排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简介)。LTR有三种主要的方法:PointWise,PairWise,ListWise. RankNet是一种Pairwise方法, 由微软研究院的Chris Burges等人在2005年ICML上的一篇论文Learning to Rank Using Gradient Descent中提出,并被应用在微软的搜索引擎Bing当中。
1. 损失函数
损失函数一直是各种Learning to Rank算法的核心, RankNet亦然.
RankNet是一种Pairwise方法, 定义了文档对<A, B>的概率(假设文档A, B的特征分别为xi,xj):

其中oij=oi-oj, oi=f(xi), RankNet使用神经网络来训练模型, 所以f(xi)是神经网络的输出。
如果文档A比文档B和查询q更加相关, 则目标概率:![]() =1, 如果文档B比文档A更相关, 目标函数
=1, 如果文档B比文档A更相关, 目标函数![]() =0, 如果A和B同样相关, 则
=0, 如果A和B同样相关, 则![]() =0.5.
=0.5.
有了模型输出的概率Pij和目标概率![]() , 我们使用交叉熵来作为训练的损失函数:
, 我们使用交叉熵来作为训练的损失函数:
![]()
在三种不同的目标概率下, 损失函数和oij之间的关系如下图所示:

可以看到, 在![]() =1时, oij越大损失函数越小,
=1时, oij越大损失函数越小, ![]() =0时,
=0时, ![]() 越小损失函数越小,
越小损失函数越小, ![]() =0.5时,
=0.5时, ![]() =0.5时损失函数最小。
=0.5时损失函数最小。
![]() 本身也有一些非常好的特性, 给定
本身也有一些非常好的特性, 给定![]() 和
和![]() , 得到:
, 得到:
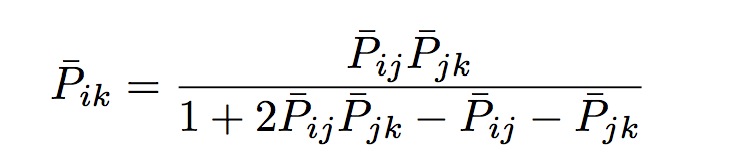
令![]() =
=![]() =P, 得到P和
=P, 得到P和![]() 的关系如下图所示:
的关系如下图所示:
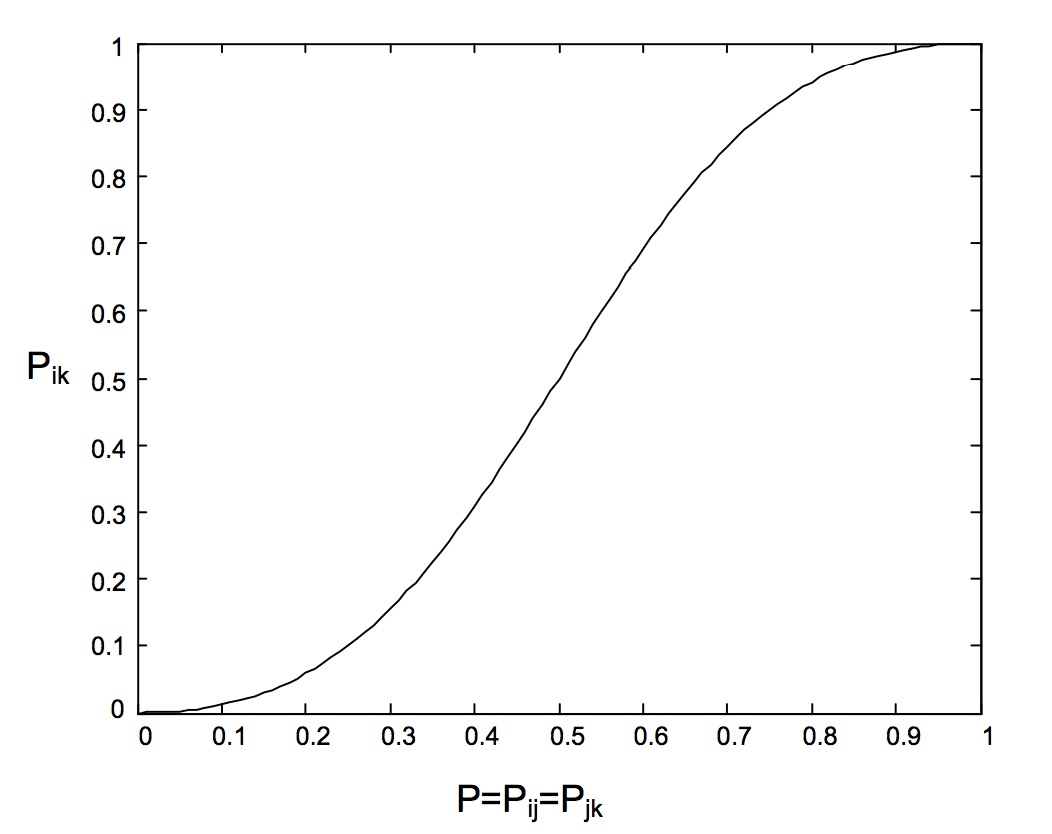
可以看到, 当P>0.5时, 亦即i>j, j>k时, 有![]() >0.5, 亦即i>k, 这说明概率P具有一致性(consistency).
>0.5, 亦即i>k, 这说明概率P具有一致性(consistency).
2. RankNet算法
RankNet使用神经网络来训练模型, 使用梯度下降来优化损失函数。特别的, Chris Burges等人在论文中证明, 对于m个文档{d1,d2,...,dm}, 需要且只需要知道相邻文档之间的概率Pij,就可以算出任意两个文档之间的后验概率![]() . 可以实现对m个文档做任意排列, 然后以排列后的相邻文档之间的概率Pij作为训练数据, 然后训练模型, 时间复杂度为O(N), 优于Ranking SVM的O(N2)。
. 可以实现对m个文档做任意排列, 然后以排列后的相邻文档之间的概率Pij作为训练数据, 然后训练模型, 时间复杂度为O(N), 优于Ranking SVM的O(N2)。
在使用神经网络进行训练时, 将排好序的文档逐个的放入神经网络进行训练, 然后通过前后两个文档之间的oij=oi-oj来训练模型, 每一次迭代, 前向传播m次, 后向反馈m-1次。
RankLib中有RankNet等Learning to Rank算法的开源Java实现。
参考文献:
[1]. Chris Burges, et al. Learning to Rank using Gradient Descent, ICML, 2005.
[2]. Tie-yan Liu. Learning to Rank for Information Retrieval.
[3]. Learning to Rank简介
[4]. RankLib