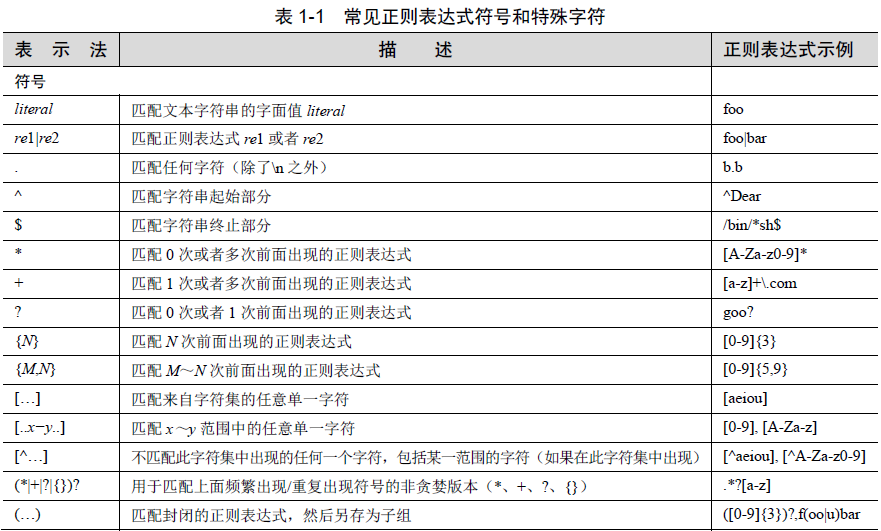
原子
原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子。常见的原子类型有:
a普通字符作为原子
b非打印字符作为原子
c通用字符作为原子
d原子表。


import re string="taoyunjiaoyu" #普通字符作为原子 pat="yum" rst=re.search(pat,string) print(rst) #非打印字符作为原子 # 换行符 制表符 string='""taoyunjiaoyu baidu' pat=" " rst=re.search(pat,string) print(rst) #通用字符作为原子 w字母、数字、下划线 W除字母、数字、下划线 d 十进制数字 D除十进制数字 s 空白字符 S除空白字符 string='''taoyunji8 7362387aoyubaidu'"' pat="wdsdd" rst=re.search(pat,string) print(rst) #原子表 string=‘’‘taoyunji87362387aoyubaidu’‘’ pat="tao[abd]" pat="tao[^abd]" rst=re.search(pat,string) print(rst)
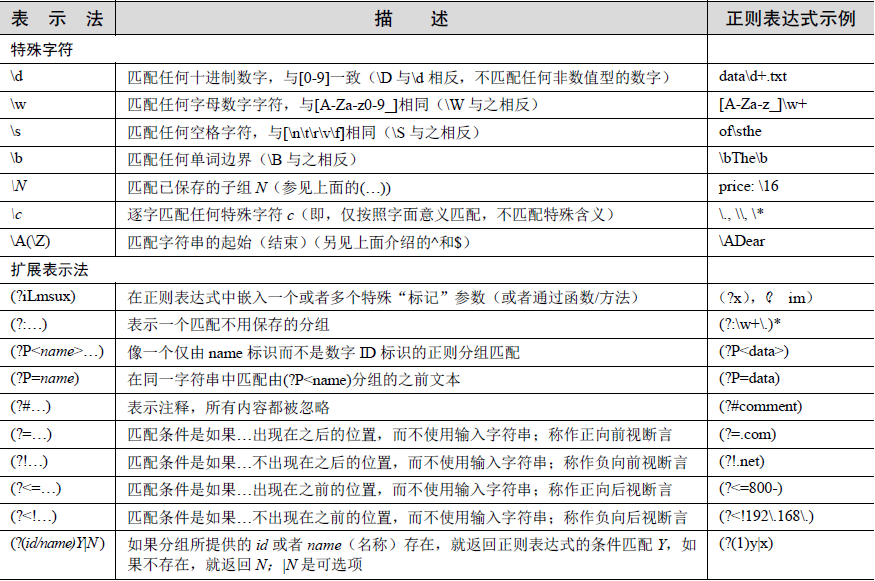
元字符
所谓的元字符,就是正则表达式中具有一些特殊含义的字符,比如重复N次前面的字符等。
. 除换行外任意一个字符 ^ 开始位置 $ 结束位置 * 01多次 ?01次 + 1多次 {n}恰好n次 {n,}至少n次 In,m}至少n,至多m次 | 模式选择符或 () 模式单元
模式修政符
所谓的模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能。
I匹配时忽略大小写
string="Python" pat="pyt" rst=re.search(pat,string,re.I) print(rst)
M多行匹配
L本地化识别匹配
U unicode
S让.匹配包括换行符
贪婪模式&懒惰模式
贪婪模式的核心点就是尽可能多的匹配,而懒惰模式的核心点就是尽可能少的匹配。
#贪婪模式与懒惰模式 string="povthonyhjskjsa" pat1="p.*y" #贪婪模式 pat2="p.*?y" #懒惰模式 rst=re.search(pat1,string,re.l) rst2=re.search(pat2,string,re.l) print(rst) print(rst2)
正则表达式函数
re.match()函数:从头开始匹配,匹配一个
re.search()函数:从任意位置开始匹配,匹配一个
全局匹配函数
全局匹配格式: re.compile(正则表达式).findall(数据)