 <pending> 80:31338/TCP 49m run=nginx
发现,TYPE 字段已经变成了 LoadBalancer,但 EXTERNAL-IP 字段的值一直没出来,这是因为,我的集群环境是在本机的虚拟机中搭建的,关于这个问题详细解释,详见kubernetes-service-external-ip-pending。
如果在云厂商提供的环境中搭建的集群,那么就会正常显示EXTERNAL-IP,然后可以从外部直接访问这个EXTERNAL-IP,就可以访问pod提供的服务了。
最后,需要强调的是,pod的生命周期和Service生命周期是没有关系的,我们可以delete掉当前这两个Pod,Deployment根据副本数会自动帮我们新创建两个pod,这时候新创建的pod和刚刚被删掉的pod的pod ip是不一样的,但Service对外提供的虚拟IP却是始终没变过。这也就是为什么要抽象出Service的原因之一。