举例:爬取带有“数据分析”职位的信息
需要材料:Python、
pip install requests
pip install lxml
pip install pandas
第一步:引用
import time import requests from lxml import etree import pandas as pd from pandas import DataFrame from pandas import Series
第二步:找到可打开的正确的url
url = 'http://search.51job.com/list/080200,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=’
第三步:向这个URL发出请求,文本编码修改为中文字符
head = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'}
s = requests.Session()
res = s.get(url,headers = head)
res.encoding = 'gbk'
root = etree.HTML(res.text)
第四步:在原网址查看所需字段的位置
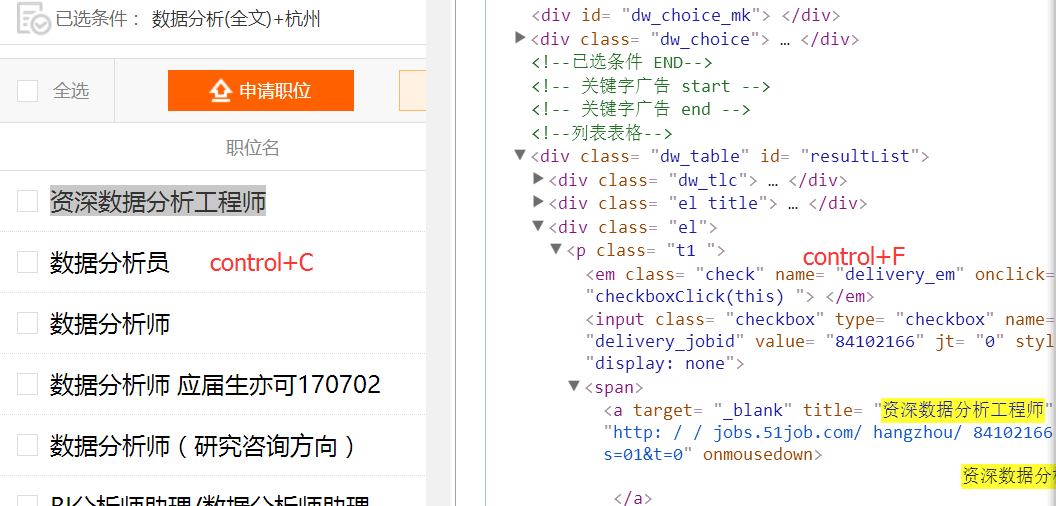
读取所需数据
position = root.xpath('//div[@class="el"]/p/span/a/@title')
company = root.xpath('//div[@class="el"]/span[@class="t2"]/a/@title')
place = root.xpath('//div[@class="el"]/span[@class="t3"]/text()')
salary = root.xpath('//div[@class="el"]/span[@class="t4"]/text()')
date = root.xpath('//div[@class="el"]/span[@class="t5"]/text()')
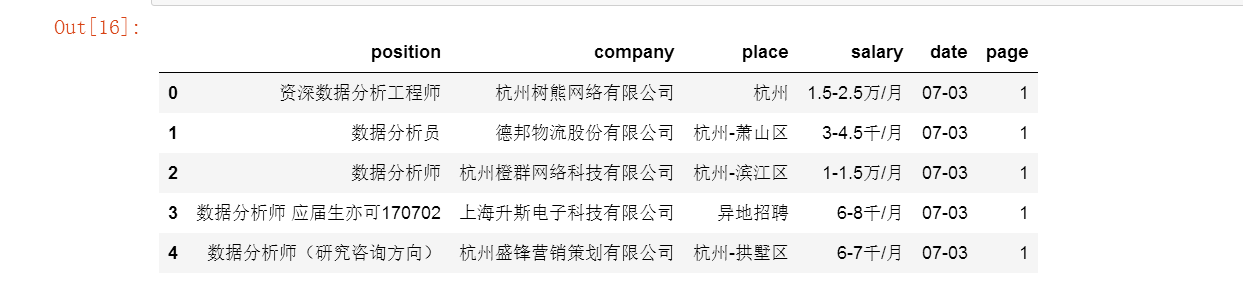
job = DataFrame([position,company,place,salary,date]).T
job.columns = ['position','company','place','salary','date']
job['page'] = 1
job.head()
测试运行
封装函数【要找到自增规律】

def Crawler_51job(df_origin,n): head = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'} s = requests.Session() for i in range(1,n+1): url = '
'http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=000000%2C00&district=000000&funtype=0000&industrytype=00&issuedate=9&providesalary=99&keyword=%E4%BF%A1%E7%94%A8%E7%AE%A1%E7%90%86&keywordtype=2&curr_page=' + str(i) + '&lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&list_type=0&fromType=14&dibiaoid=0&confirmdate=9'
' res = s.get(url,headers = head) res.encoding = 'gbk' root = etree.HTML(res.text) position = root.xpath('//div[@class="el"]/p/span/a/@title') company = root.xpath('//div[@class="el"]/span[@class="t2"]/a/@title') place = root.xpath('//div[@class="el"]/span[@class="t3"]/text()') salary = root.xpath('//div[@class="el"]/span[@class="t4"]/text()') date = root.xpath('//div[@class="el"]/span[@class="t5"]/text()') df = DataFrame([position,company,place,salary,date]).T df.columns = ['position','company','place','salary','date'] df = DataFrame([position,company,place,salary,date]).T df.columns = ['position','company','place','salary','date'] df['page'] = i time.sleep(2) df_origin = pd.concat([df_origin,df]) return(df_origin)
函数调用与数据输出
job = Crawler_51job(job,17)
job = Crawler_51job(job,17) job.to_csv('51job.csv',index = 0)
结果(excel坏了,用记事本查看一下)

这样就完成了一个爬虫小程序