pandas读取文本文件数据的常用方法:
| 方法 | 描述 | 返回数据 |
|---|---|---|
| read_csv | 读取csv文件 | DataFrame或TextParser |
| read_fwf | 读取表格或固定宽度格式的文本行到数据框 | DataFrame或TextParser |
| read_table | 读取通用分隔符分割的数据文件到数据框 | DataFrame或TextParser |
1.read_csv
通过read_csv方法读取csv格式的数据文件
read_csv(filepath_or_buffer, sep='', delimiter=None, header='infer', names=None, index_col=None, usecols=None, **kwds)
参数:
-
filepath_or_buffer:字符串型,读取的文件对象,必填。 -
sep:字符串型,分隔符,选填,默认","。 -
delimiter:字符串型。定界符(备选分隔符),指定该参数,sep失效。 -
delim_whitespace:布尔型,是否指定空格或制表符作为分隔符,等效于sep=“s+”,指定该参数,delimiter失效。详解
s+:s匹配任何空白符,等价于[f v]-
f:匹配换页符
-
:匹配换行符
-
:匹配回车符
-
:匹配制表符
-
v:匹配垂直制表符
-
-
header:指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0;如果指定了列名header=None。 -
names:类数组,列名。默认为空。 -
dtype:每列数据类型。如:{'a': np.flat64, 'b': np.int32}。 -
skipinitialspace:忽略分隔符后的空白(默认False,即不忽略)。 -
skiprows:类字典或整数,要跳过的行或行数,默认为空。 -
nrows:整数型,要读取的前记录总数,选填,默认为空,常用来在大型数据集下做初步探索之用。 -
thousands:字符串型,千位符符号,,默认为空。 -
decimal:字符串型,小数点符号,默认为(.)。 -
index_col:行索引的列表号或列名,如果给定一个序列则有多个行索引。 -
squeeze:布尔型,当为True,如果数据仅有一列,返回Series。默认False,即只有一列也返回DataFrame。
2.read_fwf
通过read_fwf方法读取表格或固定宽度的文本行到数据框。
read_fwf(filepath_or_buffer, colspecs='infer', widths=None, **kwds)
参数:
跟read_csv中的大多相同。下面仅介绍read_fwf特有的参数。
widths:由整数组成的列表,选填,如果间隔是连续的,使用字段宽度列表而不是”colspecs“。
示例:数据内容如下。
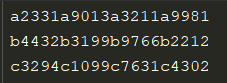
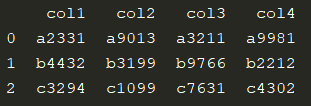
import pandas as pd
fwf_data = pd.read_fwf('fwf_data', widths=[5, 5, 5, 5], names=['col1', 'col2', 'col3', 'col4'])
print(fwf_data)
3.read_table
通过read_table方法读取通用分隔符分割的数据文件到数据框。
read_table(filepath_or_buffer, sep=' ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, **kwds)
参数:
与read_csv完全相同。其实read_csv是read_table中分隔符为逗号的一个特例。
示例数据内容如下:
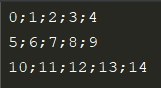
import pandas as pd
table_data = pd.read_table('table_data.txt', sep=';', names=['col1', 'col2', 'col3', 'col4', 'col5'])
print(table_data)

数据分割常分为两种:一种基于固定宽度,一种基于分割符号。即read_fwf和read_talbe。
4.Pandas其他数据读取方法
| 方法 | 描述 | 返回数据 |
|---|---|---|
| read_clipboard | 读取剪切板数据,将对象传递给read_table方法 | DataFrame或TextParser |
| read_excel | 读取Excel数据 | DataFrame或DataFrame构成的字典 |
| read_gbq | 从Google Bigquery中读取数据 | DataFrame |
| read_hdf | 读取文件中的pandas对象 | 所选择的数据对象 |
| read_html | 读取HTML中的表格 | 由DataFrame构成的字典 |
| read_json | 将json对象转换为Pandas对象 | Series或DataFrame,具体取决于参数typ设置 |
| read_msgpack | 从指定文件中加载msgpack Pandas对象 | 文件中的对象类型 |
| read_pickle | 从指定文件中加载pickled Pandas或其他pickled对象 | 文件中的对象类型 |
| read_sas | 读取XPORT或SAS7BDAT格式的SAS(统计分析软件)文件 | DataFrame或SAS7BDATReader或XportReader,具体取决于设置 |
| read_sql | 读取SQL请求或数据库中的表 | DataFrame |
| read_sql_query | 从SQL请求读取数据 | DataFrame |
| read_sql_table | 读取SQL数据库中的表 | DataFrame |
| read_stata | 读取Stata(统计分析软件)文件 | DataFrame或StataReader |
下面是不同场景较为合适的数据读取方法:
- 纯文本格式或非格式化、非结构化的数据,常用语自然语言处理、非结构文本解析、应用正则表达式等后续应用场景下,Python默认的三种方法更为合适。
- 结构化、纯数值型的数据,并且主要用于矩阵计算、数据建模的,使用Numpy的loadtxt更方便。
- 对于二进制的数据处理,使用Numpy的load和fromfile方法更为合适。
- 对于结构化的、探索性数据统计和分析场景,使用pandas方法进行读取,因为其提供了数据框,对数据进行任意翻转、切片、关联都很方便。