一篇19年语义合成图像的文章。认为直接利用正则层会洗掉图像中原有的语义信息。提出了一种spatially-adaptive的正则化。
条件图像合成方法区别在于输入数据的类型。例如以类别为条件的模型、以图像为输入的image-to-image等。非条件正则层包括Local Response Normalization、BN、IN、LN等。然而条件正则层不同的是依赖于外部数据,例如Conditional BN、Adaptive IN等。这俩最初被用于风格迁移,后来被应用于其他领域。条件正则用法为:首先将特征零均值单位方差化,然后利用一个可学习的affine转换进行去正则化。对于风格迁移任务,affine参数用来控制输出的整体风格。所以在整个空间空间坐标上是一致的。而本文提出的正则层应用一个空间变化的affine转换。
SPADE(Spatially Adaptive Denormalization)空间自适应去正则化层
类似于BN,也是在通道维进行正则化,并利用学到的scale和bias进行调制。

用公式表示就是:

其中均值和方差就是传统BN的操作方法。beta和gamma为调制参数,不一样的是这两个参数不是向量而是三维tensor。相比于BN,他们取决于输入的segmentation掩模,并且根据位置不同而变化。SPADE是一些已有正则层的泛化,例如:将掩模换成类标并将调制参数设为空间不变的,则退化成了Conditional BN,将掩模变成图像并将调制参数设为空间不变,并将N设为1,就变成了AdaIN。正因为本文设计的SPADE是调制参数可变的,所以更好。
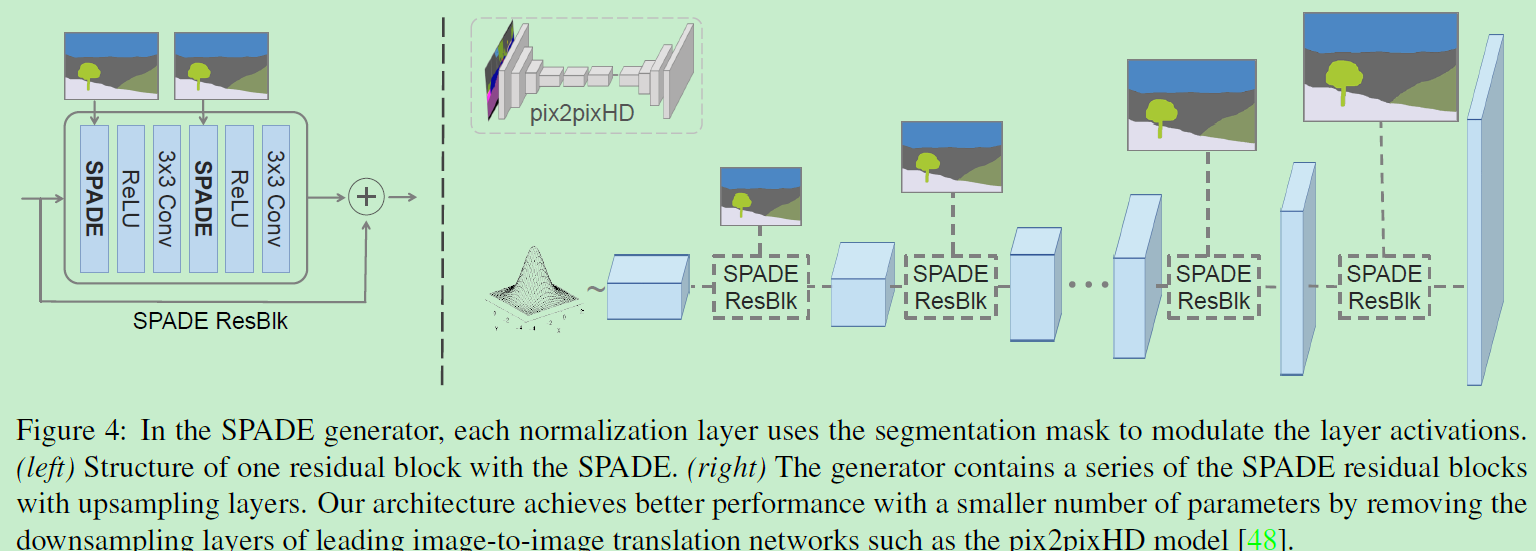
SPADE geneator
有了SPADE,无需在生成器首层输入语义图,因为学习到的调制参数已经编码了关于标签布局的足够信息。因此,弃掉了生成器的编码器部分。更轻量,目前许多工作也是这样做的。下图是生成器结构:生成器相应的判别器利用多尺度结构,和pix2pixHD的那个一样。除了将最小二乘损失换成了hinge loss。
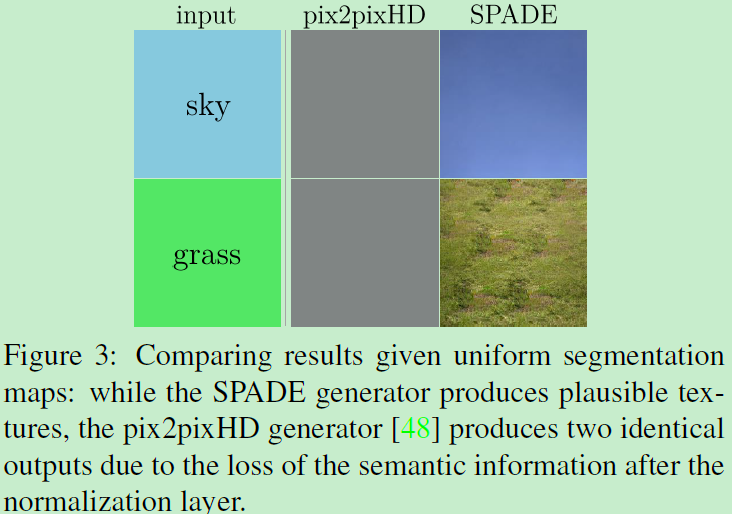
为什么SPADE是work的?
可以更好的保留语义信息相较于常见的正则层。 IN会洗掉这种语义信息。考虑:对语义mask先卷积后正则化。再考虑:对于只有一种label的语义图(例如只有天空),在这种情况下,卷积得到的结果利用IN会使得特征全变为0,不论是哪种标签。(单标签的话,均值就和每个像素值相等,所以正则化会变成零。)因此,语义信息彻底丢失了。下图表示了pix2pixHD因此导致的信息丢失,因为分割掩模通常由几个均匀的区域组成。而含有SPADE的生成器结果可以的。相比后者语义分割图在生成器输入时输入到了不含正则层的SPADE,仅仅前一层的特征被正则,所以SPADE generator可以很好的保留语义信息。
多模态合成
通过对生成器输入随机向量,可以实现多模态合成。即可以添加一个encoder来将图像处理成随机向量,然后输入到生成器中,编码器和生成器就构成了一个变分自编码器VAE。那么这个添加的encoder就成为捕捉风格的作用,生成器结合风格和语义掩模通过SPADE来重构原图。encoder在测试时可以作为风格控制器,对于训练的时候加上KL-Divergence作为损失。如下图:
