前几天接到的一个需求,处理一堆doc和pdf,提取相应内容输出到xls里。经过一天的努力,正常的文件都顺利解决。还有一部分pdf是解决不了的,原因是pdf内部文字所使用的编码在本机没有。从pdf中提取出来的内容都会变成!@#$之类的符号(很明显是编码问题)。
试了很多方法,最后无奈选择OCR。
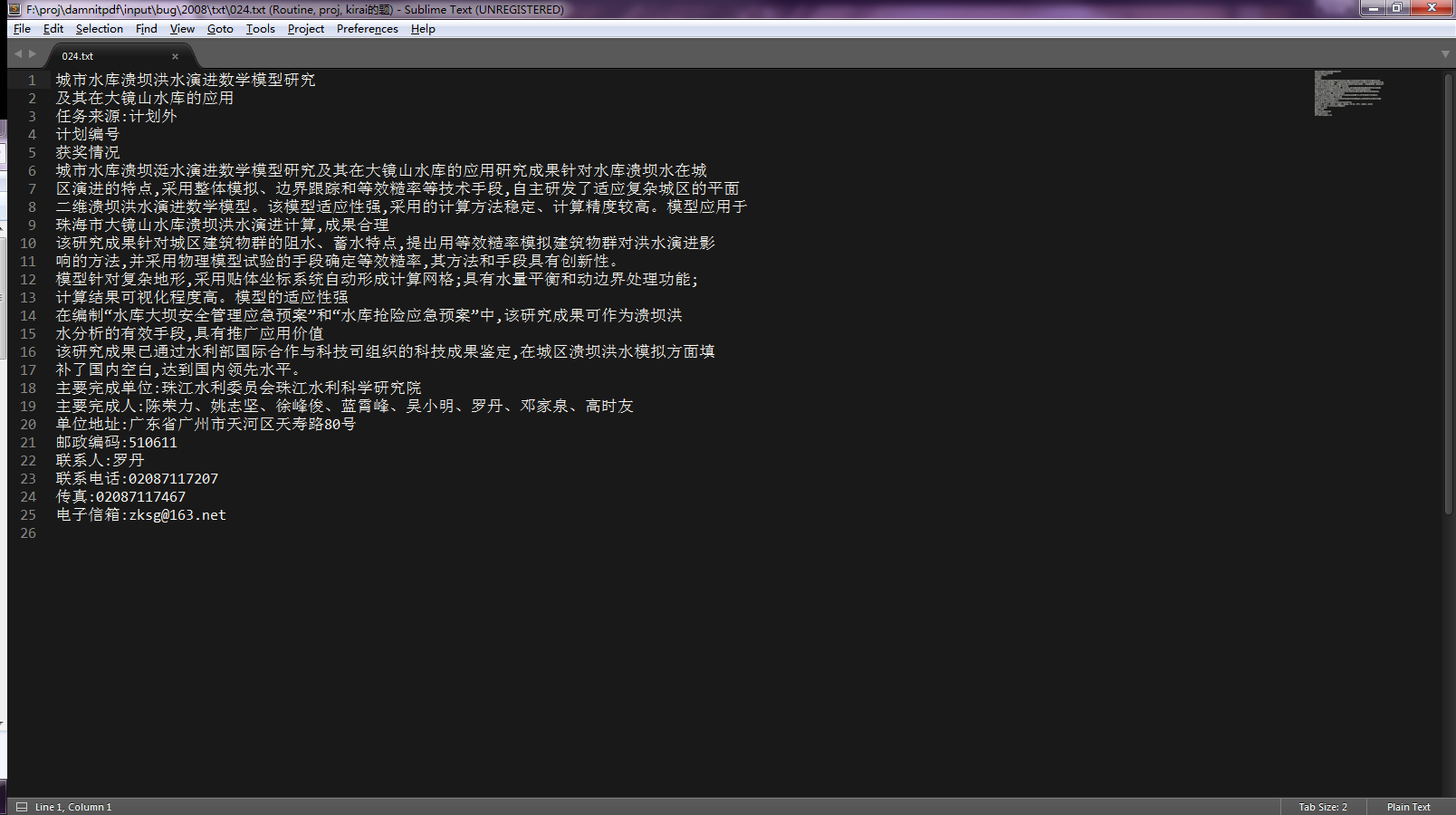
每一页的pdf是这个样子的:

首先使用了acrobat和pitstop插件把所有的图片都处理掉,这样做ocr的结果会精确。导出成图片:

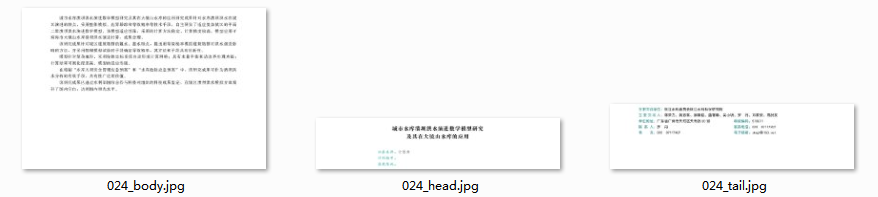
测试了百度的API,一整页丢进去效果不是很好,所以拆分一下再丢。拆成这样:


1 #-*- coding: utf-8 -*- 2 import cv2 3 import os 4 5 6 def rename(path): 7 """ 8 批量改名,因为opencv不能传中文path 9 :param path: 10 :return: 11 """ 12 files = os.listdir(path) 13 for file in files: 14 tmp = file[7:] 15 os.rename(path+file, path+tmp) 16 17 18 TOTAL_PAGE_NUM = 200 19 ROOT_PATH = '../input/bug/2008_o/' 20 SAVE_PATH = '../input/bug/2008/' 21 22 def _cut_pic(id, from_path, save_path): 23 """ 24 切分成3部分,便于识别 25 :param from_path: 26 :param save_path: 27 :return: 28 """ 29 img = cv2.imread(from_path) 30 head = img[300:650, 1:2000] 31 body = img[660:1750, 1:2000] 32 tail = img[1760:2200, 1:2000] 33 cv2.imwrite(save_path+id+'_head.jpg', head) 34 cv2.imwrite(save_path+id+'_body.jpg', body) 35 cv2.imwrite(save_path+id+'_tail.jpg', tail) 36 37 def cut_pic(): 38 for i in range(10, TOTAL_PAGE_NUM): 39 file_path = ROOT_PATH + str(i).zfill(3) + '.jpg' 40 try: 41 with open(file_path, 'r') as fp: 42 fp.close() 43 _cut_pic(str(i).zfill(3), file_path, SAVE_PATH) 44 except IOError: 45 print 'No such file: ', file_path 46 47 if __name__ == '__main__': 48 cut_pic()
调用百度的OCR API就可以了。
1 #-*- coding: utf-8 -*- 2 from aip import AipOcr 3 import SCRET_KEY 4 5 ACCESS_TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token' 6 API_KEY = 'cxmz9yjUUoi1yGWt5OQqH0WL' 7 SCRET_KEY = SCRET_KEY.SECRET_KEY 8 APP_ID = '9413565' 9 IMG_LOCATE = 'C:/Users/Kazakiri/Desktop/010_body.jpg' 10 11 12 def get_img(img_file): 13 """ 14 获取图片文件 15 :param img_file: 16 :return: 返回file对象 17 :rtype: file object 18 """ 19 with open(img_file, 'rb') as fp: 20 return fp.read() 21 22 def get_text_content(img_locate): 23 """ 24 返回文字内容 25 :param img_locate: 26 :return: 27 """ 28 aip_ocr = AipOcr(APP_ID, API_KEY, SCRET_KEY) 29 result = aip_ocr.general(get_img(img_locate)) 30 txt = '' 31 for each in result['words_result']: 32 txt += each['words'] + ' ' 33 return txt.encode('utf-8')
输出:
1 #-*- coding: utf-8 -*- 2 import cv2 3 import os 4 import GetOcrFromBaidu 5 6 TOTAL_PAGE_NUM = 200 7 ORG_PATH = '../input/bug/2010_o/' 8 PART_PATH = '../input/bug/2010/' 9 SAVE_PATH = '../input/bug/2010/txt/' 10 11 12 def _get_orc_result(id): 13 head_path = PART_PATH + id + '_head.jpg' 14 body_path = PART_PATH + id + '_body.jpg' 15 tail_path = PART_PATH + id + '_tail.jpg' 16 head = GetOcrFromBaidu.get_text_content(head_path) 17 body = GetOcrFromBaidu.get_text_content(body_path) 18 tail = GetOcrFromBaidu.get_text_content(tail_path) 19 fp = open(SAVE_PATH+id+'.txt', 'w') 20 fp.write(head+body+tail) 21 fp.close() 22 23 def get_orc_result(): 24 for i in range(10, TOTAL_PAGE_NUM): 25 file_path = ORG_PATH + str(i).zfill(3) + '.jpg' 26 try: 27 with open(file_path, 'r') as fp: 28 fp.close() 29 _get_orc_result(str(i).zfill(3)) 30 except IOError: 31 print 'No such file: ', file_path 32 33 if __name__ == '__main__': 34 get_orc_result()
结果: