本文在我的上一篇博文 机器学习-特征选择(降维) 线性判别式分析(LDA) 的基础上进一步介绍核Fisher LDA算法。
之前我们介绍的LDA或者Fisher LDA都是线性模型,该模型简单,对噪音的鲁棒性较好,不容易过拟合,但是,简单模型的表达能力会弱一些,为了增加LDA算法的表达能力,我们可以将数据投影到非线性的方向上去。为了达到这个目的,我们可以先将数据非线性的投影到一个特征空间F内,然后在这个F空间内计算Fisher 线性判别式,达到降维的目的。
首先介绍一下核函数的概念:
如果F空间的维数非常高甚至是无穷维数,那么单纯的只是将原数据投影到F空间就是一个很大的计算量。但是,我们可以并不显式的进行数据的投影,而只是计算原数据的点乘:(Φ (x)·Φ (y)).如果我们可以快速高效的计算出点乘来,那么我们可以无须将原数据投影到F空间就解决问题(关于这一点,Andrew Ng的讲义中举过一些例子,详见附录1)。我们使用Mercer核:k(x,y)=(Φ (x)·Φ (y)),可以选择高斯径向基函数核(Gaussian RBF):k(x,y)=exp(-|x-y|2/c),或者多项式核:k(x,y)=(x·y)d,或者S形核:tanh(kx·y-δ),其中c,d和δ都是正的常数。
我们用Φ表示一个投影到F特征空间的映射函数,为了得到F空间内的Fisher线性判别式,我们需要最大化:
 式子-1
式子-1
其中ω∈F空间,而SBΦ和SWΦ分别为:
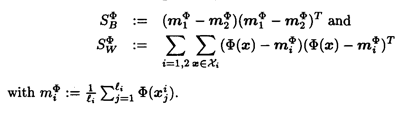
我们需要将式子-1转换成一个只含有点乘的形式,这样的话我们就可以只使用核函数来表达式子-1了。
我们知道,任意F空间内的解ω都可以由投影到F空间内的原数据组合得到:
 式子-2
式子-2
根据式子-2,以及miΦ的定义,我们能够得到:
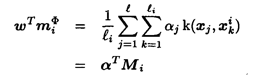 式子-3
式子-3
其中:
根据式子-3和SBΦ的定义,式子-1中的分子可以写为:
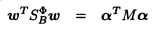 式子-4
式子-4
其中 .
.
根据式子-2和miΦ的定义,式子-1中的分母可以写为:
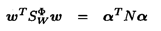 式子-5
式子-5
其中 ,Kj是一个l*lj的矩阵:
,Kj是一个l*lj的矩阵: ,I是单位矩阵,llj是所有项都是1/lj的矩阵。
,I是单位矩阵,llj是所有项都是1/lj的矩阵。
由式子-4和式子-5可以得到,我们只需要最大化
 式子-6
式子-6
与Fisher LDA一样,最大化式子-6的解为N-1M矩阵的最大的特征值对应的特征向量。
原数据在ω的投影为:

附录1. Andrew Ng关于核函数可能比先将数据投影到F空间,然后再点乘计算复杂度更小的例子:
我们考虑核函数K(x,z)=(xTz)2
其中x和z都是N维向量,如果直接计算上式(核函数),则计算复杂度为O(N),亦即和数据的维数是线性的关系。
接下来看一下首先将数据投影到新空间,然后计算K(x,z)的过程和计算复杂度,首先重新表达K(x,z):

然后将数据x和z利用Φ(·)投影到新空间,亦即:

最后计算K(x,z)= Φ(x)*Φ(z)。我们可以看到,计算Φ(·)的复杂度为O(N2).
所以,在有些情况下,K(x,z)本身可能比较容易计算,而Φ(·)的计算量反而可能会更大。
参考文献:
[1] Fisher Discriminant Analysis with Kernals. Sebastian Mika, Gunnar Ratsch, Jason Weston, Bernhadr Scholkopf, Klaus-Robert Muller.
[2] Fisher Linear Discriminant Analysis. Max Welling.
[3] CS229 Lecture notes, Part 5, Support Vector Machine. Andrew Ng.