感知机是最早的分类方法之一,现在它的泛化能力不强。
1. 感知机模型
感知机思想:在二维就是找到一条直线,在三维或者更高维就是找到一个超平面,将所有二元类别分开。
找不到这条直线或超平面就是类别线性不可分,感知机不适合该数据分类。使用感知机最大前提就是数据线性可分。支持向量机面对不可分时通过核函数让数据高维可分,神经网络通过激活函数和隐藏函数让数据可分。
比如,有m个样本,每个样本对应n维特征和一个二元类别输出:
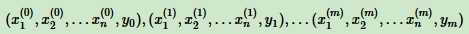
目标找到一个超平面,即:
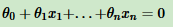
让一种类别的样本满足 ,另一种类别的样本满足
,另一种类别的样本满足 ,从而线性可分,这样的超平面都不是唯一的,也就是说感知机有多个解。
,从而线性可分,这样的超平面都不是唯一的,也就是说感知机有多个解。
为简化超平面写法,增加一个特征x0 = 1,这样超平面为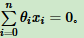 。用向量表示:Θ·x = 0,其中θ为1×(n+1)的向量,x为(n+1)×1的向量,•为内积。
。用向量表示:Θ·x = 0,其中θ为1×(n+1)的向量,x为(n+1)×1的向量,•为内积。
感知机模型可定义为:y = sign(θ•Χ)
当没增加特征x0 = 1时,其中θ为1×n的向量,x为n×1的向量,•为内积。感知机模型定义为:y = sign(θ•Χ + b)
其中: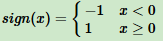 为符号函数,θ叫权值或权值向量(也就是超平面的法向量),b叫偏置(bias)(也就是超平面的截距)。
为符号函数,θ叫权值或权值向量(也就是超平面的法向量),b叫偏置(bias)(也就是超平面的截距)。
2. 感知机模型损失函数
将满足θ•x > 0的样本类别输出取为1,满足θ•x < 0的样本类别输出取为-1,这样取,方便定义损失函数。因为正确分类的样本满足yθ•x > 0,错误分类样本满足yθ•x < 0(错误分类,y与Θ•x正负号相反。在误分类中,当Θ•x>0,y=-1;当Θ•x<0,y=1)。损失函数优化目标就是:使所有误分类样本到超平面距离之和最小。
这里定义超平面为:Θ·x = 0,所以样本中任意一点m到超平面距离为:
Θ•x(m) / ||θ||2
由于误分类样本定义为:yθ•x < 0,对于每一个误分类的样本 i,到超平面距离(加“-”使距离为正):

其中||θ||2为L2范数。
假设所有误分类点集合为M,则所有误分类的样本到超平面距离之和为:
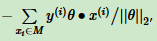
这就是初步的感知机模型损失函数。
其中分子分母都含有θ,它们固定的倍数关系。那固定分子或分母为1,然后求另一个,即分母的倒数或者分子自己的最小化作为损失函数。在感知机中,是保留分子,则感知机模型损失函数:
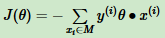
支持向量机是固定分子为1,求1/||Θ||2最大化。
3. 感知机模型损失函数优化方法
感知机损失函数,M是所有误分类点的集合。这个损失函数用梯度下降法或拟牛顿法解决,常用梯度下降法。
普通的基于所有样本的梯度和均值的批量梯度下降法(BGD)行不通,原因在于损失函数有限定,只有M里的样本才参与损失函数的优化。所以不能用最普通的批量梯度下降,只能采用随机梯度下降(SGD)或小批量梯度下降(MBGD)。
感知机模型采用随机梯度下降,意味每次仅使用一个误分类点更新梯度。
损失函数基于θ向量的偏导数:
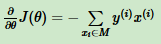
θ的梯度下降迭代公式:

采用随机梯度下降,每次仅使用一个误分类点更新梯度,假设第 i 个样本更新梯度,则简化后梯度下降迭代公式:
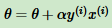
其中α为步长,y(i)为样本输出1或-1,x(i)为(n+1)×1的向量。
4. 感知机模型算法
感知机基于随机梯度下降法求θ向量的总结:
输入是m个样本,每个样本对应n维特征和一个二元类别输出1或者-1,如下:
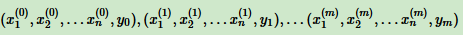
输出为分离超平面的模型系数θ向量
执行步骤:
1. 定义所有x0为1。Θ向量置为0向量,步长α设为1。由于感知机的解不唯一,这两个初值会影响θ向量的最终迭代结果。
2. 在训练集里选择一个误分类点 ,用向量表示即
,用向量表示即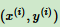 ,这个点满足:
,这个点满足: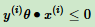
3. 对θ向量进行一次随机梯度下降的迭代: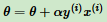
4. 检查训练集是否还有误分类点,没有,算法结束,θ向量为最终结果;如果有,继续第二步。
5. 感知机模型的算法对偶形式
对偶形式是用Gram(格莱姆)矩阵优化算法执行速度。
每次迭代都是选择一个样本来更新θ向量。对于没有误分类的样本,参与θ迭代的次数是0,对于多次误分类而更新的样本 j,它参与θ迭代的次数设置为mj。令θ向量初始值为0向量,这样θ向量表达式为:
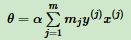
其中mj为样本(x(j), y(j))在随机梯度下降到当前 因误分类而更新的次数。
每一个样本(x(i), y(j))的mj的初始值为0,每次梯度下降迭代中因误分类而更新时,mj值加1。
由于步长α为常量,令βj = αmj,这样θ向量的表达式为:
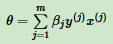 在每一步判断误分类条件的地方,用y(i)Θ•x(i) < 0的变种
在每一步判断误分类条件的地方,用y(i)Θ•x(i) < 0的变种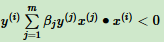 来判断误分类。这个判断误分类形式里面是两个样本x(i)和y(j)的内积,而且这个内积计算结果在下面迭代中可以重用。如果事先用矩阵运算计算所有样本之间的内积,那么在算法运行时,仅一次的矩阵运算比多次循环计算省时。这就是对偶形式的感知机模型比原始模型优的原因。
来判断误分类。这个判断误分类形式里面是两个样本x(i)和y(j)的内积,而且这个内积计算结果在下面迭代中可以重用。如果事先用矩阵运算计算所有样本之间的内积,那么在算法运行时,仅一次的矩阵运算比多次循环计算省时。这就是对偶形式的感知机模型比原始模型优的原因。
样本的内积成为Gram矩阵(格莱姆矩阵),是一个内积对称矩阵,记为 G = |x(i) • y(j)|
下面是感知机模型算法的对偶形式内容:
输入是m个样本,每个样本对应n维特征和一个二元类别输出1或者-1,如下:
输出为分离超平面的模型系数θ向量
执行步骤:
1. 定义所有x0为1。β初值为0,步长α设为1。由于感知机的解不唯一,这两个初值会影响θ向量的最终迭代结果。
2. 在训练集里选择一个误分类点,这个点满足: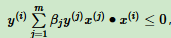 ,再检查是否满足可以通过查询Gram矩阵的 gij 值来快速计算是否小于0。
,再检查是否满足可以通过查询Gram矩阵的 gij 值来快速计算是否小于0。
3. 对β向量的第 i 个分量进行一次更新:βi = βi + α
4. 检查训练集是否还有误分类点,没有,算法结束,此时的 θ 向量最终结果。如果有,继续第2步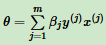
其中 βj 为 β 向量的第 j 个分量。