先让我们看看一张网页是怎么来的,也就是从用户输入完一个网址点下“ENTER”键到整个页面加载出来中间发生了什么。首先我们了解下HTTP过程:
一、寻找IP(每一步都是在上一步没找到的情况下进行的)
本地阶段:
1、浏览器搜索自身缓存;
2、搜索操作系统自身的DNS缓存;
3、地区本地HOST文件;
4、浏览器发送DNS系统调用;
路由阶段:
1、宽带运营商服务器查看本地缓存;
2、运营商服务器发起一个迭代DNS解析请求;
com -> baidu.com -> www.baidu.com
3、运营商服务器把结果返回给操作系统内核同时缓存起来;
4、操作系统内核把结果返回个浏览器
浏览器得到IP了。
二、建立连接并获取内容
1、发起HTTP三次握手,建立TCP/IP连接;
2、发起HTTP请求;
3、服务器端读取数据库并处理数据后返回页面内容;
这样获得了一个页面,但是页面的js文件、css文件、图片都要经过这样的过程!
4、渲染页面;
我们写baidu.com和www.baidu.com同样都会跳转到百度首页,但是baidu.com是经过了一次301页面跳转到www.baidu.com的,多了一次DNS查询;
常见状态码: 1xx 请求已接受 2xx 处理完毕 3xx 重定向 4xx 客户端错误 5xx 服务器端错误 200 OK成功 400 客户端语法错误 401 没有经过授权 403 拒绝服务 404 没找到页面 500 错误 503 不能处理
三、渲染页面

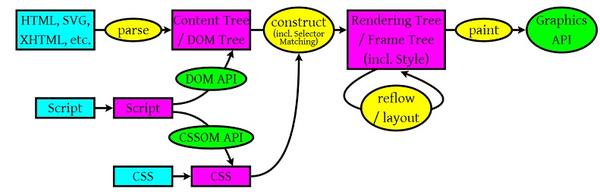
1)浏览器会解析三个东西:
一个是HTML/SVG/XHTML,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
CSS,解析CSS会产生CSS规则树。
Javascript,脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree.
2)解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。注意:
Rendering Tree 渲染树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加上Rendering Tree上的每个Element。也就是DOM结点。也就是所谓的Frame。
然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI的API绘制。
实际上这个过程非常复杂,某些地方的顺序也随着脚本、网络等情况的不同而不同,这里只是个简略介绍。
四、重头戏:优化。
- 尽量减少HTTP请求
- 使用内容发布网络(CDN加速的使用)
- 添加Expires头
- 压缩组件(使用Gzip方式)
- 将CSS样式表放在顶部
- 将javascript脚本放在底部
- 避免使用CSS表达式
- 使用外部javascript和CSS
- 减少DNS查询
- 精简javascript
- 避免重定向
- 删除重复脚本
- 配置ETag
- 使ajax可缓存
1、压缩脚本,合并文件,去掉空格换行等,使用外部文件js,有利于缓存。将js放到最后,让用户先看到页面,提升用户体验。
2、css放在head标签内,防止无样式闪烁。
3、不要这样写:<a href='https://www.baidu.com'>百度</a>,要这样写:<a href='https://www.baidu.com/'>百度</a>。
4、压缩图片,使用雪碧图等。
5、避免使用CSS表达式,有人说只能在IE里用的东西没有什么好东西。
6、使用 <link> 而不是 @importChoose <link> over @import,这样相当于把CSS放到文件最下面。
7、页面展现尽量只让CSS做。
8、减少DOM操作,信息传递尽量使用JSON。
9、避免重绘,可以通过使用css或者绝对定位减少影响范围。
10、减少Cookie的使用并尽量使cookie小。