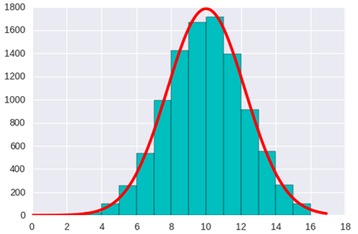
随机采样
采样是根据某种分布去生成一些数据点。最基本的假设是认为我们可以获得服从均匀分布的随机数,再根据均匀分布生成复杂分布的采样。对于离散分布的采样,可以把概率分布向量看作一个区间段,然后判断u落在哪个区间段内。对于比较复杂的分布比如正态分布我们可以通过Box-Muller算法,实现对高斯分布的采样。
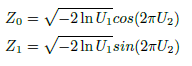
其他几个著名的连续分布,包括指数分布,Gamma分布,t分布,F分布,Beta分布,Dirichlet分布都可以通过类似的数学变换得到。
蒙特卡洛估计
从一个分布中采样可以做很多有用的事情,包括求边缘分布,MAP推断,以及计算如下形式的期望
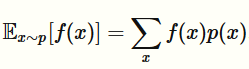
通过蒙特卡洛方法可以得到该期望的近似解

其中 是从分布p中采样得到的
是从分布p中采样得到的
拒绝采样

举例:比如要计算圆的面积可以在矩形中均匀的撒点,统计落在圆中的点的个数处于总的点的个数,就是圆的面积与矩形面积的比值。
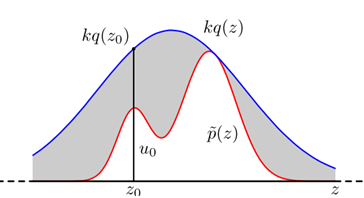
假设我们已经可以抽样高斯分布q(x)(如Box–Muller_transform 算法),我们按照一定的方法拒绝某些样本,达到接近p(x)分布的目的。
拒绝采样时蒙特卡洛中的一种特殊情况。计算p(x=x'):我们可以将这个概率写成如下形式
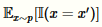
接着采用蒙特卡洛近似
重要采样
拒绝采样会浪费大量的样本,一个更好的方法是通过重要采样进行采样。
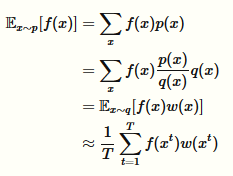
本来需要从p分布中进行采样,由于种种原因(p分布不好采样等)我们不愿意从p分布中采样,而是从q分布中采样,需要在f中乘上权重因子w(x)
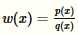
对于p(x=x')可以通过如下的计算
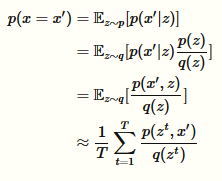
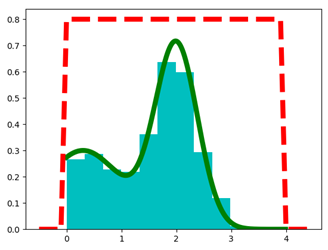
Python代码
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import seaborn
def qsample():
return np.random.rand() * 4.
def p(x):
return 0.3 * np.exp(-(x - 0.3) ** 2) + 0.7 * np.exp(-(x - 2.) ** 2 / 0.3)
def q(x):
return 4.0
def importance(nsamples):
samples = np.zeros(nsamples, dtype=float)
w = np.zeros(nsamples, dtype=float)
for i in range(nsamples):
samples[i] = qsample()
w[i] = p(samples[i]) / q(samples[i])
return samples, w
def sample_discrete(vec):
u = np.random.rand()
start = 0
for i, num in enumerate(vec):
if u > start:
start += num
else:
return i - 1
return i
def importance_sampling(nsamples):
samples, w = importance(nsamples)
# print samples
final_samples = np.zeros(nsamples, dtype=float)
w = w / w.sum()
# print w
for j in range(nsamples):
final_samples[j] = samples[sample_discrete(w)]
return final_samples
x = np.arange(0, 4, 0.01)
x2 = np.arange(-0.5, 4.5, 0.1)
realdata = 0.3 * np.exp(-(x - 0.3) ** 2) + 0.7 * np.exp(-(x - 2.) ** 2 / 0.3)
box = np.ones(len(x2)) * 0.8
box[:5] = 0
box[-5:] = 0
plt.plot(x, realdata, 'g', lw=6)
plt.plot(x2, box, 'r--', lw=6)
# samples,w = importance(5000)
final_samples = importance_sampling(5000)
plt.hist(final_samples, normed=1, fc='c')
plt.show()
MCMC(Markov Chain Monte Carlo)
MCMC采样算法
从马尔科夫链中对某个分布进行采样,采样的结果通过蒙特卡洛方法来对期望进行估计。

一个直观的理解是:收集了可能来自需要观测山的大量地点,我们就可以近似的构造出这座山出来。
从当前地点开始,移动到一个靠近你的新地点。如果该地点可能来自需要观测的山,那么移动到该地点,如果不是待在原处。通过大量的迭代,返回所有可能的地点。
MCMC适合使用在高维的空间中,会提高采样的效率。
细致平稳条件

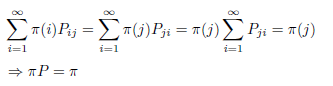
假设我们已经有一个转移矩阵为Q马氏链(q(i,j))表示从状态i转移到状态j的概率,通常情况下

也就是细致平稳条件不成立,所以p(x)不太可能是这个马氏链的平稳分布。为此需要引入

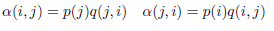
所以有
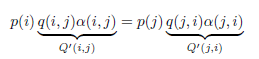


Metropolis-Hastings采样算法
以上MCMC算法已经可以工作了,但是它有一个小的问题:马氏链Q在转移的过程中可能偏小,这样采样过程中马氏链容易原地踏步。因此需要提高接受率。
假设
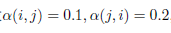
此时满足细致平稳条件,于是
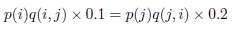
上式两边扩大5倍,我们改写为
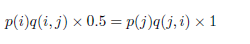
我们提高了接收率,而细致平稳条件没有打破。这启发我们可以把细致平稳条件的同比例放大,使得两数中最大的一个放大到1,这样就提高了采样中的跳转接受率。


Python代码:
# The Metropolis-Hastings algorithm
from pylab import *
from numpy import *
def p(x):
mu1 = 3
mu2 = 10
v1 = 10
v2 = 3
return 0.3*exp(-(x-mu1)**2/v1) + 0.7* exp(-(x-mu2)**2/v2)
# return -x**2
def q(x):
mu = 5
sigma = 10
return exp(-(x-mu)**2/(sigma**2))
stepsize = 0.5
x = arange(-10,20,stepsize)
px = zeros(shape(x))
for i in range(len(x)):
px[i] = p(x[i])
N = 5000
# independence chain
u = random.rand(N)
mu = 5
sigma = 10
y = zeros(N)
y[0] = random.normal(mu,sigma)
for i in range(N-1):
ynew = random.normal(mu,sigma)
alpha = min(1,p(ynew)*q(y[i])/(p(y[i])*q(ynew)))
if u[i] < alpha:
y[i+1] = ynew
else:
y[i+1] = y[i]
# random walk chain
u2 = random.rand(N)
sigma = 10
y2 = zeros(N)
y2[0] = random.normal(0,sigma)
for i in range(N-1):
y2new = y2[i] + random.normal(0,sigma)
alpha = min(1,p(y2new)/p(y2[i]))
if u2[i] < alpha:
y2[i+1] = y2new
else:
y2[i+1] = y2[i]
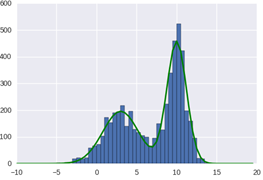
figure(1)
nbins = 30
hist(y, bins = x)
plot(x, px*N/sum(px), color='g', linewidth=2)
plot(x, q(x)*N/sum(px), color='r', linewidth=2)
figure(2)
nbins = 30
hist(y2, bins = x)
plot(x, px*N/sum(px), color='g', linewidth=2)
show()
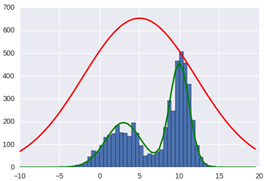
该代码用到一个比较特殊的马尔科夫过程:当一个随机变量,其增量的变化服从于正态分布时,我们说,这个随机过程叫做维纳过程(Wiener process)——或者一个更出名的名字:布朗运动过程
设x(t)是一个独立增量过程,即随机过程x(t)的下一阶段增量的概率分布独立于其他任意阶段的概率分布
X(t)是一个关于t的连续函数;
X(t)的增量服从关于时间t的正态分布,即
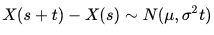
Gibbs采样
由于Metropolis-Hastings采样的通常小于1。所以Gibbs进一步提高到1。
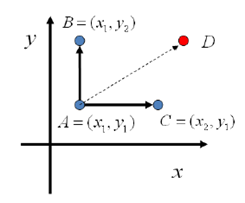
考虑二维的情形,假设有一个概率分布p(x,y),考虑x坐标相同的两个点A(x1,y1),B(x1,y2)
我们发现
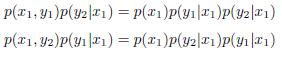
所以得到

即

基于以上等式,我们发现,在x=x1这条平行于y轴的直线上,如果使用条件分布p(y|x1)做为任何两点之间的转移概率,那么任何两个点之间的转移满足细致平稳条件。
于是我们可以如下构造平面上任意两点之间的状态转移概率矩阵Q

有了如上的转移矩阵Q,我们很容易验证对平面上任意两点X,Y,满足细致平稳条件


以上采样过程中,如图所示,马氏链的转移只是轮换的沿着坐标轴x轴和y轴做转移
很容易将算法扩展到高维的情况中

Python代码:
def pXgivenY(y,m1,m2,s1,s2):
return np.random.normal(m1 + (y-m2)/s2,s1)
def pYgivenX(x,m1,m2,s1,s2):
return np.random.normal(m2 + (x-m1)/s1,s2)
def gibbs(N=5000):
k=20
x0 = np.zeros(N,dtype=float)
m1 = 10
m2 = 20
s1 = 2
s2 = 3
for i in range(N):
y = np.random.rand(1)
# 每次采样需要迭代 k 次
for j in range(k):
x = pXgivenY(y,m1,m2,s1,s2)
y = pYgivenX(x,m1,m2,s1,s2)
x0[i] = x
return x0
def f(x):
"""目标分布"""
return np.exp(-(x-10)**2/10)
# 画图
N=10000
s=gibbs(N)
x1 = np.arange(0,17,1)
plt.hist(s,bins=x1,fc='c')
x1 = np.ar
ange(0,17, 0.1)
px1 = np.zeros(len(x1))
for i in range(len(x1)):
px1[i] = f(x1[i])
plt.plot(x1, px1*N*10/sum(px1), color='r',linewidth=3)
plt.show()