昨天看到q群里群主博客获得 hao123 里的美女图的文章 于是自己复制代码试了下,发现没有成功(群主的是用file_get_contents 直接打开)。
于是我在他的基础上,修改一番采集成功。
预览链接 http://pic.hao123.com/meinv_meinv?style=xl
用chrome 开发者工具 分析图片来源
网页是瀑布流形式的 下拉到底部执行 网页ajax 加载图片 发现 图片 和文字 来自 一个 json
http://pic.hao123.com/screen/meinv_meinv/2?v=1362645599936&act=type
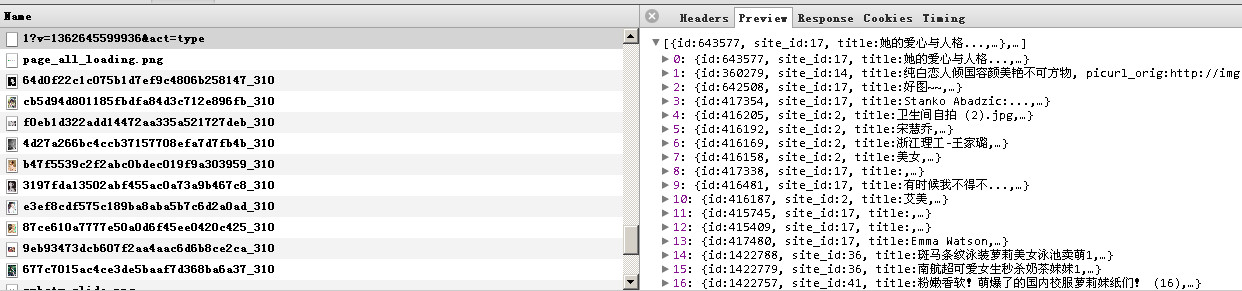

参数分析 :
meinv_meinv 是分类 美女下的美女标签
2 是 页数
v=1362645599936 是 时间戳 加2位随机数 (个人认为)
act=type 不清楚 照着写
遇到的问题:
1、file_get_contents 打开 http://pic.hao123.com/screen/meinv_meinv/2?v=1362645599936&act=type 时直接打开返回一个空序列
需要 带上 header 并且必须写明 "Referer:http://pic.hao123.com/meinv/?style=xl"
2 、获得的图片链接 有部分图片没有后缀(没有解决 ,我的做法是没有后缀的图片 直接给加上 .jpg 貌似还不错。)
下面是代码:
/**
* Created by JetBrains PhpStorm.
* User: keygle
* Date: 13-3-7
* Time: 上午9:30
* To change this template use File | Settings | File Templates.
*/
/**
* 返回打开url后得到的内容
* @param $url 需要打开的url
* @return string
*/
function getData($url)
{
$opts = array(
'http' => array(
'timeout' => 10,
'method' => 'GET',
'header' => "User-Agent: Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)\r\n" . //冒充百度蜘蛛
"Host: pic.hao123.com\r\n" .
"Accept-Language: zh-CN,zh;q=0.8\r\n" .
"Accept-Encoding: gzip,deflate,sdch\r\n" .
"Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3\r\n" .
"Content-Type:application/x-www-form-urlencoded" .
"Accept: application/json, text/javascript, */*; q=0.01\r\n" .
"Connection: keep-alive\r\n" .
"Referer:http://pic.hao123.com/meinv/?style=xl\r\n" . //缺少将无法获得json数据
"X-Requested-With:XMLHttpRequest\r\n\r\n"
)
);
$contents = stream_context_create($opts);
return $jsonData = file_get_contents($url, false, $contents);
}
$i = 1;
while ($i < 3) {
$times = time() . mt_rand(10, 99);
$url = "http://pic.hao123.com/screen/meinv_meinv/" . $i . "?v=" . $times . "&act=type";
$dir = str_replace('\\', '/', dirname(__FILE__)) . '/hao123/';
if (!file_exists($dir)) {
mkdir($dir);
chmod($dir, 0777);
}
$jsonData = getData($url);
$imageData = json_decode($jsonData, true);
foreach ($imageData as $val) {
$images = pathinfo($val['picurl_orig']);
$imageName = $images['basename'];
if (!$images['extension']) {
$imageName = $imageName . '.jpg'; //没有后缀 给加上 .jpg 后缀
}
$image = file_get_contents($val['picurl_orig']);
file_put_contents($dir . $imageName, $image);
}
$i++;
}