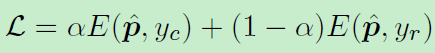一篇解决图像识别问题中“长尾分布”的论文,也是cvpr20的oral,想法简洁有效:解耦分类网络的特征学习层和分类层。论文地址:BBN 。
常见的物体类别在识别问题中占据主导地位,而罕见的类别则数据较少。长尾分布在某种程度上可以视作比正态分布更广泛存在的一种自然分布,现实中主要表现在少量个体做出大量贡献(少量类别的样本数占据大量样本比例)。类别极度不平衡时易导致模型学习非常容易被“头部”类别主导而产生过拟合,同时模型对于“尾部”数据的学习不够而导致预测不准。此外,深度学习模型基于batch的训练特性带来的模型遗忘问题在长尾数据分布情况下尤为突出。
在深度学习中,特征学习和分类器学习通常是被耦合在一起进行端到端学习,而在长尾分布数据的极度不平衡状态下,特征学习和分类器学习的效果均会受到不同程度的干扰。文中首次揭示了重采样(re-sampling)和重权重法(re-weighting)这类类别重平衡(class re-balancing)的方法其奏效的原因在于显著提升了深度网络的分类器学习模块能力。然而该类方法由于刻意改变样本数目(重采样法)或刻意扭曲数据分布(重权重法),在一定程度上损害深度网络学习到的特征。基于此。文中提出了一种双分支神经网络结构来同时兼顾特征学习和分类器学习。将深度学习模型这两个重要模块进行解耦,从而保证两个模块互不影响,共同收敛最优。该方案也是2019届iNaturalist旗舰赛事世界冠军的solution:代码在这。
分析:
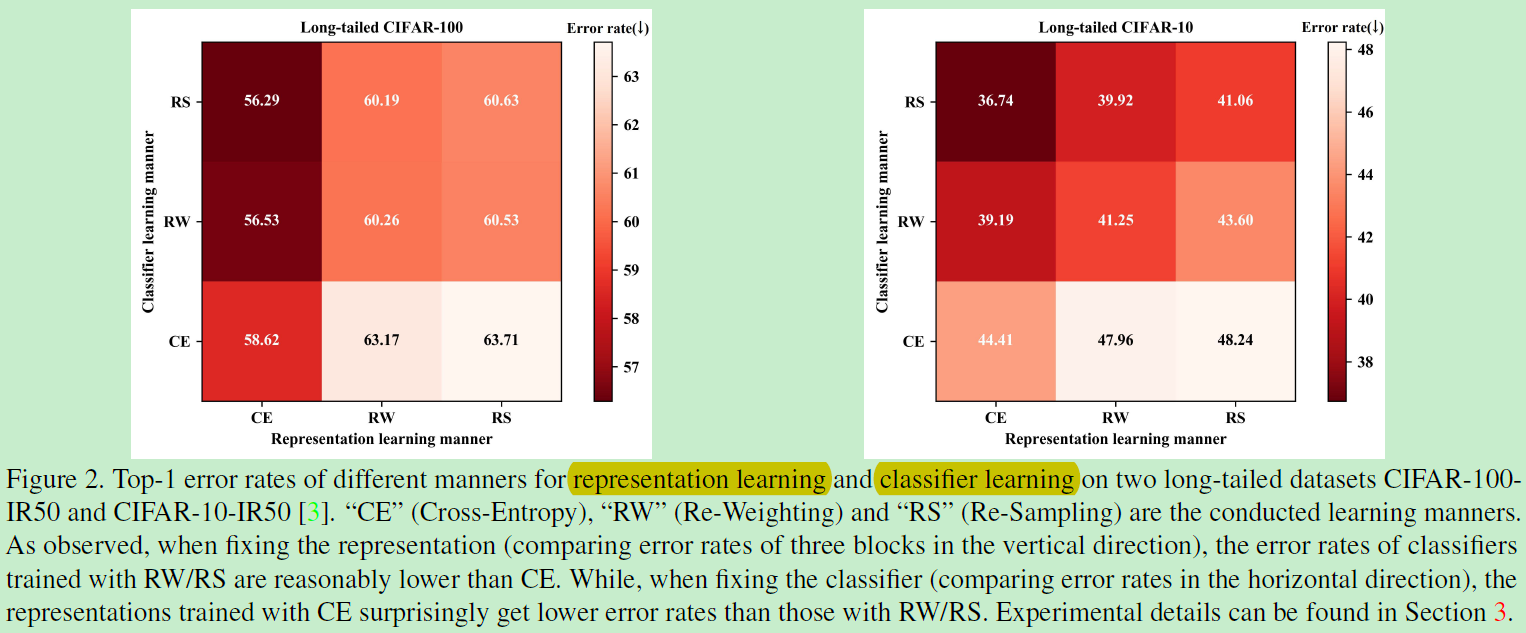
上图在两个数据集进行实验,发现当固定特征学习时,固定某一列,发现CE是最差的表现,而RS表现最好,说明该方法可以促进分类器学习。而当固定分类器时,即固定某一行,看到CE有最好的表现。所以证实了加权或者采样的这些方法是会损害特征学习的!那么最好的方案自然是利用RS进行分类器学习,CE进行特征学习。继而提出的双分支网络结构如下:
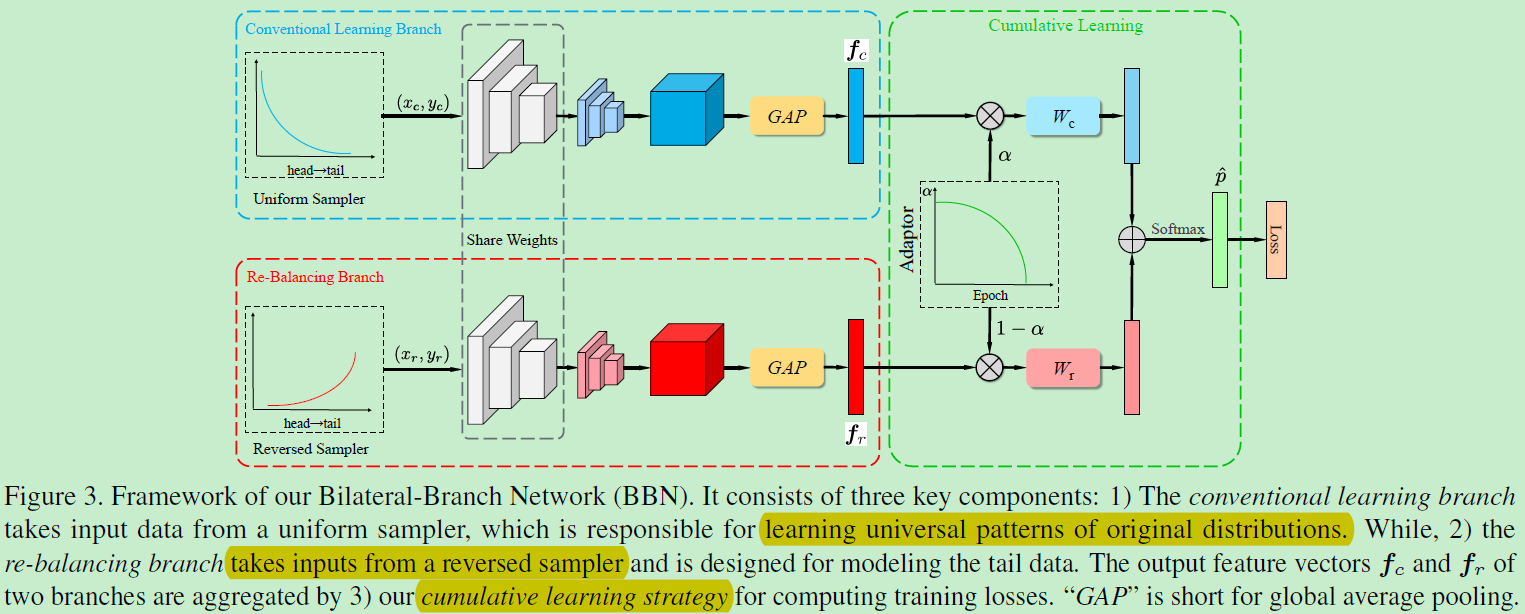
比较有趣的地方有以下几个点:下分支的倒置采样器和特征加权聚合两个地方。
上分支采样器保持均匀采样,是为了维持特征学习,保持原有数据分布。倒置采样器是根据样本出现频率逆着采样,即高频样本较小的采样权重。目的是为了减轻样本的不平衡,提升尾部类别的分类精确度。
在特征聚合处可以看到有两个特征被提取:fc和fr,相继与两个权重(分类器W)相乘后进行加权:(有点mixup的味道)

然后得到z,z就是得分,利用softmax进行归一化:
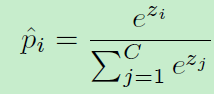
在计算损失的时候,也是加权计算:从下式看来损失是该预测结果以alpha概率属于类别yc和以概率1-alpha属于类别yr。