论文:Xception: Deep Learning with Depthwise Separable Convolutions
论文链接:https://arxiv.org/abs/1610.02357
算法详解:
Xception是google继Inception后提出的对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。
要介绍Xception的话,需要先从Inception讲起,Inception v3的结构图如下Figure1。当时提出Inception的初衷可以认为是:特征的提取和传递可以通过1*1卷积,3*3卷积,5*5卷积,pooling等,到底哪种才是最好的提取特征方式呢?Inception结构将这个疑问留给网络自己训练,也就是将一个输入同时输给这几种提取特征方式,然后做concat。Inception v3和Inception v1(googleNet)对比主要是将5*5卷积换成两个3*3卷积层的叠加。
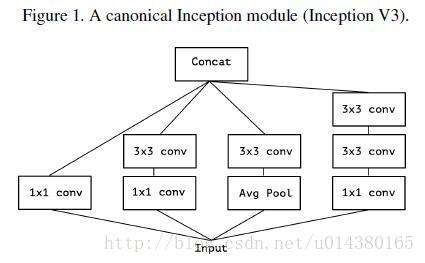
于是从Inception v3联想到了一个简化的Inception结构,就是Figure 2。
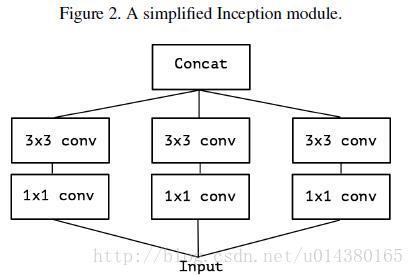
再将Figure2延伸,就有了Figure3,Figure3表示对于一个输入,先用一个统一的1*1卷积核卷积,然后连接3个3*3的卷积,这3个卷积操作只将前面1*1卷积结果中的一部分作为自己的输入(这里是将1/3channel作为每个3*3卷积的输入)。再从Figure3延伸就得到Figure4,也就是3*3卷积的个数和1*1卷积的输出channel个数一样,每个3*3卷积都是和1个输入chuannel做卷积。

铺垫了这么多,终于要讲到Xception了。在Xception中主要采用depthwise separable convolution,什么是depthwise separable convolution?这是mobileNet里面的内容,可以参考另一篇博文:mobileNets-深度学习模型的加速。这里简单介绍下:下图就是depthwise separable convolution的示意图,其实就是将传统的卷积操作分成两步,假设原来是3*3的卷积,那么depthwise separable convolution就是先用M个3*3卷积核一对一卷积输入的M个feature map,不求和,生成M个结果;然后用N个1*1的卷积核正常卷积前面生成的M个结果,求和,最后生成N个结果。因此文章中将depthwise separable convolution分成两步,一步叫depthwise convolution,就是下图的(b),另一步是pointwise convolution,就是下图的(c)。
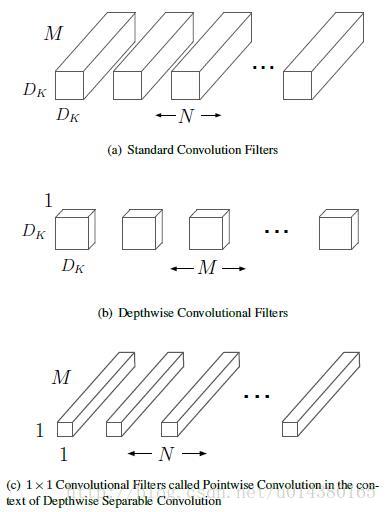
其实depthwise separable convolution和上面的Figure4是很像的。差别有两个:1、顺序不一样,在depthwise separable convolution中是先进行一个channel-wise的spatial convolution,也就是上图的(b),然后是1*1的卷积。而在Figure4中是先进行1*1的卷积,再进行channel-wise的spatial convolution,最后concat。2、在Figure4中,每个操作后都有一个ReLU的非线性激活,但是在depthwise separable convolution中没有。
那么作者为什么要采用depthwise separable convolution操作呢?就是从Figure1到Figure4的关于Inception v3结构的不断延伸,然后Figure4基本上和depthwise separable convolution没有太大的区别,于是就有了引入depthwise separable convolution修改Inception v3结构的Xception。
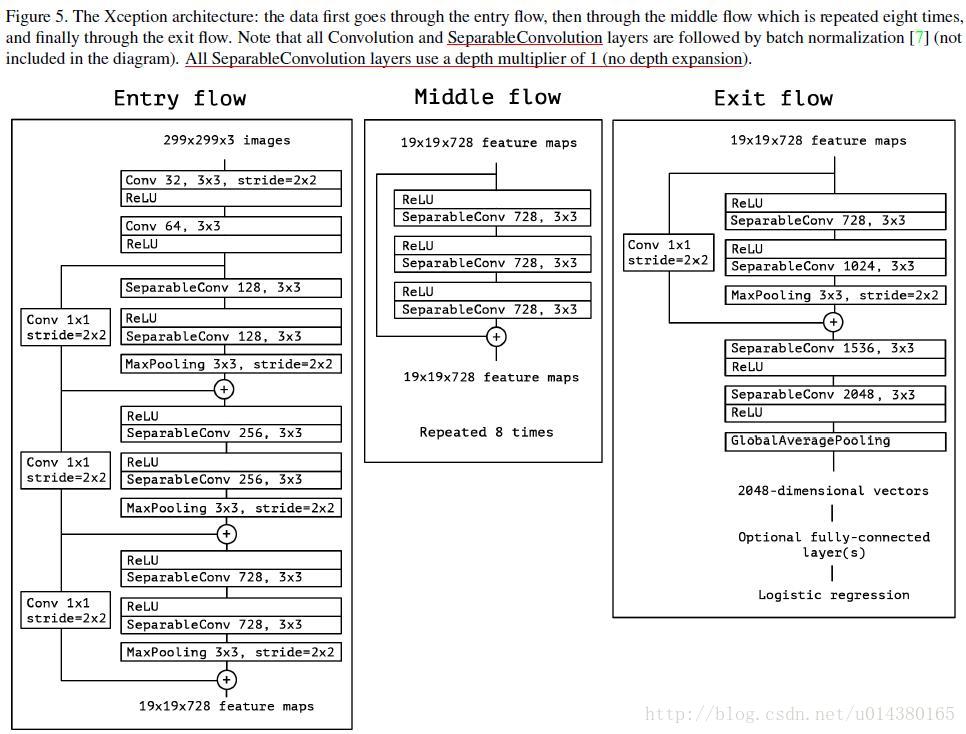
Figure5是Xception的结构图。这里的sparsableConv就是depthwise separable convolution。另外,每个小块的连接采用的是residule connection(图中的加号),而不是原Inception中的concat。
实验结果:
Table1表示几种网络结构在ImageNet上的对比。
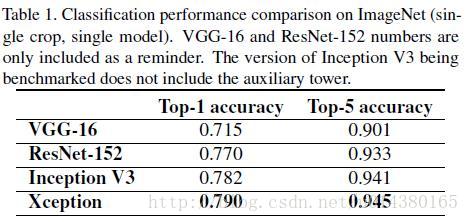
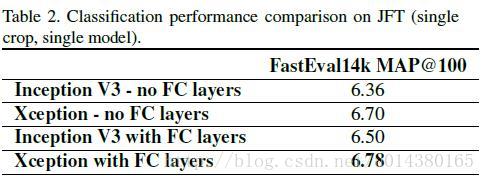
Table2表示几种网络结构在JFT数据集上的对比。大数据上的提升会比Table1好一点。
其他更多的实验结果可以参考论文。
总结:
Xception作为Inception v3的改进,主要是在Inception v3的基础上引入了depthwise separable convolution,在基本不增加网络复杂度的前提下提高了模型的效果。有些人会好奇为什么引入depthwise separable convolution没有大大降低网络的复杂度,因为depthwise separable convolution在mobileNet中主要就是为了降低网络的复杂度而设计的。原因是作者加宽了网络,使得参数数量和Inception v3差不多,然后在这前提下比较性能。因此Xception目的不在于模型压缩,而是提高性能。
Introduction
GoogleNet论文中研究 group size 而搞出了Inceptionv1(即多group的CNN分支)。此后,Inception不断迭代,group size被越玩越复杂,一直发展到了v4版本。
这时,Inception的鼻祖Google团队又提出了 Extreme Inception ,即赫赫有名的 Xception 。只不过,这次不再是之前的 并行式group 了,取而代之的是 串行式group 。
具体来说,就是:
在channel上进行逐片分治,然后group之。
而这一 串行式group 的module,被起名 separable convolution 。
separable convolution是通过如下图所示(图片来源:Xception: Deep Learning with Depthwise Separable Convolutions)的演化而诞生的:

从此,group操作进入了“串行”时代。
传统的卷积操作如下图:

而separable convolution的操作如下图:

完整的一个SeparableConv组合如下图(图片来源):

整个网络结构并没有太多的创新点,可以视为将ResNeXt的Inception module替换为SeparableConv module:

换言之:
Xception是ResNeXt的一个变种。
Note:
- 我们平常所说的Xception145,其实指的是模型大小为145M的Xception。145并非层数。
Innovation
并行式group –> 串行式group 。
在SeparableConv module看来,channel之间的信息融合,交给Conv1×1就够了:

channel数个Conv3×3则只需对单channel负责,这样就可以更专心地学到本channel的location信息:

两部分各司其职,共同组成了SeparableConv module。
Result
经过实验,Xception在ImageNet上稍优于Inceptionv3:

参数数量和Inceptionv3基本一致,速度也差不多:

在ImageNet上的收敛情况也好于Inceptionv3:

Thinking
对于Xception的串行式group为什么会优于Inceptionv3的并行式group,并且在ImageNet上取得了更好地分类结果,我还是觉得百思不得其解。如果先出来Xception,再出来Inceptionv3,且Inceptionv3的分类效果更好,那么又可以吹出一个貌似“有理有据”的故事。
另外,Xception取代ResNet作为Detection算法的basemodel,从而提高算法速度和减少模型参数,是目前被普遍接受的一种做法。
Xception145、Xception39是Xception中最大和最小的两种version。
Xception的速度几乎比ResNet 快 了 一个数量级 。
[1] Xception: Deep Learning with Depthwise Separable Convolutions
[2] Google Xception Network