1 redis中的事务的基础概念以及使用方法
1-1 redis事务的概述
定义:redis中事务与其他数据库基本一致,是多条redis指令的组合,当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰 。
redis中事务的相关命令
multi // 开启事务
多条redis指令
exec // 执行事务
discard // 取消事务,在执行事务前取消事务
实例
127.0.0.1:6378> multi
OK
127.0.0.1:6378> set name 1
QUEUED
127.0.0.1:6378> set age ss
QUEUED
127.0.0.1:6378> get name
QUEUED
127.0.0.1:6378> get age
QUEUED
127.0.0.1:6378> exec
1) OK
2) OK
3) "1"
4) "ss"
1-2 事务的工作流程

- 每开启一个事务,都会创建一个事务队列用于存储待执行的指令。
1-3 事务的使用注意点
定义事务的过程中,命令格式输入错误怎么办(定义过程中的错误)
- 根据事务的原子性,该事务会被取消。
127.0.0.1:6378> multi
OK
127.0.0.1:6378> set age 1
QUEUED
127.0.0.1:6378> se
(error) ERR unknown command 'se'
127.0.0.1:6378> exec
(error) EXECABORT Transaction discarded because of previous errors.
定义事务的过程中,命令运行出现错误怎么办(执行过程中的错误)
- 能够正确运行的命令会执行,运行错误的命令不会被执行
- 运行错误:命令格式正确,但是无法正确的执行。例如对list进行incr操作(执行过程中发生的错误)
127.0.0.1:6378> multi
OK
127.0.0.1:6378> set name cat
QUEUED
127.0.0.1:6378> get name
QUEUED
127.0.0.1:6378> lpush name a b c
QUEUED
127.0.0.1:6378> get name
QUEUED
127.0.0.1:6378> exec
1) OK
2) "cat"
3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
4) "cat"
- 上面事务的定义过程中key发生了重复,在执行时出现了错误,系统在处理的时候,对于执行
错误的命令进行忽略。
上面机制带来了以下问题?
注意:已经执行完毕的命令对应的数据不会自动回滚,需要程序员自己在代码中实现回滚 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
在MySQL数据过程中,如果事务在执行过程中出现错误,系统会自动回滚。
如何实现手动进行事务回滚?
记录操作过程中被影响的数据之前的状态
单数据: string
多数据: hash、 list、 set、 zset
设置指令恢复所有的被修改的项
单数据:直接set(注意周边属性,例如时效)
多数据:修改对应值或整体克隆复制
实际开发中,redis事务用的并不是太多。
2 redis中的锁(基于特定条件的事务执行)
2-1 redis的监视锁(watch)(乐观锁)
情景:
业务场景 :天猫双11热卖过程中,对已经售罄的货物追加补货, 4个业务员都有权限进行补货。补货的操作可能是一系列的操作(1个事务),如何保障不会重复操作?
业务分析:多个客户端有可能同时操作同一组数据,在操作之前锁定要操作的数据,一旦发生变化,终止当前操作
redis的锁的解决策略:客户端通过执行watch命令对 key 添加乐观锁
watch命令只是进行加锁但不会阻塞其他客户端对于数据的操作,当监视的key对应的数据被其他客户端抢先修改的时候,会通知执行watch命令的客户端
redis监视锁的相关命令:
watch key1 [key2……] // 对key添加监视
unwatch // 取消对key的监视
- watch命令必须在事务执行前执行监控key,一旦检测到key对应的value发生改变,watch后面定义的事务都不会被执行
总结:使用watch命令添加监控锁,可以确保多个客户端执行同样的修改,但只有一个能够修改有效。
2-2 应用redis的锁解决超卖问题(分布式锁)?
超卖问题定义:对已经售罄的货物追加补货,且补货完成。客户购买热情高涨, 3秒内将所有商品购
买完毕。本次补货已经将库存全部清空,如何避免最后一件商品不被多人同时购买?
问题分析:
1)这种场景下采用监控锁无法解决问题,我们需要监控的数据的具体变化,而监控锁只能监控key是否改变。
2)redis是单线程的,但是多个客户端对同一数据同时进行操作时,如何避免不被同时修改?
解决策略:使用setnx设置公共锁,每个客户端对数据进行操作前必须先获取这个公共锁,才能继续执行数据的修改,数据修改完成后释放锁。
setnx lock-key value // 设置公共锁,lock-key中lock是前缀,key是数据库中已有的key
特点:利用setnx命令的返回值特征,有值则返回设置失败,无值则返回设置成功
- 对于返回设置成功的,拥有控制权,进行下一步的具体业务操作
- 对于返回设置失败的,不具有控制权,排队或等待
实例:
127.0.0.1:6378> flushdb
OK
127.0.0.1:6378> set num 10
OK
// 加锁成功返回非0值,如果其他客户端对相同的lock-key执行了setnx并且没有删除,那么这里返回的就是
// 0表示加锁失败,此时需要等待并重新尝试,直到获得锁,才能往下操作
127.0.0.1:6378> setnx lock-num 1
(integer) 1
127.0.0.1:6378> incrby num -1
(integer) 9
127.0.0.1:6378> del lock-num
(integer) 1
如何使用setnx实现分布式锁?
这里锁的实现要求多个客户端遵循一套行为规范(通过共享的公共变量实现锁):
获取key关联的锁 => 获取成功进行操作 => 释放key关联的锁
上面的步骤对应如下:
step1: setnx lock-key 1 (返回非0表示加锁成功,继续下一步,否则等待并重试)
step2: 对key进行操作
step3: del lock-key
// 删除lock-key即释放锁,这样其他客户端setnx lock-key 1就会成功
总结:可以看到每个客户端必须自己实现加锁/解锁的流程(setnx/del)
2-3 分布式锁没有释放的问题、
redis何时会出现锁没有释放 ?
某个用户操作时对应客户端宕机,且此时已经获取到锁(setnx)并且没有释放锁(del)
问题分析:由于锁操作由用户控制加锁解锁,必定会存在加锁后未解锁的风险需要解锁操作不能仅依赖用户控制,系统级别要给出对应的保底处理方案
解决策略:使用 expire 为锁key添加时间限定,到时不释放,放弃锁
expire lock-key second
pexpire lock-key milliseconds
由于操作通常都是微秒或毫秒级,因此该锁定时间不宜设置过大。具体时间需要业务测试后确认。
- 例如:持有锁的操作最长执行时间127ms,最短执行时间7ms。
经验原则:
1)测试百万次最长执行时间对应命令的最大耗时,测试百万次网络延迟平均耗时
2)锁时间设定推荐:最大耗时*120%+平均网络延迟*110%
3)如果业务最大耗时<<网络平均延迟,通常为2个数量级,取其中单个耗时较长即可
实例:加锁并设置好过期时间提供锁的释放保底
127.0.0.1:6378> flushdb
OK
127.0.0.1:6378> set name 123
OK
127.0.0.1:6378> setnx lock-name 1 // 加锁后还需要设置代表锁的key的过期时间
(integer) 1
127.0.0.1:6378> expire lock-name 20
(integer) 1
127.0.0.1:6378> get name
"123"
127.0.0.1:6378> del lock-name
(integer) 0
3 redis中过期数据的删除策略
3-1 过期数据概述
场景:很多数据都是临时缓存一下,可能很久都不会再用到,这些数据的存在是对资源的浪费,需要让redis定期清理这些数据,腾出资源给其他数据。
定义:哪些不再被需要的数据就是过期数据
问题:key过期的删除时机?

过期数据删除策略的目标:在内存占用(过期数据的数量)与CPU占用(执行删除操作)之间寻找一种平衡,顾此失彼都会造成整体redis性能的下降,甚至引发服务器宕机
- 我们希望过期数据的量控制在合理的程度不影响其他数据的缓存
- 同时我们也希望过期数据的删除的操作不会占用太多时间,从而影响数据库的整体工作状态
| 删除策略 | 删除操作对CPU占用 | 过期数据对内存的占用 | 备注 |
|---|---|---|---|
| 定时删除 | 不分时段占用CPU资源,频度高 | 节约内存,无占用 | 拿CPU换空间 |
| 惰性删除 | 延时执行, CPU利用率高 | 内存占用严重 | 拿空间换CPU |
| 定期删除 | 每秒花费固定的CPU资源维护内存 | 内存定期随机清理 | 随机抽查,重点抽查 |
3-2 删除策略1:定时删除
基本思想:在设置key的过期时间的同时,CPU为该key创建一个定时器任务,让定时器在key的过期时间来临时,对key进行删除
优点:节约内存,到时就删除,快速释放掉不必要的内存占用
缺点:CPU压力很大(定时器任务占用CPU资源),无论CPU此时负载量多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
总结
3-3 删除策略2:惰性删除
基本思想:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
优点:节约CPU性能,发现必须删除的时候才删除
缺点:内存压力很大,可能会出现长期占用内存的过期数据(部分数据如果在过期后永远不被访问那么会一直存在)
总结:注重减少删除操作对CPU的占用
惰性删除的原理
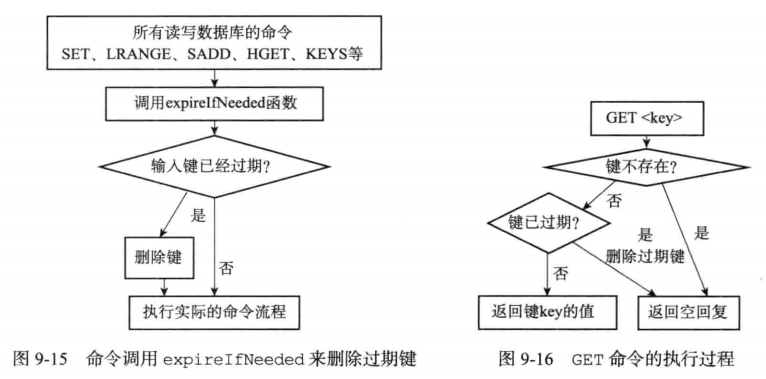
惰性删除原理总结:当数据库执行redis命令前,通过调用expirlfNeeded函数对key进行过期检查。
3-4 删除策略3:定期删除
127.0.0.1:6378> info server
# Server
redis_version:4.0.0
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:d748290e16ddf3d8
redis_mode:standalone
os:Linux 5.4.0-70-generic x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:7.5.0
process_id:17510
run_id:ace405d287322bccdf4804e64f8357385b148e0e
tcp_port:6378
uptime_in_seconds:25335
uptime_in_days:0
hz:10 // 定义了服务器每秒执行轮询操作的次数
lru_clock:9937117
executable:/home/god/redis-4.0.0/redis-server
config_file:/home/god/redis-4.0.0/conf/redis-6378.conf
预备知识
redis中key的过期时间存储在哪里?

redis的数据库结构中会定义一个过期字典(expires),用于存储每个key的过期时间戳,上图中是一个带有过期字典的redis的database。
定期清除的基本思想:每隔一段时间执删除过期keys操作(执行频率通过配置文件的设置)
特点:可以看成定期删除与惰性删除的一种折衷,综合考虑了内存占用与CPU占用,但需要配置执行配率与删除操作的执行时长
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
- 周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
总结:周期性抽查存储空间(随机抽查,重点抽查)
定义清除的具体原理?
具体流程(数据《redis的设计与实现》提供更加详细的内容)
step1:Redis启动服务器初始化时,读取配置server.hz的值,默认为10,通过info server查看hz的值。如果hz等于10,代表服务器每秒执行10次,
serverCron()轮询方法,该方法内部调用databasesCron()对服务器每一个redis database进行轮询,databasesCron()方法会进一步调用activeExpireCycle()函数,
step2:activeExpireCycle()会对过期字典中的key进行随机检查,并删除过期的key,检查的key的数量通过配置文件限制。
注意点:由于每次执行定义删除的时间有限制,activeExpireCycle()函数会维护一个变量用于记录上一次检查到第几个数据库的过期字典,下一次进入时从记录点开始删除,这样确保所有的数据库的过期字典都会得到随机抽查删除。
4 redis内存不足情况下数据的删除(逐出(淘汰)算法)
情景:redis中没有可删除的过期数据,并且当前有新数据进入造成redis的可用内存空间不足?
解决策略:redis临时删除一些数据为当前指令清理存储空间。清理数据的策略称为逐出算法。
- Redis使用内存存储数据,在执行每一个命令前,会调用freeMemoryIfNeeded()检测内存是否充足,不充足则采用逐出算法
- 逐出数据的过程不是100%能够清理出足够的可使用的内存空间,如果不成功则反复执行。当对所有数据尝试完毕后,如果不能达到内存清理的要求,将出现错误信息
(error) OOM command not allowed when used memory >'maxmemory
注意:redis的逐出算法会失败
影响数据逐出的参数
/*Redis最大可使用内存:占用物理内存的比例,默认值为0,表示不限制。生产环境中根据需求设定,通常设置在50%以上。*/
maxmemory
/*每次选取待删除数据的个数:选取数据时并不会全库扫描,导致严重的性能消耗,降低读写性能。因此采用随机获取数据的方式作为待检测删除数据*/
maxmemory-samples
/*删除策略:达到最大内存后的,对被挑选出来的数据进行删除的策略*/
maxmemory-policy
数据逐出8种策略,可以分为三大类型(策略的选择要依据具体的场景):
- 从可能会过期的key挑选逐出数据
- 从全数据层面利用淘汰算法逐出数据(类似页面置换算法)
- 放弃数据逐出
检测易失数据(可能会过期的数据集server.db[i].expires )
① volatile-lru:挑选最近最少使用的数据淘汰
② volatile-lfu:挑选最近使用次数最少的数据淘汰
③ volatile-ttl:挑选将要过期的数据淘汰
④ volatile-random:任意选择数据淘汰
检测全库数据(所有数据集server.db[i].dict )
⑤ allkeys-lru:挑选最近最少使用的数据淘汰
⑥ allkeys-lfu:挑选最近使用次数最少的数据淘汰
⑦ allkeys-random:任意选择数据淘汰
放弃数据驱逐
⑧ no-enviction(驱逐):禁止驱逐数据( redis4.0中默认策略),会引发错误OOM( Out Of Memory)
数据逐出策略配置依据
使用INFO命令输出监控信息,依据缓存 hit 和 miss 的次数,根据业务需求调优Redis配置
====================================================================
keyspace_hits:5 // 逐出算法的参照依据1:key的命中次数
keyspace_misses:0 // 逐出算法的参照依据2:key的丢失次数
127.0.0.1:6378> info
# Server
redis_version:4.0.0
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:d748290e16ddf3d8
redis_mode:standalone
os:Linux 5.4.0-70-generic x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:7.5.0
process_id:17510
run_id:ace405d287322bccdf4804e64f8357385b148e0e
tcp_port:6378
uptime_in_seconds:35000
uptime_in_days:0
hz:10
lru_clock:9946782
executable:/home/god/redis-4.0.0/redis-server
config_file:/home/god/redis-4.0.0/conf/redis-6378.conf
# Clients
connected_clients:1
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
# Memory
used_memory:827576
used_memory_human:808.18K
used_memory_rss:4071424
used_memory_rss_human:3.88M
used_memory_peak:828968
used_memory_peak_human:809.54K
used_memory_peak_perc:99.83%
used_memory_overhead:815246
used_memory_startup:765544
used_memory_dataset:12330
used_memory_dataset_perc:19.88%
total_system_memory:67383435264
total_system_memory_human:62.76G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:4.92
mem_allocator:jemalloc-4.0.3
active_defrag_running:0
lazyfree_pending_objects:0
# Persistence
loading:0
rdb_changes_since_last_save:32
rdb_bgsave_in_progress:0
rdb_last_save_time:1620524518
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:-1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:0
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:0
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:217088
aof_current_size:871
aof_base_size:121
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:0
# Stats
total_connections_received:10
total_commands_processed:57
instantaneous_ops_per_sec:0
total_net_input_bytes:1713
total_net_output_bytes:105956
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:1
evicted_keys:0
keyspace_hits:5 // 逐出算法的参照依据1:key的命中次数
keyspace_misses:0 // 逐出算法的参照依据2:key的丢失次数
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:287
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
# Replication
role:master
connected_slaves:0
master_replid:cf0a4f48c944dfcf437de6d55c8edee2c02c3349
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
# CPU
used_cpu_sys:20.40
used_cpu_user:8.97
used_cpu_sys_children:0.00
used_cpu_user_children:0.00
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
4 redis其他的一些比较重要的配置选项
daemonize yes|no //设置服务器以守护进程的方式运行
bind 127.0.0.1 // 绑定主机地址
port 6379 // 设置服务器端口号
databases 16 // 设置数据库数量
loglevel debug|verbose|notice|warning
// 设置服务器以指定日志记录级别,日志级别开发期设置为verbose即可,生产环境中配置为notice,简化日志输出量,降低写日志IO的频度
logfile 端口号.log // 日志记录文件名
maxclients 0 // 设置同一时间最大客户端连接数,默认无限制。当客户端连接到达上限, Redis会关闭新的连接
timeout 300 // 客户端闲置等待最大时长,达到最大值后关闭连接。如需关闭该功能,设置为 0
include /path/server-端口号.conf // 导入并加载指定配置文件信息,用于快速创建redis公共配置较多的redis实例配置文件,便于维护