程序猿
程序猿
python--scrapy框架爬取分页数据与详情页数据
我们以abckg网址为例演示。
首先爬取详情页。
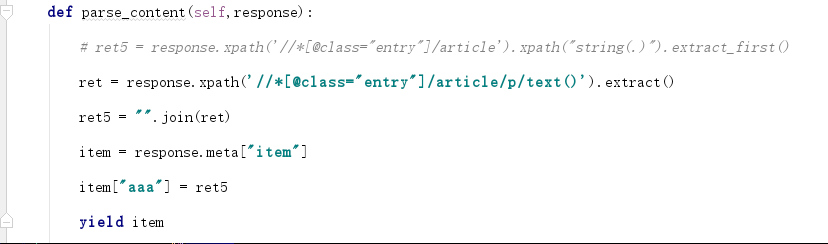
另外一种解析内容页:
然后是爬取分页:
还有一种方法就是设置一个方法循环爬取:
【推广】
免费学中医,健康全家人
原文地址:https://www.cnblogs.com/kitshenqing/p/11047468.html
推荐文章
android 放大镜ShapeDrawable妙用
jQuery.protoype.xxx=function(){}
【转载】 input 和 textarea 最大文字限定插件
jQuery扩展写法
JQuery方法查询
[转载]jQuery 输入框 在光标位置插入内容, 并选中
[转载]jquery 动态滚动
[转载]浅析jQuery框架与构造对象
【转载】JS 获取浏览器窗口大小
【转载】C# ??(问问,问号问号)运算符,可空值(申明加?(问号))的克星
【转载】jQuery学习笔记
索引使用简介
oracle里的常用命令详解
CHAR,VARCHAR,VARCHAR2类型的区别与使用
如何连接oracle数据库及故障解决办法-总结 极力推荐
非常实用的,使用SQL查询连续号码段。(做计费系统或SP的兄弟经常会用到)
poj1469
poj1456
poj1470
poj1459
poj1466
vc剪贴板
【转帖】BCGControlBar使用心得如何捕获Workspace bar类上的树控件的消息
Windows API一日一练
BCG 使用CBCGPToolbarFontSizeCombo 时下拉框无内容
VB API教程 王国荣
用API 现成的函数处理工程退出时的文件保存
VC 剪贴板操作
BCG中使用状态栏显示状态信息
界面库