在C2 code_gen后期(指令选择->指令调度->寄存器分配->基本块排序->本地代码生成)会用PhaseBlockLayout做这个基本块排序。
// Prior to register allocation we kept empty basic blocks in case the
// the allocator needed a place to spill. After register allocation we
// are not adding any new instructions. If any basic block is empty, we
// can now safely remove it.
{
TracePhase tp("blockOrdering", &timers[_t_blockOrdering]);
cfg.remove_empty_blocks();
if (do_freq_based_layout()) {
PhaseBlockLayout layout(cfg);
} else {
cfg.set_loop_alignment();
}
cfg.fixup_flow();
}
1. 移除空block
在寄存器分配之前,我们保留了空block,因为寄存器分配可能会spill一些值,这些spill操作可以放到空block里面。寄存器分配之后,就不会向空block写指令了,所以这个时候我们可以安全的移除它们,remove_empty_blocks就是做这个事情的。
2. 基本块排序
PhaseBlockLayout就是基本块重排序的核心实现,这个phase用到的抽象主要是edge和trace。edge表示基本块之间的边,trace表示一个基本块组成的有序列表。原算法描述如下:
- Find all CFG edges that could be embodied by a branch or fallthroough
- Compute an edge frequencies using block frequencies and branch probabilities
- Make a list of edges sorted the in descending order by frequency
- Create a Trace (an ordereed list of basic blocks) for every basic block
- For each edge, in descending frequency
- if the edge is from the tail of one trace to the head of another
- if the traces are different, append the traces
- else, process edges as a back-branch (and possibly rotate loop)
- Make diamonds, when it is deemed profitable to merge one trace into the middle of another
- Append remaining traces end-to-end if an unprocessed edge indicates transfer between traces.
- Order remaining traces by frequency of first block
下面是我的分析。先给Java源码:
public class Reduced {
static int foo(int i) {
int sum=0;
if (i < 4000) {
sum*=3;
sum+=i;
}
if(i<5000){
sum %=i+1;
sum -=i;
} else {
sum +=333;
}
sum +=25;
return sum;
}
public static void main(String[] args) throws Exception{
for(int i=0;i<600000;i++){
foo(i);
}
}
}
然后是理想图,不需要详细,能看到控制流动即可。
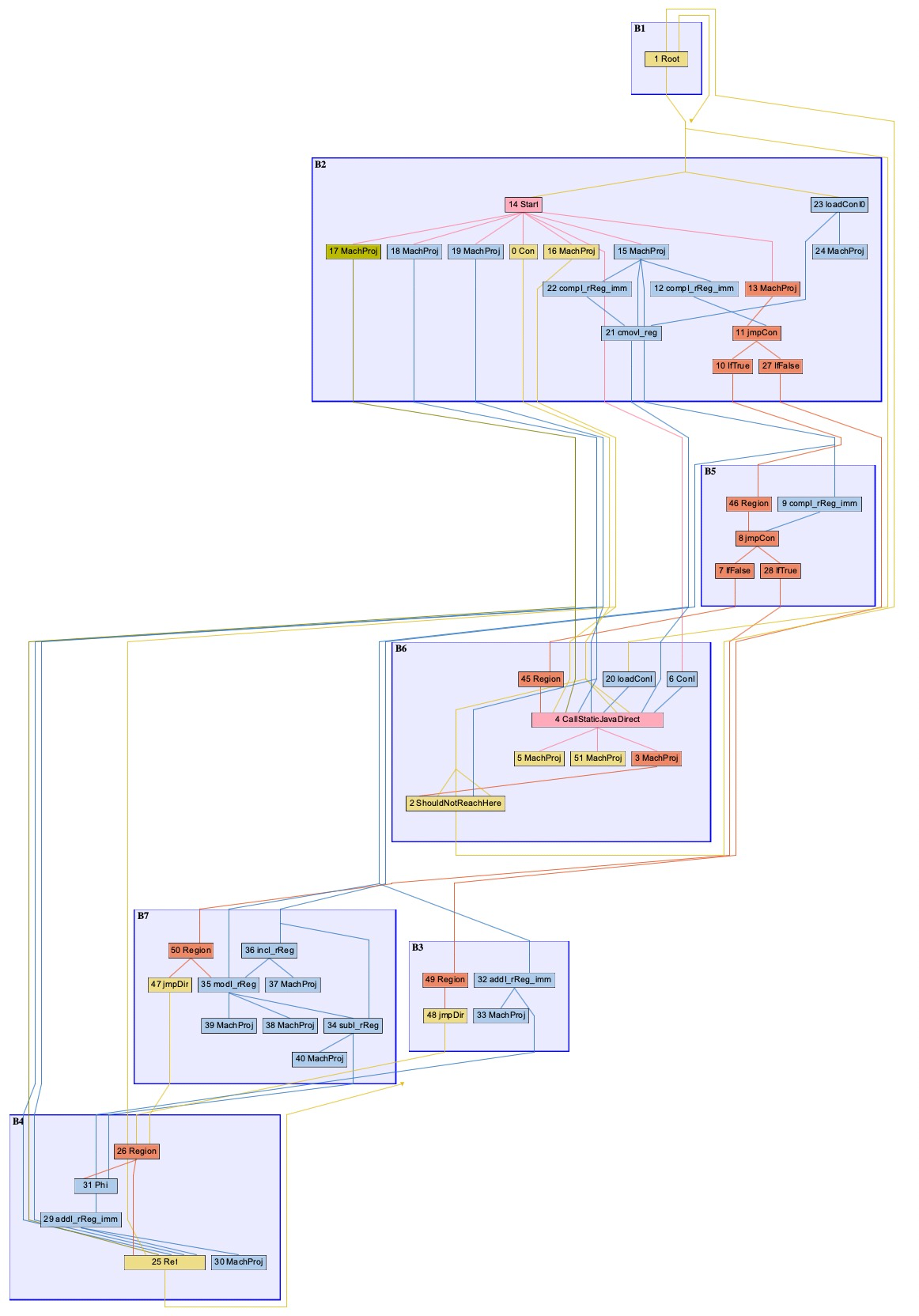
2.1 寻找edge(find_edges)
第一步会创建trace和edge。trace其实可以理解为一个“轨迹”,一个trace就是执行流是比较丝滑一次走完的,换句话说,它可以把很少走到的slow_path bblocks抛弃,剩余的bblocks形成一个流程执行的轨迹。edge就是连接这些trace的变,第一步find_edges走完的时候Edge和Trace如下:
===EDGES===
B1 --> B2 Freq: 1.000000 out:100% in:100% State: open
B2 --> B5 Freq: 0.500000 out: 50% in:100% State: open
B2 --> B3 Freq: 0.500000 out: 50% in:100% State: open
B5 --> B6 Freq: 0.000001 out: 0% in:100% State: open infrequent
B5 --> B7 Freq: 0.499999 out: 99% in:100% State: open
B7 --> B4 Freq: 0.499999 out:100% in: 49% State: open
B3 --> B4 Freq: 0.500000 out:100% in: 50% State: open
===TRACES==
Trace (freq 1.000000)
B1 (L16)
Trace (freq 1.000000)
B2
Trace (freq 0.500000)
B5
Trace (freq 0.499999)
B7
Trace (freq 0.000001)
B6
Trace (freq 0.500000)
B3
Trace (freq 0.999999)
B4
2.2 延长trace(grow_traces)
顾名思义,这一步会尽量“grow”一个trace。具体来说,如果发现一个edge两端block刚好是trace的头尾,那么可以延长这个trace(注意这一步和下一步,下一步只要求两端block有一个是头尾即可)。
举个例子,这一步遍历所有edge,遇到B1(form block)->B2(to block)这个edge,此时trace如下:
Trace (freq 1.000000)
B1 (L16)
Trace (freq 1.000000)
B2
由于B1正好是第一个trace的尾巴(此时只有一个block,所以B1既是头又是尾),B2正好是第二个trace的头部,可以延长第一个trace,延长后的第个trace如下:
Trace (freq 1.000000)
B1 (L16) B2
接着处理B2->B3 这个edge,两端block对应trace如下:
Trace (freq 1.000000)
B1 (L16) B2
Trace (freq 0.500000)
B3
B2是第一个trace尾巴,B3是第二个trace头部,再次延长第一个trace,延长后的trace:
Trace (freq 1.000000)
B1 (L16) B2 B3
如此继续,最终trace如下:
Trace (freq 1.000000)
B1 (L16) B2 B3 B4
B1、B2、B3、B4共同形成一个trace。另外B5和B7也会形成一个trace:
Trace (freq 0.500000)
B5 B7
还是很直白?函数名字已经说明了很多东西。这一步还有一个比较困惑的地方,为什么先处理B2->B3,而不是B2->B5?如果先处理B2->B5,那最终的轨迹就完全不一样了,将会包含B5而不是B3。要回答这个问题可以看看源码,这一步在处理边之前会对边进行排序,主要是按照frequency,其次是编号。两个edge如下:
B2 --> B5 Freq: 0.500000 out: 50% in:100% State: open
B2 --> B3 Freq: 0.500000 out: 50% in:100% State: open
它们frequency一样所以用的是编号排序,所以先处理的是B2->B3这条边。这一步处理完edge和trace如下:
===EDGES===
B1 --> B2 Freq: 1.000000 out:100% in:100% State: connected
B2 --> B3 Freq: 0.500000 out: 50% in:100% State: connected
B2 --> B5 Freq: 0.500000 out: 50% in:100% State: open
B3 --> B4 Freq: 0.500000 out:100% in: 50% State: connected
B7 --> B4 Freq: 0.499999 out:100% in: 49% State: open
B5 --> B7 Freq: 0.499999 out: 99% in:100% State: connected
B5 --> B6 Freq: 0.000001 out: 0% in:100% State: open infrequent
===TRACES==
Trace (freq 1.000000)
B1 (L16) B2 B3 B4
Trace (freq 0.500000)
B5 B7
Trace (freq 0.000001)
B6
2.3 合并trace(merge_traces)
遍历所有edge,不处理infrequent的边。然后如果发现edge两头from/to block不是在两个trace中间(也就是说,要么from block是trace最后一个block,要么to block是trace第一个block,两者必须有一个成立),那么合并两个trace。合并完成后线性控制流的trace此时会存在棱形控制流。
同样的例子,合并trace的时候遍历所有edge,它找到B2(from block)->B5(to block)这个edge,发现b2和b5的trace如下:
Trace (freq 1.000000)
B1 (L16) B2 B3 B4
Trace (freq 0.500000)
B5 B7
其中B5这个to block正好是第二个Trace的头部,所以可以合并,合并完成后trace如下:
Trace (freq 1.000000)
B1 (L16) B2 B5 B7 B3 B4
C2把第二个trace插在了第一个trace中间,出现了棱形。这一步处理完edge和trace如下:
===EDGES===
B1 --> B2 Freq: 1.000000 out:100% in:100% State: connected
B2 --> B3 Freq: 0.500000 out: 50% in:100% State: connected
B2 --> B5 Freq: 0.500000 out: 50% in:100% State: connected
B3 --> B4 Freq: 0.500000 out:100% in: 50% State: connected
B7 --> B4 Freq: 0.499999 out:100% in: 49% State: interior
B5 --> B7 Freq: 0.499999 out: 99% in:100% State: connected
B5 --> B6 Freq: 0.000001 out: 0% in:100% State: open infrequent
===TRACES==
Trace (freq 1.000000)
B1 (L16) B2 B5 B7 B3 B4
Trace (freq 0.000001)
B6
2.4 再次合并trace(merge_traces)
注意上面grow_trace也好,merge_trace也好,它们遍历edge处理完trace后都会将edge标记为connected。但是还是有些上面步骤没有处理的漏网之鱼,这一步会处理。它选择edge两端的trace,没有任何限制,也不管什么头尾,不管edge是不是infrequent,直接将第二个trace放入第一个trace,很宽松的处理。这一步处理完edge和trace如下:
===EDGES===
B1 --> B2 Freq: 1.000000 out:100% in:100% State: connected
B2 --> B3 Freq: 0.500000 out: 50% in:100% State: connected
B2 --> B5 Freq: 0.500000 out: 50% in:100% State: connected
B3 --> B4 Freq: 0.500000 out:100% in: 50% State: connected
B7 --> B4 Freq: 0.499999 out:100% in: 49% State: interior
B5 --> B7 Freq: 0.499999 out: 99% in:100% State: connected
B5 --> B6 Freq: 0.000001 out: 0% in:100% State: connected infrequent
===TRACES==
Trace (freq 1.000000)
B1 (L16) B2 B5 B7 B3 B4 B6
2.5 重排trace(reorder_traces)
到这一步,所有edge已经处理完毕,trace都已经准备完毕,此时会按照frequency对所有trace排序,然后确保fall-through分支是第二个successor block,即if的successor[0]是IfTrue,successor[1]是IfFalse。(其实这里的successor处理和下一步的修复控制流是重复的,我认为可以移除)
3. 修复控制流
这一步会遍历所有基本块,然后处理每个基本块尾部的分支跳转。
- 如果基本块只有一个后继基本块,那么会移除当前基本块尾部的goto。
- 如果基本块有两个后继,交换后继基本块,保证successor[0]是IfTrue,successor[1]是IfFalse。
- 如果基本块有两个以上的后继,to write
总结一下,这一步做的事情:频率高的路径涉及的bblock放前面,频率不高/uncommon_trap放最后面。