@
0. 论文地址
http://arxiv.org/pdf/1311.2901.pdf
1. 概述
本文设计了一种可以可视化卷积层中feature map的系统,通过可视化每层layer的某些activation来探究CNN网络究竟是怎样“学习”的,同时文章通过可视化了AlexNet发现了因为结构问题,导致有“影像重叠”(aliasing artifacts),因此对网络进行了改进,设计出了ZF-Net。
文章通过把activation(feature map中的数值)映射回输入像素的空间,去了解什么样的输入模式会生成feature map中的一个给定activation,这个模型主要通过反卷积(deconvolution),反向池化(Unpooling)与“反向激活”(Rectification),其实就是把整个CNN网络倒过来,另外值得说一下的是,并不是完全倒过来,只是近似,所有的“反向”操作都是近似,主要是使得从各层layer的尺度还原到在原始图像中相应大小的尺度。
同时文章还分析了每层layer学习到了什么,以及可视化最强activation的演化过程来关系模型的收敛过程,同时也利用遮挡某些部位来学习CNN是学习object本身还是周围环境。
2. 可视化结构
2.1 Unpooling
要想完全还原max-pooling是不太现实的,除非记录每一层feature,那有些得不偿失,文章通过记录池化过程中最大激活值所在位置以及数值,在uppooling的时候,还原那个数值,其他的位置设为0,从而近似“反向池化”,具体如下图:
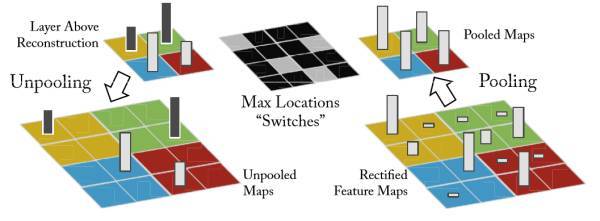
2.2 Rectification:
CNN使用ReLU确保每层输出的激活之都是正数,因此对于反向过程,同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
2.3 Filtering:
卷积过程使用学习到的过滤器对feature map进行卷积,为近似反转这个过程,反卷积使用该卷积核的转置来进行卷积操作
注意在上述重构过程中没有使用任何对比度归一化操作
ps: 反卷积(转置卷积)的原理我会重新整理博客,之后再加进来。
3. Feature Visualization
在ImageNet验证集上使用反卷积进行特征图的可视化,如下图:

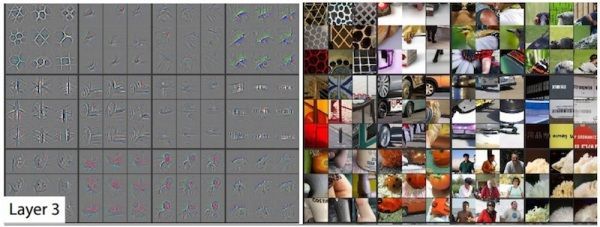

对于一个给定的feature map,我们展示了响应最大的九张响应图,每个响应图向下映射到原图像素空间,右面的原图通过找到在原图的感受野来截取对应的原图。
通过观察可以发现,来自每个层中的投影显示出网络中特征的分层特性。第二层响应角落和其他的边缘/颜色信息,层三具有更复杂的不变性,捕获相似的纹理,层四显示了显著的变化,并且更加类别具体化,层五则显示了具有显著姿态变化的整个对象,所以这就是常说的CNN结构前几层通常学习简单的线条纹理,一些共性特征,后面将这些特征组合成 不同的更丰富的语义内容。
4. Feature Evolution during Training
文中对于一个layer中给定的feature map,图中给出在训练epochs在[1,2,5,10,20,30,40,64]时,训练集对该feature map响应最大的可视化图片,如下图:

从图中可以看出,较低层(L1,L2)只需要几个epochs就可以完全收敛,而高层(L5)则需要很多次迭代,需要让模型完全收敛之后。这一点正好与深层网络的梯度弥散现象正好相反,但是这种底层先收敛,然后高层再收敛的现象也很符合直观。
5. Feature Invariance
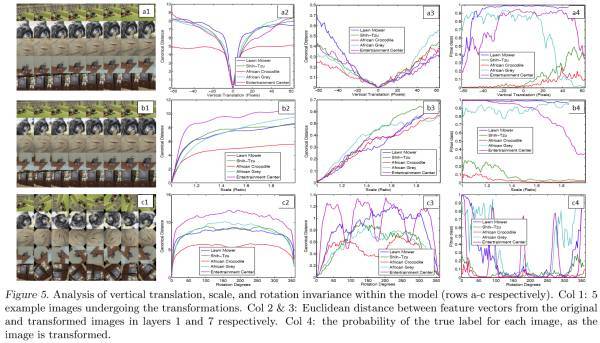
上图显示出了相对于未变换的特征,通过垂直平移,旋转和缩放的5个样本图像在可视化过程中的变化。小变换对模型的第一层有着显著的影响,但对顶层影响较小,对于平移和缩放是准线性的。网络输出对于平移和缩放是稳定的。但是一般来说,除了具有旋转对称性的物体来说,输出来旋转来说是不稳定的.(这说明了卷积操作对于平移和缩放具有很好的不变性,而对于旋转的不变性较差)
6. ZF-Net

可视化训练模型不但可以洞察CNN的操作,也可以帮助我们在前几层选择更好的模型架构。通过可视化AlexNet的前两层(图中b,d),我们就可以看出问题:
1)第一层filter是非常高频和低频的信息,中间频率的filter很少覆盖
2)第二层的可视化有些具有混叠效应,由于第一层比较大的stride
为了解决这些问题:
1)将第一层的filter的尺寸从1111减到77
2)缩小间隔,从4变为2。
这两个改动形成的新结构,获取了更多的信息,而且提升了分类准确率。
7. 实验
首先,作者进行了网络结构尺寸调整实验。去除掉包含大部分网络参数最后两个全连接层之后,网络性能下降很少;去掉中间两层卷积层之后,网络性能下降也很少;但是当把上述的全连接层和卷积层都去掉之后,网络性能急剧下降,由此作者得出结论:模型深度对于模型性能很重要,存在一个最小深度,当小于此深度时,模型性能大幅下降。
作者固定了通过ImageNet pre-train网络的权值,只是使用新数据训练了softmax分类器,效果非常好。这就形成了目前的人们对于卷积神经网络的共识:卷积网络相当于一个特征提取器。特征提取器是通用的,因为ImageNet数据量,类别多,所以由ImageNet训练出来的特征提取器更具有普遍性。也正是因为此,目前的卷积神经网络的Backbone Network基本上都是Imagenet上训练出来的网络。
8. 简单的可视化工具
数字识别
其中黑色和灰色表示负值,越黑越负;绿色表示正值,越亮越正
9. 参考链接
https://cloud.tencent.com/developer/article/1087075
https://www.jianshu.com/p/0718963bf3b5