GBDT有很多简称,有GBT(Gradient Boosting Tree), GTB(Gradient Tree Boosting ), GBRT(Gradient Boosting Regression Tree), MART(Multiple Additive Regression Tree),其实都是指的同一种算法。
1. GBDT概述
GBDT是集成学习Boosting中一员,与传统Adaboost不同。Adaboost利用弱学习器的误差率更新训练集的权重,这样迭代下去。GBDT使用前向分布算法迭代,弱学习器只能使用CART回归树,迭代思路与Adaboost也不同。
在GBDT的迭代中,假设前一轮迭代得到的强学习器是 ft-1(x) ,损失函数是 L(y, ft-1(x)),那么本轮迭代的目标是找到一个CART回归树模型的弱学习器 ht(x),让本轮的损失函数 L(y, ft(x) + ht(x))最小。即本轮迭代找到一个决策树,让损失函数变小。
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代,每一轮迭代,拟合的岁数误差都会减小。
但是这个损失的拟合不好度量,损失函数各种各样,怎么找到一种通用的拟合方法?
2. GBDT的负梯度拟合
Freidman提出用损失函数的负梯度拟合本轮损失的近似值,进而拟合一个CART回归树。
第 t 轮第 i 个样本的损失函数的负梯度表示为:
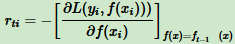
利用(xi, rti) (i = 1,2,...m),拟合一个CART回归树,得到第 t 个回归树,对应叶节点区域 Rtj,j = 1,2,...J。其中 J 为叶节点的个数。
针对每一个叶子节点里的样本,求出使损失函数最小,也就是拟合叶子节点最好的输出值 ctj 如下:
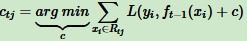
这样得到本轮决策树拟合函数:
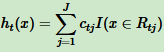
从而得到本轮强学习器表达式:
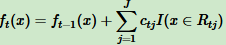
无论分类还是回归,通过损失函数的负梯度拟合,就可以用GBDT来解决。区别在于损失函数不同导致负梯度不同。
3. GBDT回归算法
输入:训练集样本 T = {(x, y1), (x2, y2),...(xm, ym)},最大迭代次数 T,损失函数 L
输出:强学习器 f(x)
(1) 初始化弱学习器
(2) 对迭代轮数 t = 1,2,...T,有:
a. 对样本 i=1,2,...m,计算负梯度
b. 利用(xi, rti) (i=1,2,...m),拟合一个CART回归树,得到第 t 个回归树,其对应的叶子节点区域为 Rtj ,j = 1,2,3...J。其中 J 为叶子节点的个数。
c. 对叶子区域 j = 1,2,3...J,计算最佳拟合值
d. 更新强学习器

(3). 得到强学习器 f(x) 的表达式
4. GBDT分类算法
分类算法的输出是离散的类别值,需要处理才能使用负梯度。
两个方法:一是用指数损失函数,此时GBDT退化为Adaboost算法。二是用类似逻辑回归的对数似然损失函数方法。