视频转载自:https://www.bilibili.com/video/BV1E741167wz?p=1






栈的深度越深能够存储的线程的局部变量就越多
我们通过一个代码来进行验证下
public class Test { private int count = 0; public void testAdd() { count ++; testAdd(); } public void test() { try { testAdd(); } catch (Throwable e) { System.out.println("当前的count计数为:"+count); System.out.println("异常为"+e.toString()); } } public static void main(String[] args) { // TODO Auto-generated method stub new Test().test(); } }
注意这里是抛出运行时的的异常,在不断的递归调用过程中,就会出现栈异常的异常
我们来看下打印

我们可以使用xss来调整栈的深度和大小

这里我们将栈的深度大小设置为2m,我们可以看到count的深度会变大

第三课(java虚拟机调优03-jclasslib工具使用)
https://blog.csdn.net/u010570551/article/details/55684661
什么是局部变量表
在《java中的栈》中我们说到了一个栈帧至少需要包含局部变量表、操作数栈、帧数据区这三个部分。局部变量表是用于保存函数的参数以及局部变量的。顾名思义,局部变量表中的变量只在当前的函数的用中有效,当函数调用结束后,随着函数栈帧的销毁,局部变量表也会随之被销毁。
由于局部变量表在栈帧之中,因此,如果函数的参数和局部变量很多,会使得局部变量表膨胀,因此,每一次函数调用,其局部变量表就会占用更多的栈空间,最终导致函数的嵌套调用的次数减少。
代码来帮忙
public class TestStackDeepth { private static int length=0; public static void recursion(long a,long b,long c) { long e=1,f=2,g=3,h=4,i=5,k=6,q=7,x=8,y=9,z=11; length++; recursion(a, b, c); } public static void main(String[] args) { try { recursion(1l,2l,3l); } catch (Throwable ex) { System.out.println(length); } } }
使用jclasslib
打开jclasslib,选择对应的3中.class文件

加载好的jclasslib界面如下图所示

在jclasslib中可以看到recursion函数的最大局部变量是26个字。因为该函数一共13个参数和局部
变量,而且都是long类型。这里jvm的一个字是啥意思了
当时是希望把Class文件设计成可以(尽量)直接(解释)执行,而且假定运行环境是32位(且要求数据32位对齐)的。这样long或double放不进一个32位的存储单元,就只能用两个相邻的32位存储单元来存了。于是常量池项、局部变量区、操作数栈等在JVM规范里都规定要用相邻的两个slot来存long或double类型的值。
因为当年写JVM规范时,完全是按照当时的Sun JVM实现来写的。那个JVM很原始,执行引擎是个简单的字节码解释器。这个实现只适合在32位平台上运行。
为了让解释器实现得简单点,让局部变量的下标号能直接当作一个数组的下标,就让局部变量区和操作数栈的每个slot都实现为跟平台指针宽度一样(32位),所以很自然的,64位值(long和double)就需要占两个相邻的slot。

查看class文件的局部变量表的内容(下图中的局部变量表是指class文件的一个属性,而不是上文中所说的
java栈中的每个栈帧的局部变量表)
栈中的局部变量表的槽位是可以重复利用的,如果一个局部变量过了其作用域,那么在其作用域之后申明的新的局部变量很有可能会复用过期局部变量的槽位,从而达到节省资源的目的。
这里有一个关键的重点和亮点
public class IndexReuse { public static void method1() { int a=0; System.out.println(a); int b=0; } public static void method2() { { int a=0; System.out.println(a); } int b=0; } public static void main(String[] args) { } }
我们来看下jlibcalss的字节数目


可以看到method1占了2个字,因为method1中那个定义了两个变量a和b,每个站32位,对应就是2个字,method1中的局部变量表,由于a和b的作用范围都是整个函数,所以,b不用复用a的槽位
method2中的局部变量表,由于a只在{}中起作用,当作用域结束之后a的内存空间就被释放了,所以b在a之后,可以复用a的槽位,因此a和b的槽
从上面的例子我们可以体会到局部变量的声明位置会影响垃圾回收器对变量所占内存空间的回收,因此,在以后的程序设计中,我们应该尽可能的进行优化,从而提高性能。
第四课(java虚拟机调优04-虚拟机栈设置)
** 命令输入方式 :**
选择要运行的源文件,右键选择Run As -> Run Configurations -> Arguments
在 VM argument 输入框中输入要运行的命令
查看垃圾回收情况:
-verbose:gc //在控制台输出GC情况
-XX:+PrintGCDetails //在控制台输出详细的GC情况
-Xloggc: filepath //将GC日志输出到指定文件中
我们来看下面的这个代码

public class Test4 { public static void test(){ { byte[] b = new byte[6*1024*1024]; } System.gc(); System.out.println("helloword"); } public static void main(String[] args) { // TODO Auto-generated method stub test(); } }

我们可以看到上面掉头test方法的时候创建了一个6k的栈空间,进行垃圾回收的时候,这个栈空间基本没有被释放
我们可以参展上面的方法,定义一个变量method2中的局部变量表,由于a只在{}中起作用,当作用域结束之后a的内存空间就被释放了,所以b在a之后,可以复用a的槽位,因此a和b的槽
public class Test4 { public static void test(){ { byte[] b = new byte[6*1024*1024]; } int a = 9; System.gc(); System.out.println("helloword"); } public static void main(String[] args) { // TODO Auto-generated method stub test(); } }
查看运行的结果可以看到,就可以进行详细的垃圾回收了

写成下面的形式,局部变量在运行的过程中分配的空间是不能够被强制gc掉的,代码写成下面的形式,在test1运行的过程中是无法强制gc回收局部变量的空间的
public class Test4 { public static void test(){ byte[] b = new byte[6*1024*1024]; int a = 9; System.gc(); System.out.println("helloword"); } public static void main(String[] args) { // TODO Auto-generated method stub test(); } }
运行结果如下

接下来我们在来验证一个效果,如果作用域中定义了两个变量,如果要强制gc,必须要定义两个变量
public class Test4 { public static void test(){ { int a = 9; byte[] b = new byte[6*1024*1024]; } int c; System.gc(); System.out.println("helloword"); } public static void main(String[] args) { // TODO Auto-generated method stub test(); } }
在作用域中定义了两个变量a个byte【】b,在作用域外定义了一个变量c,这个c是可以复用变量a的空间的,但是byte[] b的内存空间在运行的时候是无法被复用的,我们来看下验证的效果

如果要复用byte[] b的内存空间,我们在代码外面在定义一个变量并且要给这个变量赋予初始值
public class Test4 { public static void test(){ { int a = 9; byte[] b = new byte[6*1024*1024]; } int c; int d = 0; System.gc(); System.out.println("helloword"); } public static void main(String[] args) { // TODO Auto-generated method stub test(); } }
我们再来看下效果

上面的重点本质就是从上面的例子我们可以体会到局部变量的声明位置会影响垃圾回收器对变量所占内存空间的回收,因此,在以后的程序设计中,我们应该尽可能的进行优化,从而提高性能。

我们可以通过下面的程序代码来进行验证
public class Test5 { public static void main(String[] args) { // TODO Auto-generated method stub Vector v =new Vector(); for(int i =0 ;i<=10;i++){ //每次产生1M的内存空间 byte[] b = new byte[1024*1024]; v.add(b); System.out.println("i是:"+i); } //获取当前系统能够获得最大内存空间 long maxMemory = Runtime.getRuntime().maxMemory()/1024/1024; System.out.println("当前系统能够使用的最大内存空间是:"+maxMemory+"M"); } }
上面的代码中,每次产生一个1M的变量添加到集合中,如果我们设置程序的栈大小为5M,上面运行10次,就会产生10M的内存空间,但是因为我们给程序设置了最大的堆内存空间为5M,就会产生堆空间溢出,我们来看下程序的代码

我们来看下程序运行的结果

如果我们把内存设置为50M,我们来看下运行的效果



1.GC的分类
JVM在进行GC时,可能针对三个区域进行垃圾回收分别是新生代、老年代、方法区,大部分时候回收的都是新生代。GC类型主要有以下四种类型。
- 新生代收集(Minor GC/Young GC):只针对新生代的垃圾收集。具体点的是Eden区满时触发GC。 Survivor满不会触发Minor GC 。
- 老年代收集(Major GC/Old GC):只针对 老年代的垃圾收集。 目前,只有CMS收集器会有单独收集老年代的行为。
- 混合收集(Mixed GC):指目标是收集整个新生代以及部分老年代的垃圾收集。 目前只有G1收集器会有这种行为。
- 整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集。
2.1MinorGC
当年轻代(Eden区)满时就会触发 Minor GC,这里的年轻代满指的是 Eden区满。Survivor 满不会触发 Minor GC 。对于大部分应用程序,Minor GC 操作时应用程序停顿导致的延迟都是可以忽略不计的。大部分 Eden 区中的对象都能被认为是垃圾,永远也不会被复制到 Survivor 区或者老年代空间。如果正好相反,Eden 区大部分新生对象不符合 GC 条件,Minor GC 执行时暂停的时间将会长很多。
2.2MajorGC
当老年代满时会触发MajorGC,只有CMS收集器会有单独收集老年代的行为,其他收集器均无此行为。而针对新生代的MinorGC,各个收集器均支持。总之,单独发生收集行为的只有新生代,除了CMS收集器,都不支持单独回收老年代。
2.3FullGC
FullGC是针对新生代,老年代和方法区(元空间)的垃圾收集。FullGC产生的条件:
(1)调用System.gc时,系统建议执行Full GC,但是不一定会执行 。
(2)老年代空间不足。
(3)方法区空间不足,类卸载(类卸载三个条件)。
(4)通过 Minor GC 后进入老年代的空间大于老年代的可用内存
(5)内存空间担保。
虚拟机在执行MinorGC和FullGC的时候会消耗时间,当高并发的情况下可能会引起系统响应时间慢,所以应用程序要尽量金山虚拟机的GC操作
接下来我们通过一个应用程序来验证整个效果
import java.util.Vector; public class Test6 { public static void main(String[] args) { // TODO Auto-generated method stub Vector v =new Vector(); for(int i =0 ;i<10;i++){ //每次产生1M的内存空间 byte[] b = new byte[1024*1024]; v.add(b); //模拟操作系统的gc,当i=3的时候,释放内存空间,这个时间就会发送gc操作 if(v.size()==3){ v.clear(); } } //获取当前系统能够获得最大内存空间 long maxMemory = Runtime.getRuntime().maxMemory()/1024/1024; System.out.println("当前系统能够使用的最大内存空间是:"+maxMemory+"M"); } }
我们设置的配置如下,我们将最小堆设置为2M

我们来看下整个效果

我们可以看出出现了三次MinorGC和一次FUllGC,每次gc都会消耗jvm的执行时间,一般情况下出现FullGC说明整个应用程序的内存已经严重不足了,如果一个系统生产上面不断的出现FullGC,那么就要调整Xmx的大小,我们将-Xmx设置为100M,就不会在出现FullGC了

我们来看下效果,这个时候已经不存在FullGC,但是还是会存在MinorGC,一般情况下出现MinorGC,一般是Xms设置太小引起的。这个时候可以将-Xms调整稍微大一点,生产上面一般将-Xms设置和Xmx设置一样

但是还是会存在MinorGC,这个时候可以将-Xms调整稍微大一点,生产上面一般将-Xms设置和Xmx设置一样,我们来调整下

我们来查看运行的效果,这个时候已经看不到minorGC了

第七课(java虚拟机调优07-新生代及持久代设置)



我们通过一个案例来设置方法区也就是我们的持久化区
String.intern()使用原理
String.intern()是一个Native方法,底层调用C++的 StringTable::intern方法实现。当通过语句str.intern()调用intern()方法后,JVM 就会在当前类的常量池中查找是否存在与str等值的String,若存在则直接返回常量池中相应Strnig的引用;若不存在,则会在常量池中创建一个等值的String,然后返回这个String在常量池中的引用
import java.util.Vector; public class Test7 { public static void main(String[] args) { // TODO Auto-generated method stub Vector v =new Vector(); for(int i =0 ;i<Integer.MAX_VALUE;i++){ String s = String.valueOf(i).intern(); } } }
上面的这个代码就会不断在方法区的常量池中添加常量,导致常量池的大小不断增加,我们先设置一个常量的大小如下,我们来看下整个代码的运行效果


上图的运行结果验证了垃圾回收器是可以回收方法区的内存空间的,接下来我们设置方法区的内存大小,我们在来看整个程序的运行效果


第十课(java虚拟机调优10-G1回收器使用)
G1收集器将堆进行分区,将内存分为不同的区域,每次回收的时候,只回收其中的几个区域,这样可以有效的来控制垃圾回收产生的一次停顿时间。
如下列表为 G1 GC垃圾收集器常用配置参数:
可选项及默认值 描述
| -XX:+UseG1GC | 采用 Garbage First (G1) 收集器 |
| -XX:MaxGCPauseMillis=n |
设置最大GC 暂停时间。这是一个大概值,JVM 会尽可能的满足此值 |
我们通过代码来验证下
import java.util.HashMap; import java.util.Vector; public class Test9 { static HashMap map = new HashMap(); public static class MyThread extends Thread { @Override public void run() { // TODO Auto-generated method stub while(true){ if(map.size()*512/1024/1024>=400){ map.clear(); System.out.println("清除内存"); } byte[] b1; for(int j =0 ;j<100;j++) { b1=new byte[512]; map.put(System.nanoTime(), b1); } } } } public static class PrintThread extends Thread { public static final long beginTime = System.currentTimeMillis(); @Override public void run() { while(true){ long t = System.currentTimeMillis(); System.out.println(t-beginTime); try { Thread.sleep(100); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } public static void main(String[] args) { // TODO Auto-generated method stub MyThread t = new MyThread(); t.start(); PrintThread t1 = new PrintThread(); t1.start(); } }
我们来看下打印结果
5
110
992
1122
1222
1777
2027
2245
2346
清除内存
2473
2659
2827
3415
3524
3664
4554
清除内存
4749
4958
PrintThread线程每运行2秒左右,MyThread的内存就满了就会清理一次内存。
我们使用G1垃圾回收器-Xmx512M -Xms512M -XX:+UseG1GC -XX:MaxGCPauseMillis=10

我们来看下程序运行的结果
0
122
223
324
471
572
689
789
889
989
1089
1189
1289
1398
1507
1632
1744
1913
2013
2113
2213
2313
2423
2555
2671
2771
2881
3005
3105
3210
3310
3410
3510
3610
3710
3812
3941
清除内存
4915
5285
5385
5509
5620
5725
5866
5968
6069
6258
6358
6458
6575
6675
6775
6875
6975
7075
7203
7304
7406
PrintThread线程每运行4秒左右,MyThread的内存才满了就会清理一次内存。说明G1垃圾回收器的性能更好,更能有效的清除无效内存,保证程序的正常运行,减少线程停顿时间
第十一课(java虚拟机调优11-常用的虚拟机调优方法01)

我们通过一个程序来验证下,我们产生四个对象,每个对象都是1M的空间
import java.util.HashMap; import java.util.Vector; public class Test11 { public static void main(String[] args) { // TODO Auto-generated method stub byte[] b1,b2,b3,b4; //产生四个对象。每个对象多少1M b1= new byte[1024*1024]; b2= new byte[1024*1024]; b3= new byte[1024*1024]; b4= new byte[1024*1024]; } }
第一种场景我们让新生代的大小只有1M,那么上面产生的4个对象都会分配在老年代
-Xmx20M -Xms20M -Xmn1M -XX:+PrintGCDetails
我们来看下运行的结果如下

新生代一共分配了只有1M,使用了749k,老年代一共18M,使用了4M,说明产生了4个对象都分配在了老年代,生产上
我们要尽量让产生的对象对分配在新生代,尽量建设gc,一般情况下新生代都是堆大小的三分之一,这里设置为6M,对象都分配在了新生代
我们-Xmx20M -Xms20M -Xmn6M -XX:+PrintGCDetails
我们再来看下运行的效果

优化2:
产生的大对象直接分配在老年代,如果大对象分配在新生代,因为大对象已经占用了太多新生代空间,后面产生的新生代对象只能分配在老年代,就会频繁导致gc操作


什么时候发生内存回收
大多数情况下,对象在新生代Eden区分配,当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor GC。同理,当老年代没有足够的空间时也会发起一次Full GC/Major GC
现代虚拟机把新生代分为三个区域,一个Eden区域,两个Survivor区域,Eden区域与Survivor区域的比例大小是8:1,虚拟机在Minor GC时在新生代采用复制算法,将存活对象复制到一个Survivor上面,如果Survivor空间不够用时,就需要老年代进行分配担保。
大对象直接进入老年代
大对象是指需要大量连续内存空间的对象,例如很长的字符串以及数组。
虚拟机设置了一个-XX:PretenureSizeThreshold参数,令大于这个设置的对象直接在老年代分配。目的就是为了防止大对象在Eden空间和Survivor空间来回大量复制。
长期存活的对象进入老年代
虚拟机给每个对象定义了一个对象年龄(Age)计数器,如果对象在Eden区出生并经过第一次Mintor GC后仍然存活,并且能被Survivor接纳,并被移动到Survivor空间上,那么该对象年龄将被设置为1。对象在Survivor区中每熬过一次Minor GC,年龄就加一,当他的年龄增加到一定程度,就会被移动到老年代(年龄值默认为15)。对象晋升老年代的阈值可以通过-XX:MaxTenuringThreshold设置。
新生代收集器:Serial、ParNew、Parallel Scavenge;
老年代收集器:Serial Old、Parallel Old、CMS;
整堆收集器:G1;

3.Minor GC和Full GC的区别
3.1Minor GC
又称新生代GC,指发生在新生代的垃圾收集动作;
因为Java对象大多是朝生夕灭,所以Minor GC非常频繁,一般回收速度也比较快;
3.2Full GC
又称Major GC或老年代GC,指发生在老年代的GC;
出现Full GC经常会伴随至少一次的Minor GC(不是绝对,Parallel Sacvenge收集器就可以选择设置Major GC策略);
Major GC速度一般比Minor GC慢10倍以上;
jdk1.8 默认垃圾收集器为:Parallel Scavenge(新生代)+ Parallel Old(老年代)
我们来看下面的一个代码,我们产生一个5M的大对象,我们默认来看大对象分配在那里
public class PretenureSizeThreshold { private static final int _1MB = 1024 * 1024; public static void testPretenureSizeThreshold(){ byte[] allocation; allocation = new byte[5 * _1MB]; } public static void main(String[] args) { PretenureSizeThreshold.testPretenureSizeThreshold(); } }
我们使用下面的属性-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=1048576
给新生代分配10M的大小,新生代设置eden区和survivor区的比例为8:1:1,-XX:PretenureSizeThreshold=—设置最大对象的阈值为1m,当大对象超过
1M就要分配到老年代中

我们来看下打印
PSYoungGen total 9216K, used 6269K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
PSYoungGen代表默认用的Parallel Scavenge回收器新生代,新生代的大小是10M,新生代一共使用了6M,说明我们分配的5M的对象都分配在了新生代上
eden space 8192K, 76% used [0x00000000ff600000,0x00000000ffc1f488,0x00000000ffe00000)
from space 1024K, 0% used [0x00000000fff00000,0x00000000fff00000,0x0000000100000000)
to space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
新一代的10M对象,一个Eden区域,两个Survivor区域,Eden区域是8M,两个两个Survivor区域分表是1M,eden使用新生代使用了76%,说明对象产生的5M都使用了eden区域
ParOldGen total 10240K, used 0K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
老年代 Parallel Old(老年代)分配了10M,没有使用
Metaspace就是所谓的方法区就是用来存储类的类的元数据存储类的一些基本信息的
Java8内存模型—永久代(PermGen)和元空间(Metaspace):转载自博客https://www.cnblogs.com/paddix/p/5309550.html
根据 JVM 规范,JVM 内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分。

1、虚拟机栈:每个线程有一个私有的栈,随着线程的创建而创建。栈里面存着的是一种叫“栈帧”的东西,每个方法会创建一个栈帧,栈帧中存放了局部变量表(基本数据类型和对象引用)、操作数栈、方法出口等信息。栈的大小可以固定也可以动态扩展。当栈调用深度大于JVM所允许的范围,会抛出StackOverflowError的错误,不过这个深度范围不是一个恒定的值,我们通过下面这段程序可以测试一下这个结果:
package com.paddx.test.memory; public class StackErrorMock { private static int index = 1; public void call(){ index++; call(); } public static void main(String[] args) { StackErrorMock mock = new StackErrorMock(); try { mock.call(); }catch (Throwable e){ System.out.println("Stack deep : "+index); e.printStackTrace(); } } }
运行三次,可以看出每次栈的深度都是不一样的,输出结果如下。

至于红色框里的值是怎么出来的,就需要深入到 JVM 的源码中才能探讨,这里不作详细阐述。
虚拟机栈除了上述错误外,还有另一种错误,那就是当申请不到空间时,会抛出 OutOfMemoryError。这里有一个小细节需要注意,catch 捕获的是 Throwable,而不是 Exception。因为 StackOverflowError 和 OutOfMemoryError 都不属于 Exception 的子类,都是运行时的异常。运行时的异常如果不捕获处理程序直接进程退出,如果捕获了就等待程序执行完成才退出
2、本地方法栈:
这部分主要与虚拟机用到的 Native 方法相关,一般情况下, Java 应用程序员并不需要关心这部分的内容。
3、PC 寄存器:
PC 寄存器,也叫程序计数器。JVM支持多个线程同时运行,每个线程都有自己的程序计数器。倘若当前执行的是 JVM 的方法,则该寄存器中保存当前执行指令的地址;倘若执行的是native 方法,则PC寄存器中为空。
4、堆
堆内存是 JVM 所有线程共享的部分,在虚拟机启动的时候就已经创建。所有的对象和数组都在堆上进行分配。这部分空间可通过 GC 进行回收。当申请不到空间时会抛出 OutOfMemoryError。下面我们简单的模拟一个堆内存溢出的情况:
package com.paddx.test.memory; import java.util.ArrayList; import java.util.List; public class HeapOomMock { public static void main(String[] args) { List<byte[]> list = new ArrayList<byte[]>(); int i = 0; boolean flag = true; while (flag){ try { i++; list.add(new byte[1024 * 1024]);//每次增加一个1M大小的数组对象 }catch (Throwable e){ e.printStackTrace(); flag = false; System.out.println("count="+i);//记录运行的次数 } } } }

5、方法区:
方法区也是所有线程共享。主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。 关于方法区内存溢出的问题会在下文中详细探讨。是用于存储类数据(如静态变量,字节码等)的存储区,这个区域主要存放被加载的class信息
二、PermGen(永久代)
绝大部分 Java 程序员应该都见过 "java.lang.OutOfMemoryError: PermGen space "这个异常。这里的 “PermGen space”其实指的就是方法区。不过方法区和“PermGen space”又有着本质的区别。前者是 JVM 的规范,而后者则是 JVM 规范的一种实现,并且只有 HotSpot 才有 “PermGen space”,而对于其他类型的虚拟机,如 JRockit(Oracle)、J9(IBM) 并没有“PermGen space”。由于方法区主要存储类的相关信息,所以对于动态生成类的情况比较容易出现永久代的内存溢出。最典型的场景就是,在 jsp 页面比较多的情况,容易出现永久代内存溢出。我们现在通过动态生成类来模拟 “PermGen space”的内存溢出:
package com.paddx.test.memory; public class Test { }
import java.io.File; import java.net.URL; import java.net.URLClassLoader; import java.util.ArrayList; import java.util.List; public class PermGenOomMock{ public static void main(String[] args) { URL url = null; List<ClassLoader> classLoaderList = new ArrayList<ClassLoader>(); try { url = new File("/tmp").toURI().toURL(); URL[] urls = {url}; while (true){ ClassLoader loader = new URLClassLoader(urls); classLoaderList.add(loader); loader.loadClass("com.paddx.test.memory.Test"); } } catch (Exception e) { e.printStackTrace(); } } }
运行结果如下:

本例中使用的 JDK 版本是 1.7,指定的 PermGen 区的大小为 8M。通过每次生成不同URLClassLoader对象来加载Test类,从而生成不同的类对象,这样就能看到我们熟悉的 "java.lang.OutOfMemoryError: PermGen space " 异常了。这里之所以采用 JDK 1.7,是因为在 JDK 1.8 中, HotSpot 已经没有 “PermGen space”这个区间了,取而代之是一个叫做 Metaspace(元空间) 的东西。下面我们就来看看 Metaspace 与 PermGen space 的区别。当加载超过3万个类之后,PermGen被耗尽
三、Metaspace(元空间)
其实,移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。我们可以通过一段程序来比较 JDK 1.6 与 JDK 1.7及 JDK 1.8 的区别,以字符串常量为例:
package com.paddx.test.memory;import java.util.ArrayList;import java.util.List;public class StringOomMock { static String base = "string"; public static void main(String[] args) { List<String> list = new ArrayList<String>(); for (int i=0;i< Integer.MAX_VALUE;i++){ String str = base + base; base = str; list.add(str.intern()); } }}这段程序以2的指数级不断的生成新的字符串,这样可以比较快速的消耗内存。我们通过 JDK 1.6、JDK 1.7 和 JDK 1.8 分别运行:
JDK 1.6 的运行结果:

JDK 1.7的运行结果:

JDK 1.8的运行结果:
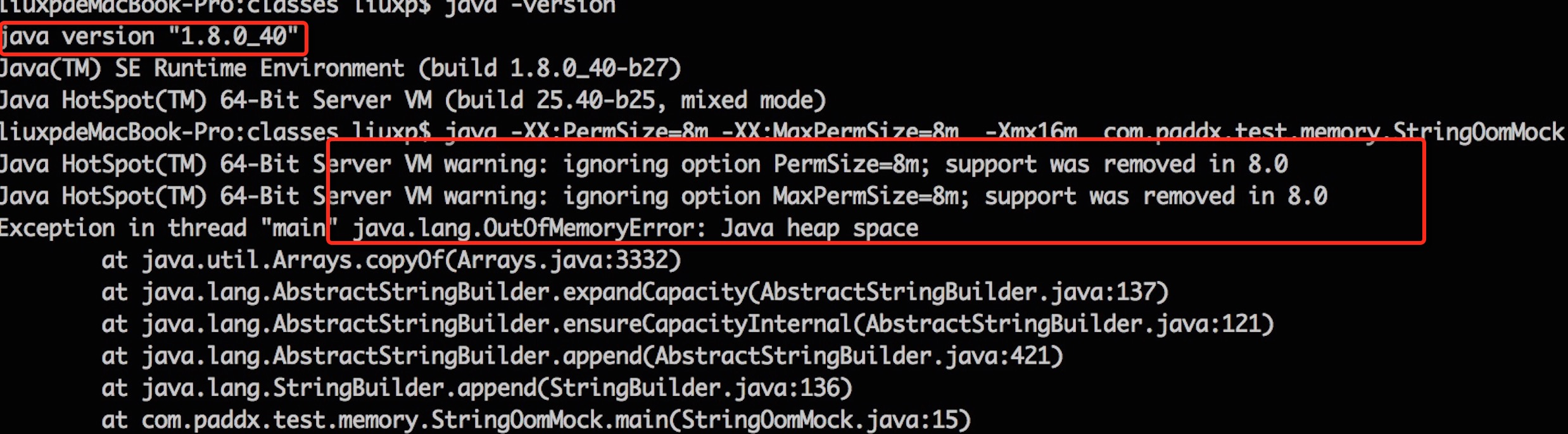
从上述结果可以看出,JDK 1.6下,会出现“PermGen Space”的内存溢出,而在 JDK 1.7和 JDK 1.8 中,会出现堆内存溢出,并且 JDK 1.8中 PermSize 和 MaxPermGen 已经无效。因此,可以大致验证 JDK 1.7 和 1.8 将字符串常量由永久代转移到堆中,并且 JDK 1.8 中已经不存在永久代的结论。现在我们看看元空间到底是一个什么东西?
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
在Java 8中,PermGen方法区域替换为MetaSpace。他们已将permGem移至本机OS的独立内存中,称为MetaSpace。默认情况下,它可以自动增加其大小。在MetaSpace中,类可以在JVM的生命周期内进行加载和卸载。
| 序号 | 键 | 彼尔姆 | 元空间 |
|---|---|---|---|
| 1 | 基本的 | PermGen是用于存储类数据(如静态变量,字节码等)的存储区 | 在Java 8中,PermGen方法区域已替换为MetaSpace |
| 2 | 默认内存分配 | 默认情况下,为PermGen分配了64 Mb | 默认情况下,它可以自动增加其大小 |
| 3 | 调优内存标志 | 可以使用-XXMaxPermSize对其进行调整。 | 我们可以通过-XX:MaxMetaspaceSize限制内存的上限 |
| 4 | 记忆区 | 这是一个特殊的堆空间。 | 从Java 8开始,它现在是本机OS中的独立内存区域 |
直接使用当前机器的物理内存,不再使用虚拟机的堆内存
执行上面的代码,我们可以看到物理内存不断上涨

元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与 GC 相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
现在我们在 JDK 8下重新运行一下代码段 4,不过这次不再指定 PermSize 和 MaxPermSize。而是指定 MetaSpaceSize 和 MaxMetaSpaceSize的大小。输出结果如下:

-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m
PrintThread