一.redis五大数据类型,特性及应用场景
1.string
字符串有两种存储方式,在长度特别短时,使用embstr形势存储,而长度超过44字节时候,使用raw形势存储
使用场景:1、访问量统计:每次访问博客和文章使用 INCR 命令进行递增
2.hash
适合存储对象,
使用场景:存储、读取、修改对象属性,比如:用户(姓名、性别、爱好),文章(标题、发布时间、作者、内容)
3.list
使用场景:最新消息排行等功能
4.Set
结构底层实现是字典,只不过所有的value都是NULL,其他的特性和字典一摸一样。所以内部的键值对是唯一的,无序的。可实现去重操作。
为集合提供了求交集、并集、差集等操作,共同好友
5.zSet
和set相比,是有顺序的,一方面是一个set,保证内部value的唯一性,另一方面可以给每个value赋予一个score,代表这个value的排序权重。排行榜,取TopN操作
二,缓存穿透,雪崩,击穿
参考地址:Redis 面试常见问题———缓存雪崩、缓存击穿以及缓存穿透 - jeremylai - 博客园 (cnblogs.com)
2.1穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库
解决办法:简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉
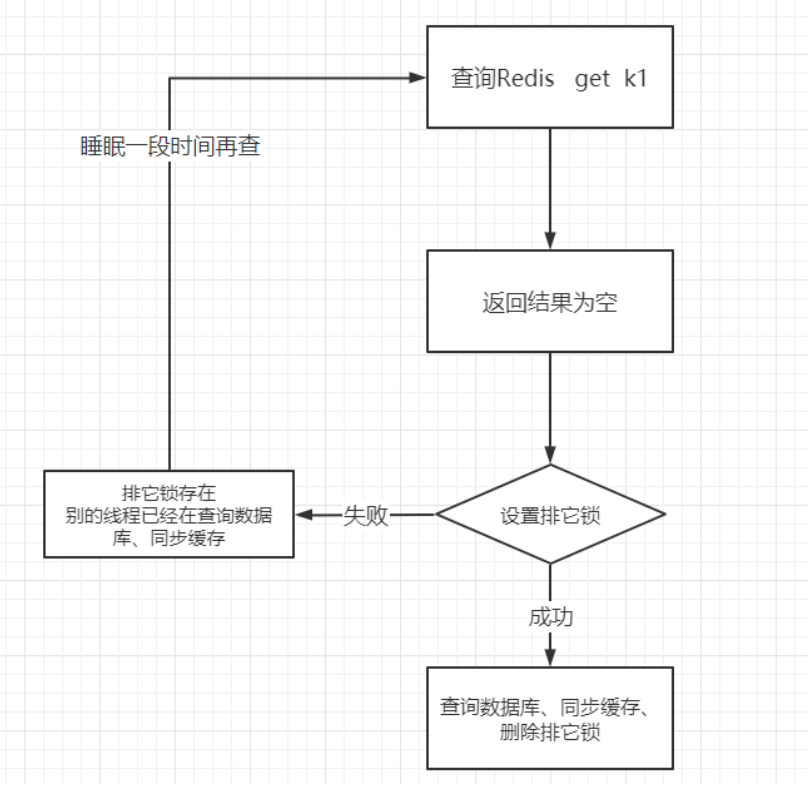
2.2击穿:往往是热点数据,key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。 使用互斥锁。
public String get(key) { String value = redis.get(key); if (value == null) { //代表缓存值过期 //设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功 value = db.get(key); redis.set(key, value, expire_secs); redis.del(key_mutex); } else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可 sleep(50); get(key); //重试 } } else { return value; } }
2.3雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
解决方法:还有一个简单方案就将缓存失效时间分散开。