一、序列化
1、类的基本知识:
类实例化之前会执行__new__方法,用于控制一个类的生成实例的过程生成一个空对象,子类没有的就去找父类的__new__,
__new__ 执行完以后才能执行__init__构造方法
2、以ModelSerializer为例,无__new__方法,其父类Serlizer也没有,在往上找BaseSerlizer中的__new__方法
instance有值就是序列化
data有值就是反序列化
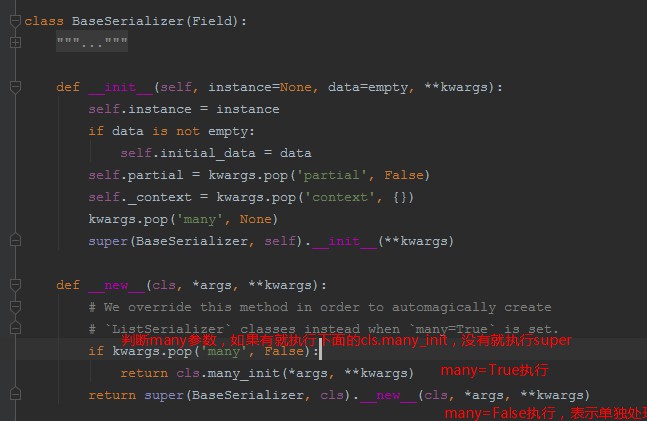
执行完__new__后执行__init__,根据many的值的不同执行的构造,
3、当many=True时执行cls.many_init方法采用LIstSerializer处理,此时我们对象对象的data属性获取结果(res.data)
序列化对象.data 的时候做了什么事

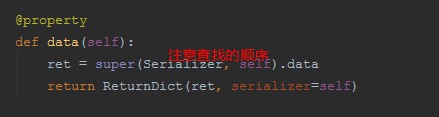
4、父类BaseSerlize 的属性方法data源码,走to_represenation方法,注意self指向的对象:

5、找到对象Serlizer 内的to_represenation
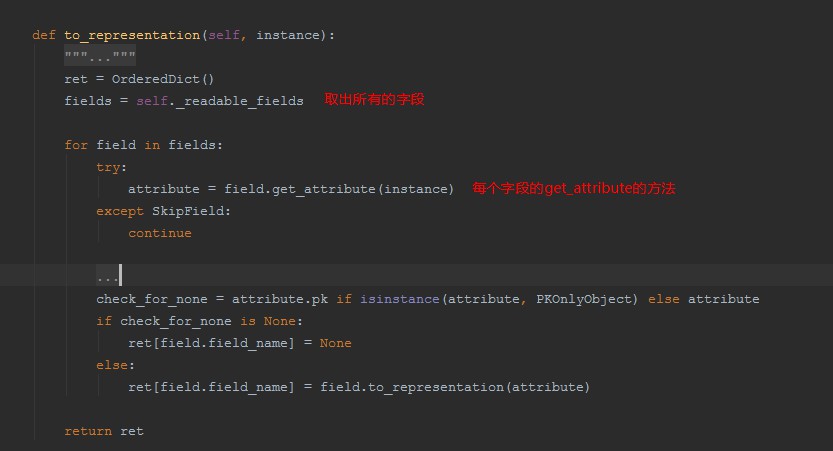
6、根据上图执行了Field里面的get_attribute方法
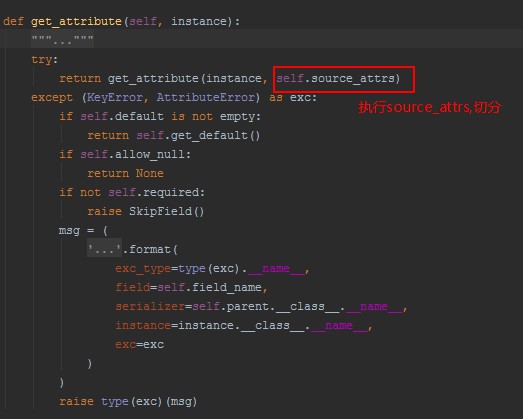
7.对source 指向的内容进行切分,如果是方法,直接执行,如果是字段名同前面的反射取值
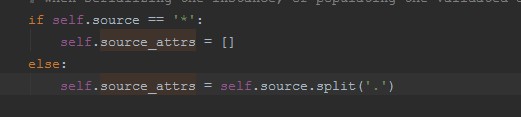
二、校验数据
全局校验:validate
局部校验:validate_字段名字 局部校验
源码分析
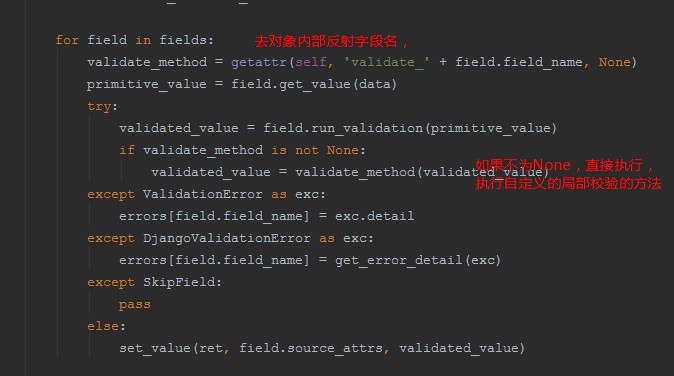
1、只有调用了is_valid才走校验
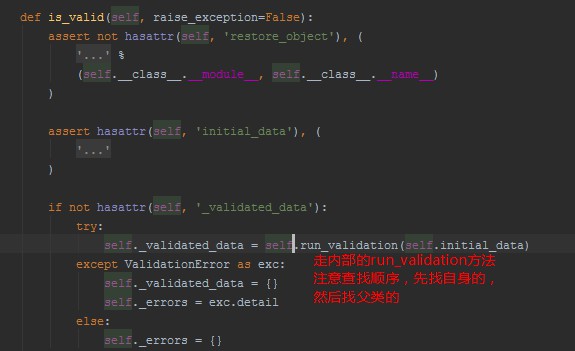
2、找到Serlizer里面的run_validation方法,调用validate _empty_values(data)
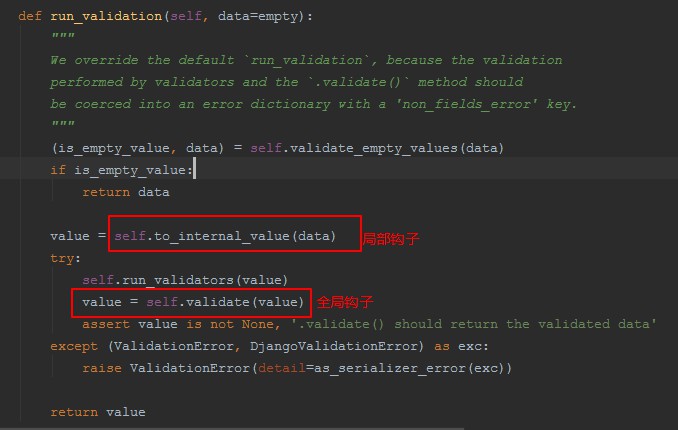
3、去对象内部反射字段名,如果不为None直接执行,执行了自定义的局部钩子,反之全局钩子