介绍
ElasticSearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索 引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的 开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索。稳 定,可靠,快速,安装使用方便
安装
- 步骤一:
- 下载地址: https://www.elastic.co/downloads/elasticsearch
- 官网:https://www.elastic.co/
- java jdk:电脑上面必须安装 java jdk 以及配置对应的环境变量,可能提示Java版本过低的情况,亲自动更新
- 步骤二: 运行 elasticsearch:
下载完成 elasticsearch 包后,把 elasticsearch 包放在一个固定目录,然后从命令窗口 cd 到 elasticsearch 包对应的目录,运行位于 bin 文件夹中的 elasticsearch.bat。这将会启动 ElasticSearch 在控制台的前台运行,这意味着我们可在控制台中看到运行信息或一些错误信 息。并可以使用 ctrl + c 停止或关闭它。
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
安装配置中文分词工具
默 认 情 况 ElasticSearch 只 适 用 于 英 文 分 词 , 如 果 要 做 中 文 分 词 的 话 我 们 要 安 装 elasticsearch-analysis-ik 插件。
找到 安装目录的 plugins 目录下 新建一个 ik 目录 把解压文件放到这个目录
注意版本要一致,
报错修改 pluginsikplugin-descriptor.properties 文件中 elasticsearch 的版本号(最后一行)
安装可视化工具
google 插件 ElasticSearch-Head,及其他可是工具
ElasticSearch 的一些概念
- 集群(cluster)
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
- 索引(index)
- ElasticSearch 将它的数据存储在一个或多个索引(index)中。用 SQL 领域的术 语来类比,索引就像数据库,可以向索引写入文档或者从索引中读取文档,并通过 ElasticSearch 内部使用 Lucene 将数据写入索引或从索引中检索数据
- Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
- 文档(document)
文档(document)是 ElasticSearch 中的主要实体。对所有使用 ElasticSearch 的案例来说,他们最终都可以归结为对文档的搜索。文档由字段构成,同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
- 映射(mapping)
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条 又会被过滤,这种行为叫做映射(mapping)。一般由用户自己定义规则。
- 类型(type)
每个文档都有与之对应的类型(type)定义。这允许用户在一个索引中存储多种文 档类型,并为不同文档提供类型提供不同的映射。
- 分片(shards)
代表索引分片,es 可以把一个完整的索引分成多个分片,这样的好处是可以把一个 大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。5.X 默认不能通过配置文件定义分片
- 副本(replicas)
代表索引副本,es 可以设置多个索引的副本,副本的作用一是提高系统的容错性, 当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高 es 的查询效率, es 会自动对搜索请求进行负载均衡
- 数据恢复(recovery)
代表数据恢复或叫数据重新分布,es 在有节点加入或退出时会根据机器的负载对索 引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。 GET /_cat/health?v #可以看到集群状态
- 数据源(River)
代表 es 的一个数据源,也是其它存储方式(如:数据库)同步数据到 es 的一个方 法。它是以插件方式存在的一个 es 服务,通过读取 river 中的数据并把它索引到 es 中,官方的 river 有 couchDB 的,RabbitMQ 的,Twitter 的,Wikipedia 的
- 网关(gateway)
代表 es 索引的持久化存储方式,es 默认是先把索引存放到内存中,当内存满了时 再持久化到硬盘。当这个 es 集群关闭再重新启动时就会从 gateway 中读取索引数 据。es 支持多种类型的 gateway,有本地文件系统(默认),分布式文件系统,Hadoop 的 HDFS 和 amazon 的 s3 云存储服务。
- 自动发现(discovery.zen)
代表 es 的自动发现节点机制,es 是一个基于 p2p 的系统,它先通过广播寻找存在 的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
5.X 关闭广播,需要自定义
- 通信(Transport)
代表 es 内部节点或集群与客户端的交互方式,默认内部是使用 tcp 协议进行交互, 同时它支持 http 协议(json 格式)、thrift、servlet、memcached、zeroMQ 等 的传输协议(通过插件方式集成)。
节点间通信端口默认:9300-9400
-
参考 https://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
-
参考 http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html
应用
-
elasticsearch 中文社区 https://elasticsearch.cn/question/7978
-
第一步 新建索引,相当于数据库
-
第二步 创建类型以及配置映射
如果报错(Types cannot be provided in put mapping requests, unless the include_type_name parameter is set to true)status==400时 要加入后面的参数 ?include_type_name=true
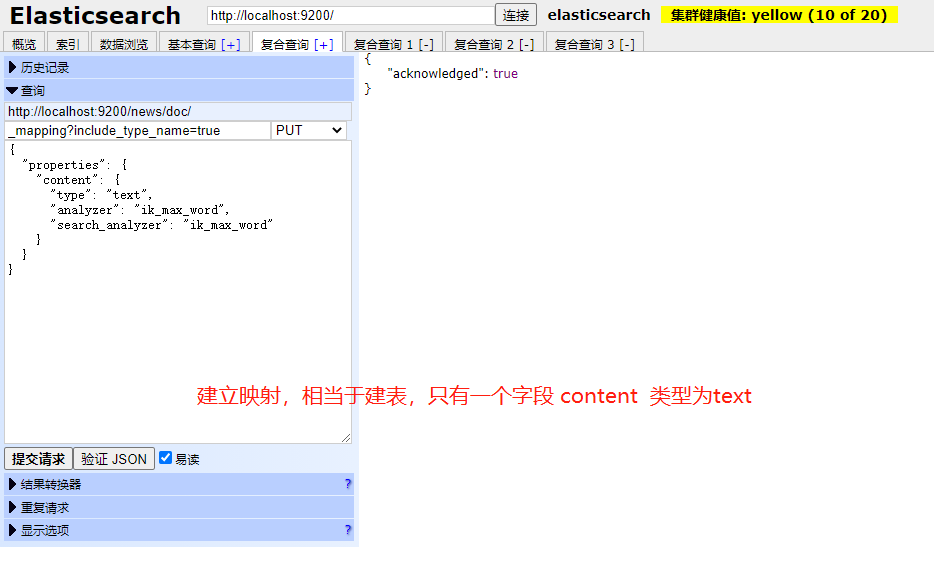
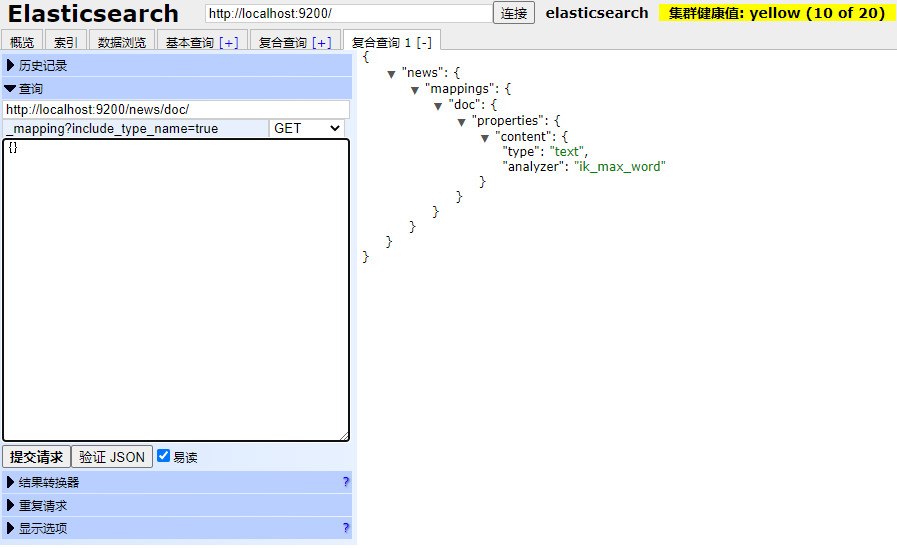
- 查看映射
后面也要加上 ?include_type_name=true
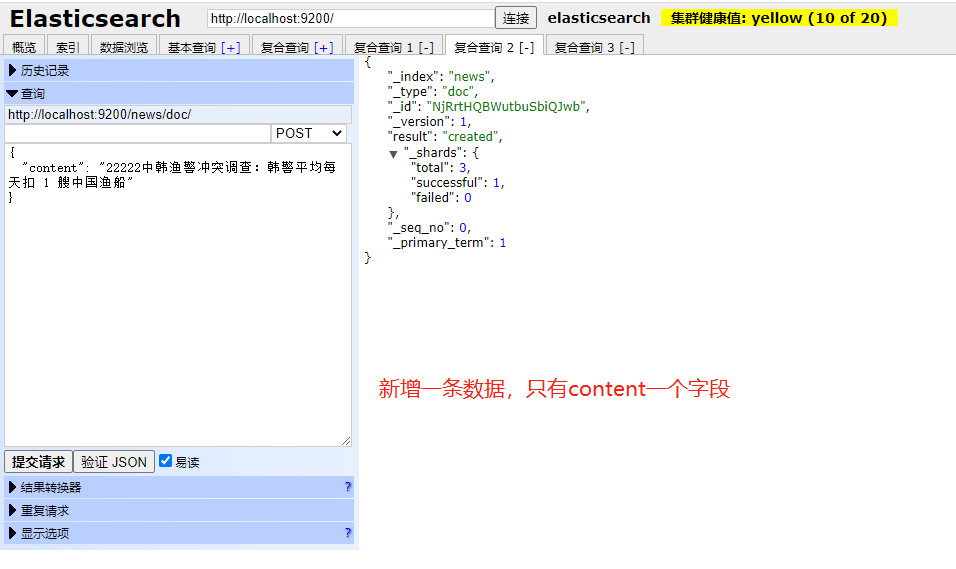
- 增加数据
用 POST 方式
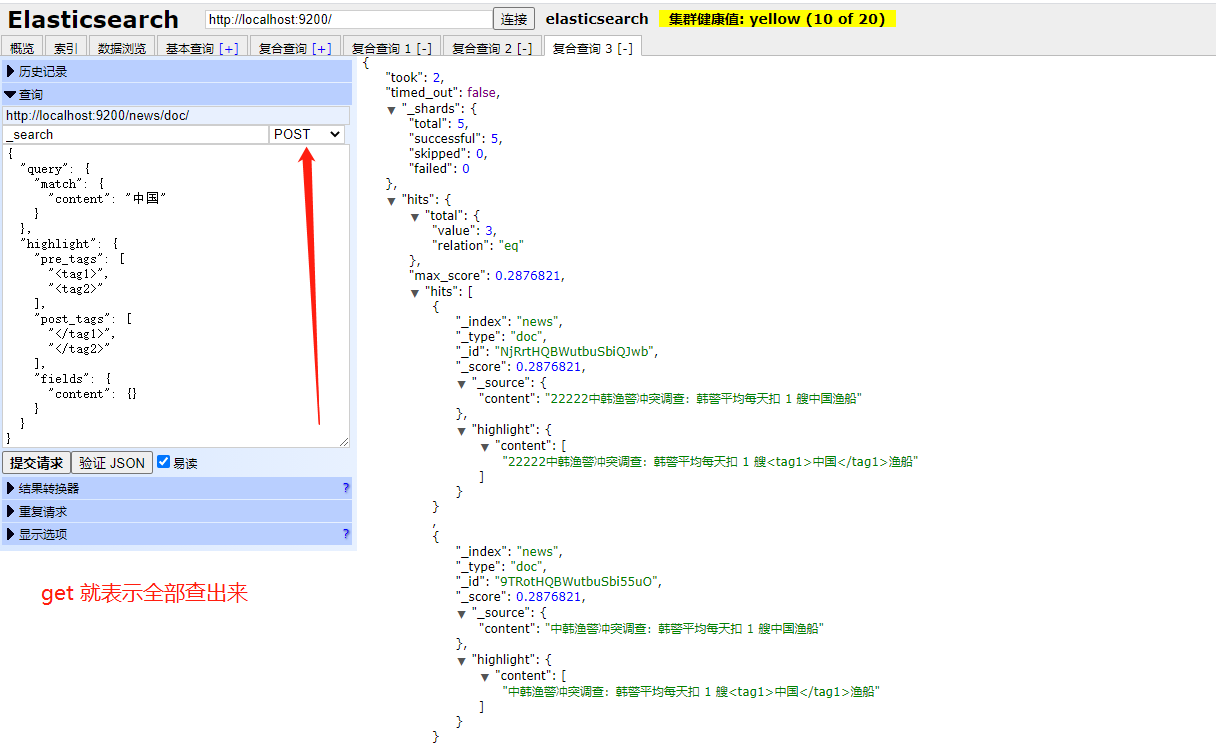
- 查询数据
post 按条件查询,get全部查出来;
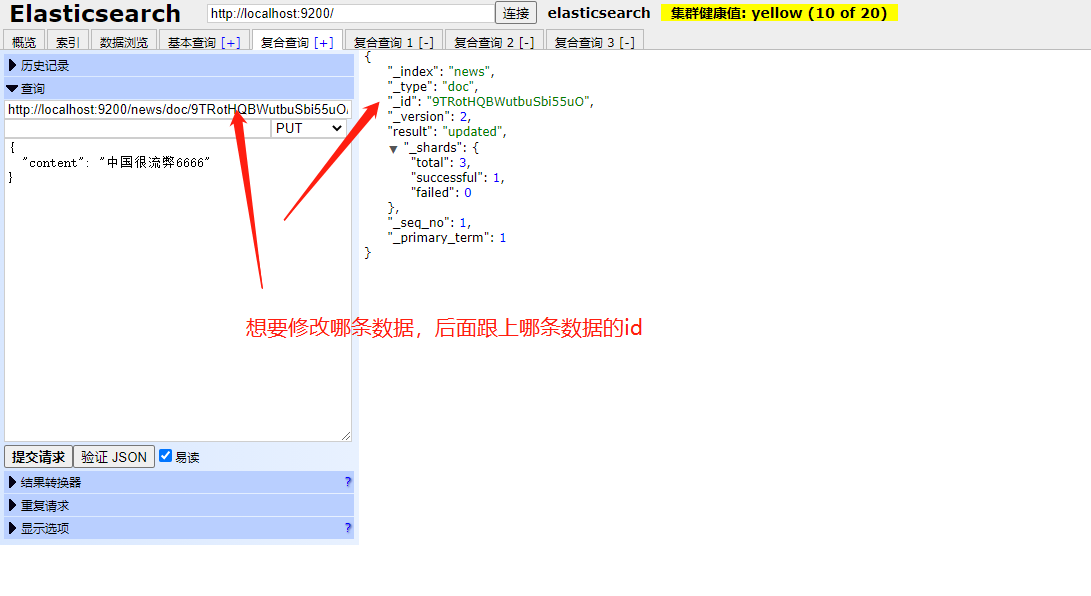
- 修改数据
用put localhost:9200/news/doc/路径后直接加上数据的ID
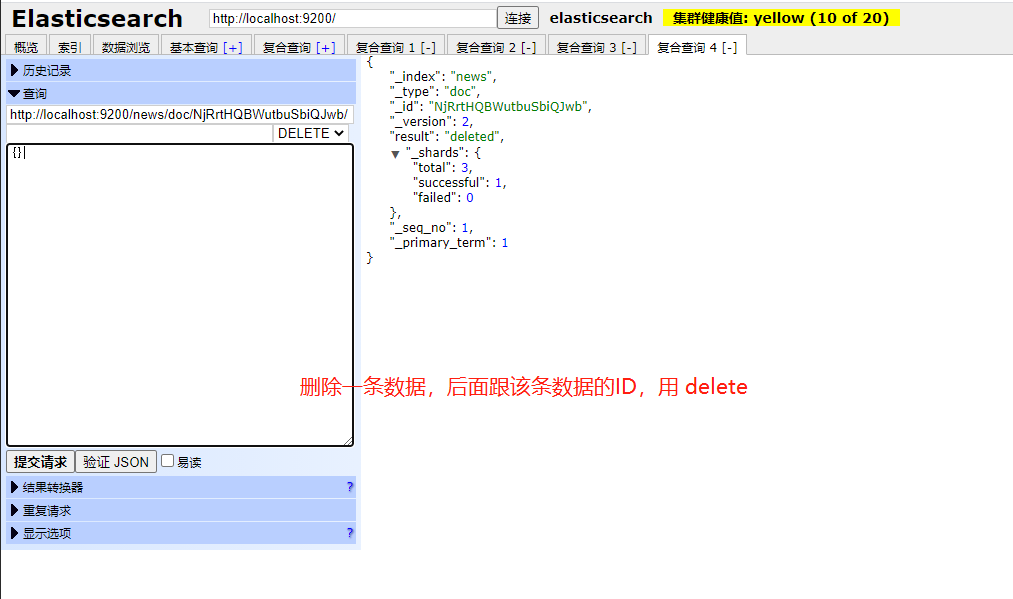
- 删除数据
用delete 路径后直接加上要删除数据的ID
在node js 中使用
-
官方api参考 https://www.elastic.co/guide/en/elasticsearch/client/javascript-api/current/api-reference.html
-
- 安装
- npm i egg-es --save
-
- 配置
//{app_root}/config/plugin.js
exports.elasticsearch = {
enable: true,
package: 'egg-es',
};
-
- 配置连接地址
//{app_root}/config/config.default.js
exports.elasticsearch = {
host: 'localhost:9200',
apiVersion: '6.6'
}
- 增加数据
const posts = await this.app.elasticsearch.bulk({
body: [
{ index: { _index: 'news', _type: 'doc',_id:"81kjC2kBLW9aMdEIiiCb"} },
{ content: '中国是个伟大的国家 很不错' }
]
});
- 修改数据
const posts = await this.app.elasticsearch.bulk({
body: [
{ update: { _index: 'news', _type: 'doc' ,_id: '81kjC2kBLW9aMdEIiiCb' } },
{ doc: { content: '中国是个强国' } }
]
});
- 删除数据
const posts = await this.app.elasticsearch.bulk({
body: [
{ delete: { _index: 'news',
_type: 'doc',
_id: "81kjC2kBLW9aMdEIiiCb" } }
]
});
- 查询数据 以及分页查询
const pageNum = 2;
const perPage = 3;
const userQuery = {'content':'中国'};
const posts = await this.app.elasticsearch.search({
index: 'news',
type: 'doc',
from: (pageNum - 1) * perPage,
size: perPage,
body: { query: { match: userQuery } }
});
- 统计数据
const userQuery = {'content':'中国'};
let count = await this.app.elasticsearch.count({
index: 'news',
type: 'doc',
body: { query: { match: userQuery } }
});