背景
最近在学习DDIA(Designing Data-Intensive Applications)这本分布式领域非常经典的入门书籍,里面第二章《数据模型与查询语言》,强调了一对多、多对一、多对多等各种不同的数据关系进行建模时要怎样选择合适的数据库模型,并重点阐述了关系型数据库(如PostgreSQL、MySQL)、文档性数据库(MongoDB)、以及近几年大热的图数据库在不同数据关系建模时的使用,整个学习过程中收益匪浅。其中为了加强对相关知识的理解消化,又选择了一些重点的资料进行阅读。
今天要翻译的这一篇《 Why You Should Never Use MongoDB》便是其中一篇关于多对一场景下选择文档数据库MongoDB时,为什么有时会对应用的拓展造成灾难性后果的阐述。读完之后,相信我们会对文档性数据库为什么特别适合在多对一场景下使用,以及如果使用不当会造成什么样的后果由非常清晰的认识。
特别说明下:这一篇文章的标题有夸大的嫌疑,将MongoDB在实际产品开发中的应用视为灾难级的。但其实在适当的场景下使用MongoDB会使得应用在数据表现力方面取得极大的便利性。另外这篇文章的年头也有点久了(2013年发表的),当前最新的MongoDB在数据聚合等方面也做了很多改进。但是之所以这篇文章我感觉它的价值还很大,其实就在于作者对文档性数据库的使用阐述得特别详细,非常适合我们理解多对一关系以及文档性数据库的使用原理。
文章很长,整个翻译大致需要一周左右时间,一点点放进来的。还是一样,如果想要完全理解文章的内容,必须对文档性数据库在‘多对一’关系数据中的应用场合有所了解,而DDIA绝对是最好的入门读物。
---------------------以下开始是原文翻译------------------------------
为什么你永远都不要使用MongoDB
声明:我的工作并不是开发数据库引擎,我开发web应用。每年我都会主导管理4-6个项目的开发工作,因此,我开发了很多的web 应用。在这个过程中,我发现每一个应用都有不同的需求,需要不同的数据库引擎。所以,我使用过很多不同的数据存储组件或应用,基本上所有你们听到过的数据存储应用我都使用过,其中有一些你们可能从来没有听说过。
在我的职业生涯中,我碰到过少数几次数据存储组件选择失误的例子。这里我将分享其中一个选择错误的例子,包括为什么最初我们会选择它,我们是怎么发现这个选择是错误的,最后又是怎么去修复它,整个过程都发生在Diaspora这个开源项目中。
项目
Diaspora是一个背后有着复杂故事的分布式社交网络应用。时间回退到2010年,四个来自纽约大学的本科生在Kickstarter上发布一个众筹$10,000的视频,目的是利用一个暑假的时间开发一个可以替换Facebook的分布式社交网络应用。他们将这个想法推送给加人、朋友,期望得到一个好的结果。
他们真的是踩在点上,那个时候Facebook正好暴露出一个关于用户隐私的丑闻。所以当他们在Kickstarter发布这个想法的时候,获得了来自6400多人高达200,000美刀的支持,而这些支持仅仅是为了一个一行代码都没有的一个软件项目。
Diaspora是第一个众筹金额远远超过其初期目标的Kickstarter项目。因此,一篇他们事迹的文章被发表在纽约时报上,但是这里有一个小插曲,由于在团队照片的背景图上的一个黑板上面写着一个黄色的笑话,且直到文章在纽约时报上出版的时候都没有人发现,所以这篇文章也导致了一些丑闻。也因此,我才第一次了解到这个项目。
得益于他们众筹项目的成功,这些家伙离开了学校来到旧金山开始为这个项目开发代码。他们最终落脚在我工作的地方。那个时候我在Pivotal实验室工作,这些家伙里的其中一个的哥哥也在这个实验室工作,所以Pivotal免费为他们提供办公位置、网络,当然也包括冰啤酒。那段时间我主要服务于官方的客户,在下班的时候就跟他们一些并且在周末的时候为项目贡献代码。
最后,他们在实验室呆了超过两年的时间,在第一个暑假结束额时候,他们已经有一个很小的,但是在某种意义上来讲已经可用的分布式社交网络的实现,这个实现开发语言是Ruby on Rails,后端的数据库是MongoDB。
套用一个流行词,让我们慢慢来解剖这个项目。
分布式社交网络
如果你了解过社交网络的话,那么你已经知道了所有关于Facebook你需要知道的东西。说白了社交网络就是一个运行在一个单一的逻辑服务器上面且让你可以跟别人保持联系的web应用。当你登陆应用后,Diaspora的界面结构看起来跟Facebook相似:
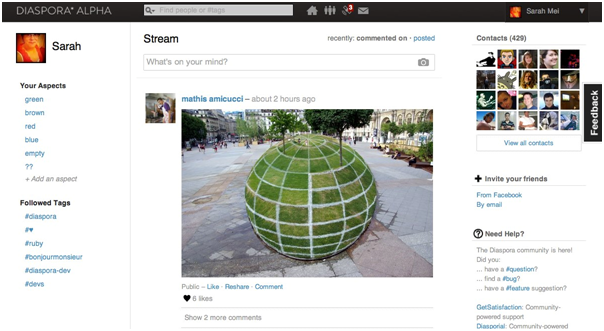
在页面的中间展示的是好友的发布事件流。在两边则是没有人回去关注,随便填充的乱七八糟的东西。Diaspora跟Facebook在技术上最重要的区别是终端用户看不到的,这个区别就是‘分布式’的部分。
Diaspora的基础架构并不是部署在一个单一的web地址上,而是部署在几百台各自独立的Diaspora服务器上。Diaspora的代码是开源的,因此如果你愿意的话,你也可以在你自己的服务器上面部署一个Diaspora服务。每一个Diaspora服务都叫做一个POD,都有自己的数据库以及用户集,而且将与其他所有的Diaspora服务彼此之间相互交互数据。
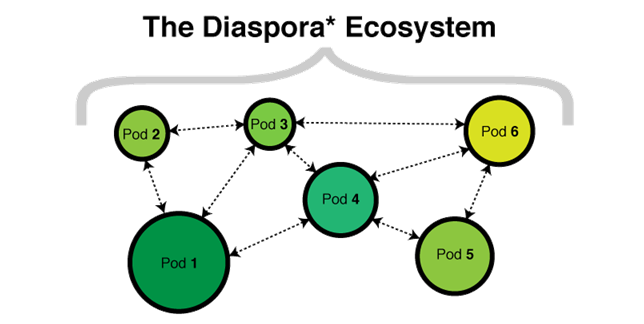
每一个POD都与其他的pod通过HTTP接口进行消息交互。当你在其中一个pod上面创建一个账号后,如果你没有关注其他人(就是当被人的粉丝),那其实是相当无聊的。你可以关注同一个pod上的用户,也可以关注跟你处于不同pod上面的用户。当某个你关注的用户在其他pod上面发布一条状态的时候,会发生下面的几件事:
1、这条状态存储到发布者坐在pod的数据库上。
2、你所在的pod会通过HTTP接口收到通知;
3、这条状态会被被保存在你所在pod的数据库上
4、当你刷新新的事件流时,会看到这条更新的状态会跟随其他你关注的人的状态一起展现在你的最新事件流上。
评论也是同样的方式,每一条的状态的所有评论,有一些是来自于跟发布者用同一个pod上的用户,有一些是来自于其他pod上面的用户。每一个有权限查看状态的用户都可以看到这些所有的评论,就像你在那些部属单一逻辑服务器上的其他应用所期待的那样。
谁在意呢?
这个架构有技术上跟法律上的优点。技术上最主要的优点是容错性。

任何一个pod崩溃了,都不会影响到其他的pod的正常运行。系统任然可用,即使发生网络分区,这个特性有一些非常有趣的隐含意义,例如,如果你所在的国家切断了外部的网络,禁止你访问Facebook and Twitter,你所在的本地pod任然可以让你跟同一个过年的用户进行联系,即使任何外部的东西你都访问不到。
法律上最重要的优点是服务的独立性。每一个pod都是一个独立的实体,受部署所在地的法律约束。每一个pod都有各自的服务声明,对于绝大多数的pod而言,你可以在上面发布内容并且不需要放弃你的权利(译者注:这里应该是数据的所有者权利),而不像在Facebook那样,你自己无法拥有数据。Diaspora是一个拥有‘自由’、‘免费’标签的软件,大多数完pod的人都是非常在意这两点的。
上述就是整个系统级别的大致架构,下面我们一起看下单个pod内部的架构。
这是一个Rails的应用
每个pod都是依赖一个后端数据库的Ruby on Rails的web应用,后端数据库最初是MongoDB。某种意义上来讲,整个工程的代码库就是一个典型的Rails应用,拥有一个可视化且可编程的用户界面,一些Ruby代码,还有一个数据库。但是从另外一个角度上讲它有含有任何东西但且是经典的。
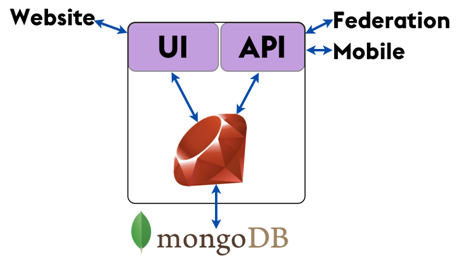
可视化的界面当然是定义网站用户怎样跟Diaspora交互的方式。API接口一个很重要的作用是服务于大量的移动端用户,另外API接口也用于构建联盟,联盟这个词用来描述pod内部之间相互交互的技术用意。应为分布式的本质使得在基础代码上构建了增加了几层的应用,而这些额外的应用是不会出现在一个典型的应用中的。
当然,使用MongoDB来作为数据存储是一个非典型的选择。基本上绝大多数的Rails应用都会选择PostgreSQL作为后端的数据库存储或者Mysql。
上述我们分析了代码,接下来让我们将目光转移到我们存储了哪些类型的数据。
我认为这个词的意思并不是你想象中的意思
‘社交数据’是关于我们自己的朋友网络,朋友们各自的朋友网络,以及所有人在这个大网络中的活动事件。从概念上来讲,我们将‘社交数据’当成这样一个网络:我们处于网络的中心,而我们的朋友从这个中心往外扩散并由此形成的一个没有方向的图。

任何时候我们存储社交数据,其实就是在存储上述的拓扑图,还有所有在这个拓扑图的边上流动的活动事件。
过去几年,我们一直在听到这样一个貌似聪明的论断:社交数据并不是关系型的,如果你讲这些数据存储在关系型数据库上,那么你就做错啦。
那我们有什么其他的选择吗?一些家伙可能会说图数据库是最自然的选择,但是在这里我不想讨论这个图数据库话题,因为他目前还是很小众的不适合用于实际产品中。另外一些家伙可能会说文档型数据库最匹配社交关系数据了,而且在实际的应用中也足够主流。下面让我们一起看一下,为什么有人会认为MongoDB会比PostgreSQL更适合社交数据的存储。
MongoDB是怎样存储数据的
MongoDB是一个面向文档的数据库,区别于关系型数据库将数据存储在由一个个单独的行组成的表那样,稳定性的数据库将数据存储在由一个个单独的文档组成的集合里面。在MongoDB里面,一个文档是由一个大型的JSON字符串组成的,这个JSON字符串没有特殊的格式或者模式。
让我们假设你要对一个类似于下面这样一个关系集合进行建模,其实这个模型已经跟使用MongoDB的Pivotal项目的模型很相似了,也是我可以找到的来解释文档型数据库最好的例子了。
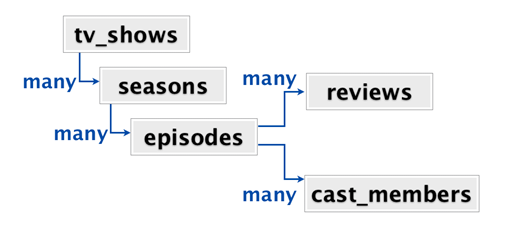
在根节点上,你有一个电视节目(TV show)的集合。每一个节目有很多季,每一季有很多集,每一季有很多评论跟很多角色。当用户访问这个视频站点的时候,他们会直接进入某个特定的电视节目页面。在这个页面上用户可以看到这个电视节目的所有季、所有集、所有角色、所有评论。所以从应用的角度来看,每当有用户访问这个电视节目所在的网页时,我们都希望将于这个节目关联的数据全部检索出来。
有很多对这些数据建模的方式。在一个典型的关系型数据库中,每一个类型的数据都放在一个表里面。所以你会有一个tv_shows表,一个seasons 表,并通过外键与tv_shows挂钩,一个episodes 表通过外键与seasons 表挂钩,一个reviews 表,一个cast_members表,这两个表均通过外键与episodes表挂钩。因此,如果想要获取一个电视节目的所有信息,那么你就需要有一个连接5个数据表的数据库操作。
我们也可以把这个数据建模为一个内嵌的哈希集合.每一个特定电视节目的信息都是一个大的嵌套的k/v数据结构。在‘电视节目’键内部,是一个季的数组,每一个‘季’也是一个哈希。在每一季内部,是一个角色的数组,每一个角色键也是一个哈希。这是MongoDB对数据建模的方式。每一个TV show都是一个文档,文档内部有我们需要的关于这个节目的所有信息。
下面是Babylon 5这个电视节目对应的文档的例子。

基本就是一个巨大的分型数据结构。

任何我们需要的关于一个TV show的信息都放在一个文档里面,所以即使是一个很大的完档,我们任然很容易就可以一次性将所有的信息检索出来。
因此从很多方面来讲,这个TV Show应用基本代表了文档型存储的一个理想的使用例子。
但是对于社交网络又是怎样的呢?
是的,当你回过头来看社交网络站点的时候,你会发现我们在这个网站页面中我们最关心的只有一个,那就是你的活动事件流。这个活动事件流会根据时间顺序从最新的开始,查询所有你关注的用户的状态发布。每一条发布状态都有嵌套的信息在里面,包括照片、点赞、评论等。
活动事件流的嵌入式结构跟刚刚我们看到的电视节目的结构非常相似.
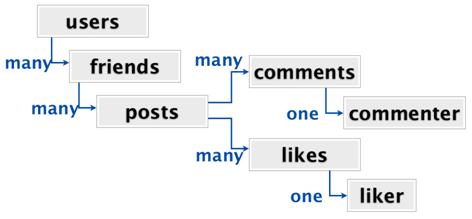
如上图所示,没有一个用户都有很多好友,每一个好友都会发布状态,每一条状态都有评论跟点赞,每一条评论都有评论者,每一个点赞都有点赞者.从关系图谱的角度上讲,它并没有比电视节目也的关系图来的复杂.就像在电视节目的应用,我们想要在用户登录完之后,就将这些数据一次性的拉取出来.但是在关系型数据库存储中,因为所有的数据都是规范化地存储,所以我们需要连接7个数据表才能拿到左右的数据。
一下子连接7个表.天啊,突然间感觉将每一个用户的活动事件流存储在一个大型的非规范化的嵌入式数据结构里相比一次连接7个表格(译者注:指向数据存储在关系型数据库中)更加有吸引力。
在2010年的时候,当Diaspora团队在做关于选择哪一个数据库的决定时, Etsy那篇关于文档型存储的文章影响非常广泛,即使他们已经公布过他们已经不再使用MongoDB作为数据存储了.同时,在那个时候, Facebook的Cassandra数据库在关于远离关系型数据库的业界讨论中也起到很大的作用。在那个时间点上,Diaspora选择MongoDB作为社交数据的底层存储,并不是一个不合理的选择,因为确实MongoDB确实可以给到他们想要的所有数据。
什么东西可能走向错误?
在Diaspora的社交网络数据跟MongoDB理想的应用场合-电视节目之间有一个很大的区别,然而一开始并没有人发现。
在电视节目中,在关系图中的每一个方框都是一个不同类型的数据。‘TV shows’、seasons’、‘episodes’、‘reviews’、‘cast members’都是彼此互不相同的数据类型的,甚至也不存在某一种类型是另一种类型的子类型。
但是在社交数据上,在关系图中的一些方框中内的数据是相同的数据类型。事实上,在下图中的绿色方框内的数据就是相同的数据类型,即都是Diaspora中的用户。

每一个用户都有好友,每一个还有实际上也基本是用户。或者,也有可能不是,因为这是在分布式的系统下。(这个话题是一个不同层面的更加复杂的话题,暂且不表)(译者注:这里作者可能是指分布式系统中,由于各个不同的服务器之间需要同步数据,所以有些服务器在另一个服务器上看来就是一个好友,具体可以看微信朋友圈中四个数据中心之间数据时怎样流通的例子,在这里)
这种具有相同类型数据的场合,是的想要将其非规范到地存储到一个文档中变得很难。因为在你文档中的不同地方,可能会引用到相同的点。在社交数据这个场景下,这个点就是用户。在你的活动时间流列表中,某一个点赞了一条发布状态的用户,可能跟在另外一条发布状态中进行评论的用户是同一个。
重复的数据
当然在MongoDB里面,我们可以有几种不同的方式来表达这个这个用户的数据模型。重复的数据是一个容易的方式。所有关于这个好友的信息,我们都可以拷贝一份并存放于第一条发布状态的点赞好友信息中,然后再有一份独立的拷贝存放在第二条发布状态的评论好友信息中。
下面就是上述非规范化数据流文档的大致样子:

在这种场景下,我们有很多用户信息的拷贝。上图所示是Joe的活动事件流,在最上部,是一个包含Joe名字和URL的用户信息拷贝。在他的活动事件流的下方,有一个Jane的发布状态,Joe点赞过Jane的发布,所以在Jane的发布状态下面,还有一个跟上面独立的Joe用户数据的拷贝。
你可以发现为什么这样的做法是如此迷人:所有的你想要的数据都位于你需要他们的地方了。你也可以发现为什么这样的做法有事如此危险:一旦想要更新一个用户的数据意味着你必须遍历所有的该用户会出现的活动事件流上,然后去修改这些处于不同地方的用户数据。这是非常容易出错的,而且经常会导致数据的不一致以及一些难以察觉的错误,特别是在处理删除动作的时候。
是不是没有希望了?
在MongoDB中你还有另外一种方法来解决用户数据存储的问题,如果你有关系型数据库的背景,你会这个方法感觉很熟悉。在活动事件流里面,你可以存储用户数据的引用而不是重复的具体的用户数据。
在上面所述的方法中,你可以给每一个用户分配一个ID而不是将具体的用户数据嵌在事件流数据中。这样,一旦所有用户都有其唯一的IDs,那么我们就可以将第一种方法中嵌入在每一个地方的用户数据替换成相应的用户ID了。如下图所示,绿色的部分就是用户ID。

这个方法可以解决我们重复数据的问题,每当用户数据需要变更,都只有用户数据文档需要重写。然而,我们却给自己引出了另一个问题出来。因为我们将一些数据移出活动事件流中,因此我们再也无法通过一个单独的文档构建出完整的活动事件流了。这将导致低效率跟更大的复杂度。现在要构建一个活动事件流,需要有两步:1、检索所有的事件流文档;2、检索所有的用户文档,然后将用户数据填入到活动时间流中。
MongoDB缺少SQL风格的连接操作,连接操作提供了一次的查询动作可以将事件流跟事件流引用的用户聚合起来。因为MongoDB没有连接的功能,所以你只能在你的上层应用代码中做这个聚合的操作了。
----未完待续,2019-12-02-------------