转载自:https://blog.csdn.net/qq_21125183/article/details/90019034
注:针对为什么使用对节点个数进行取模会造成数据搬迁过多的解释,详见这篇博客:http://www.mamicode.com/info-detail-2224804.html
1. 前言
在Redis 集群模式Cluster中,Redis采用的是分片Sharding的方式,也就是将数据采用一定的分区策略,分发到相应的集群节点中。但是我们使用上述HASH算法进行缓存时,会出现一些缺陷,主要体现在服务器数量变动的时候,所有缓存的位置都要发生改变!具体来讲就是说第一当缓存服务器数量发生变化时,会引起缓存的雪崩,可能会引起整体系统压力过大而崩溃(大量缓存同一时间失效)。第二当缓存服务器数量发生变化时,几乎所有缓存的位置都会发生改变。
2. 一致性哈希的基本概念
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对232取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-232-1(即哈希值是一个32位无符号整形),整个哈希环如下:
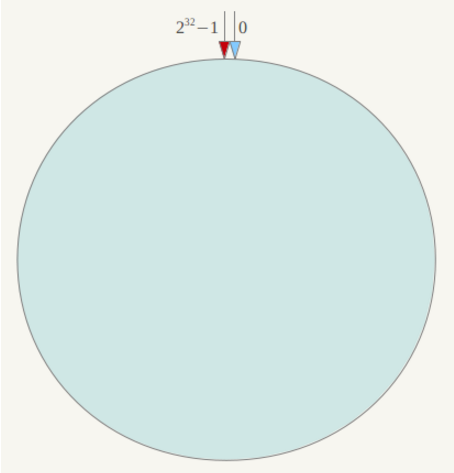
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到232-1,也就是说0点左侧的第一个点代表232-1, 0和232-1在零点中方向重合,我们把这个由232个点组成的圆环称为Hash环。
那么,一致性哈希算法与上图中的圆环有什么关系呢?我们继续聊,仍然以之前描述的场景为例,假设我们有4台缓存服务器,服务器A、服务器B、服务器C,服务器D,那么,在生产环境中,这4台服务器肯定有自己的IP地址或主机名,我们使用它们各自的IP地址或主机名作为关键字进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式示意:

通过上述公式算出的结果一定是一个0到232-1之间的一个整数,我们就用算出的这个整数,代表服务器A,既然这个整数肯定处于0到232-1之间,那么,上图中的hash环上必定有一个点与这个整数对应,而我们刚才已经说明,使用这个整数代表服务器A,那么,服务器A就可以映射到这个环上。
以此类推,下一步将各个服务器使用类似的Hash算式进行一个哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用IP地址哈希后在环空间的位置如下:
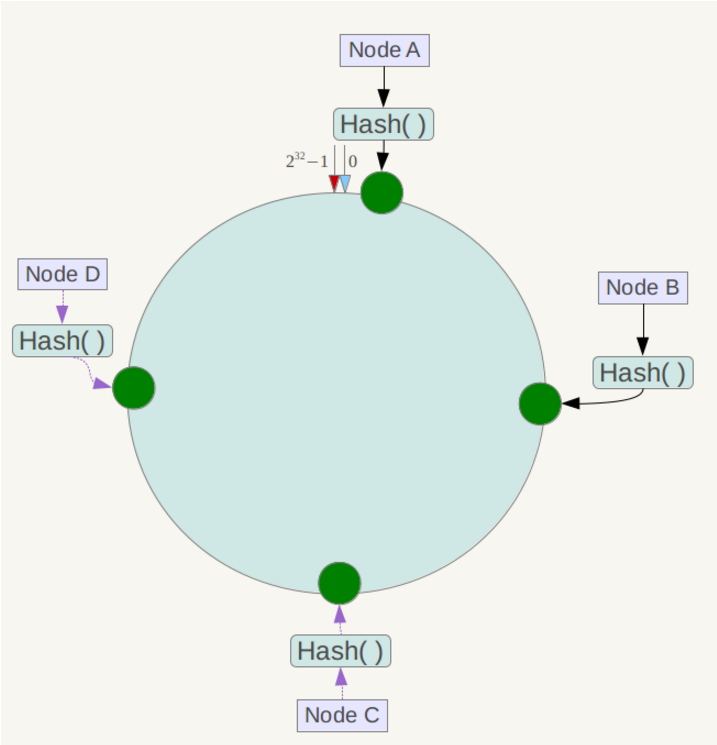
接下来使用如下算法定位数据访问到相应服务器: 将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
3. 一致性Hash算法的容错性和可扩展性
现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响,如下所示:

下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
4. Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上,从而出现hash环偏斜的情况,当hash环偏斜以后,缓存往往会极度不均衡的分布在各服务器上,如果想要均衡的将缓存分布到2台服务器上,最好能让这2台服务器尽量多的、均匀的出现在hash环上,但是,真实的服务器资源只有2台,我们怎样凭空的让它们多起来呢,没错,就是凭空的让服务器节点多起来,既然没有多余的真正的物理服务器节点,我们就只能将现有的物理节点通过虚拟的方法复制出来。
这些由实际节点虚拟复制而来的节点被称为"虚拟节点",即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
————————————————
版权声明:本文为CSDN博主「MasterT-J」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_21125183/article/details/90019034