跨集群搜索(cross-cluster search)使您可以针对一个或多个远程集群运行单个搜索请求。 例如,您可以使用跨集群搜索来筛选和分析存储在不同数据中心的集群中的日志数据。

如上面所述,当我们的client向集群cluster_1发送请求时,它可以搜索自己本身的集群,同时也可以向另外的两个集群cluster_2及cluster_3发送请求。最后的结果由cluster_1返回给客户端。

目前支持的APIs:
- Search
- Multi search
- Search template
- Multi search template
跨集群搜索例子
注册remote cluster
要执行跨集群搜索,必须至少配置一个远程集群。在集群设置中配置了远程群集
- 使用cluster.remote属性
- 种子(seeds)是远程集群中的节点列表,用于在注册远程集群时检索集群状态
我们在windows环境上模拟启动三个es集群

三个es节点的配置依次如下所示
第一个集群

第二个集群

第三个集群

要执行跨集群搜索, 必须至少配置一个远程集群. 在每一个集群中都需要如下配置:
1, 使用 cluster.remote 属性
2, 种子 (seeds) 是远程集群中的节点列表, 用于在注册远程集群时检索集群状态
1、注意是每一个集群中需要进行设置,我们分部部署三个kibana,每个kibana分别连接一个集群,
2、需要保证各个集群已经正常启动成功
我们在kibana上面执行下面的命令
PUT _cluster/settings { "persistent": { "search": { "remote": { "cluster_one": { "seeds": [ "127.0.0.1:9300" ] }, "cluster_two": { "seeds": [ "127.0.0.1:9301" ] }, "cluster_three": { "seeds": [ "127.0.0.1:9302" ] } } } } }
执行成功之后,返回值如下
{ "acknowledged": true, "persistent": { "search": { "remote": { "cluster_three": { "seeds": [ "127.0.0.1:9302" ] }, "cluster_two": { "seeds": [ "127.0.0.1:9301" ] }, "cluster_one": { "seeds": [ "127.0.0.1:9300" ] } } } }, "transient": {} }
我们可以使用 GET _remote/info 查看 CSS 的连接状态, 如下:
{ "cluster_three": { "seeds": [ "127.0.0.1:9302" ], "http_addresses": [ "192.168.1.4:9202" ], "connected": true, "num_nodes_connected": 1, "max_connections_per_cluster": 3, "initial_connect_timeout": "30s", "skip_unavailable": false }, "cluster_one": { "seeds": [ "127.0.0.1:9300" ], "http_addresses": [ "192.168.1.4:9200" ], "connected": true, "num_nodes_connected": 1, "max_connections_per_cluster": 3, "initial_connect_timeout": "30s", "skip_unavailable": false }, "cluster_two": { "seeds": [ "127.0.0.1:9301" ], "http_addresses": [ "192.168.1.4:9201" ], "connected": true, "num_nodes_connected": 1, "max_connections_per_cluster": 3, "initial_connect_timeout": "30s", "skip_unavailable": false } }
这里一定要注意有几个集群就执行几次此命令. 那么这样, 一个 CSS 集群就这样配置完成了.以下cluster update settings API请求添加了三个远程集群:cluster_one,cluster_two和cluster_three。这里名字可以不和es的配置文件中的集群名称一样,cluster_one和cluster_two表示与每个群集连接的任意群集别名
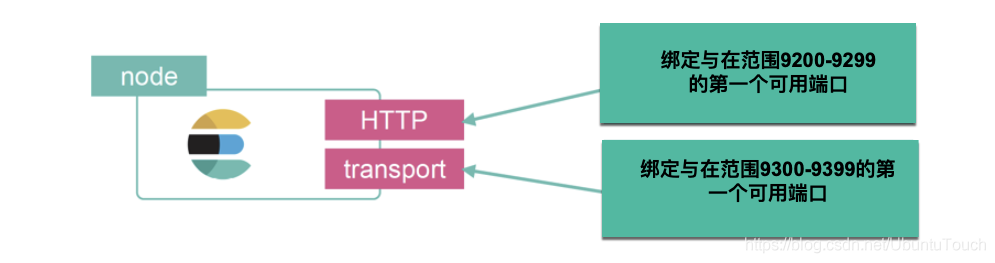
在上面可能有很多人感到疑问:为啥我们还需要配置端口地址 9300 及 9301?事实上,Elasticsearch 中有两种重要的网络通信机制需要了解:
- HTTP:用于 HTTP 通信绑定的地址和端口,这是 Elasticsearch REST API 公开的方式
- transport:用于集群内节点之间的内部通信
删除远程配置的api配置命令
PUT _cluster/settings { "persistent": { "search": { "remote": { "cluster_two": { "skip_unavailable": null, "seeds": null }, "cluster_three": { "skip_unavailable": null, "seeds": null } } } } }
接下来我们来进行验证
我们设置
cluster_two和cluster_three之间可以相互通信
我们在
cluster_two和cluster_three上面分表执行下面的命令
PUT _cluster/settings { "persistent": { "search": { "remote": { "cluster_two": { "skip_unavailable": true, "seeds": [ "127.0.0.1:9301" ] }, "cluster_three": { "skip_unavailable": true, "seeds": [ "127.0.0.1:9302" ] } } } } }
我们在集群3上面创建下面的索引
PUT sms-logs-index/sms-logs-type/20 { "corpName":"汗牛养车", "createDate":"2020-01-22", "fee":3, "ipAddr":"10.123.98.1", "longCode":106900000009, "mobile":18780278756, "operatorId":1, "province":"北京", "replyTotal":10, "sendDate":"2020-01-22", "smsContent":"【途虎养车】亲爱的旧居茫水东降级就", "state":0 }
我们在集群2上传创建一个book的索
PUT /book/emp/1 {"name":"小黑","age":23,"bir":"2012-12-12","content":"为开发团队选择一款优秀的MVC框架是件难事儿,在众多可行的方案中决择需要很高的经验和水平","address":"北京"}
接下来我们登录到集群3的机器上面访问集群2的索引
GET /cluster_two:book/_search
这里查询的结构为集群名称加上索引
返回的结果如下

我们在集群三上面精确查询,下面这个格式可以不

我们发现这种查询会保存,es远程查询暂时只支持下面的几种方式



也可以写成下面的方式远程查询cluster_two集群上面索引名称以boo开头的数据
GET /cluster_two:boo*/_search
同理在集群2上面远程查sms-logs-index的索引类似
接下来我要查询多个索引如何查询了,使用下面的命令,我们在集群3上面使用下面的命令
GET /cluster_two:book,cluster_three:sms-logs-index/_search
查询结果如下
{ "took": 32, "timed_out": false, "_shards": { "total": 10, "successful": 10, "skipped": 0, "failed": 0 }, "_clusters": { "total": 2, "successful": 2, "skipped": 0 }, "hits": { "total": 3, "max_score": 1, "hits": [ { "_index": "cluster_three:sms-logs-index", "_type": "sms-logs-type", "_id": "2", "_score": 1, "_source": { "corpName": "汗牛养车", "createDate": "2020-01-22", "fee": 3, "ipAddr": "10.123.98.1", "longCode": 106900000009, "mobile": 18780278756, "operatorId": 1, "province": "北京", "replyTotal": 10, "sendDate": "2020-01-22", "smsContent": "【途虎养车】亲爱的旧居茫水东降级就", "state": 0 } }, { "_index": "cluster_three:sms-logs-index", "_type": "sms-logs-type", "_id": "20", "_score": 1, "_source": { "corpName": "汗牛养车", "createDate": "2020-01-22", "fee": 3, "ipAddr": "10.123.98.1", "longCode": 106900000009, "mobile": 18780278756, "operatorId": 1, "province": "北京", "replyTotal": 10, "sendDate": "2020-01-22", "smsContent": "【途虎养车】亲爱的旧居茫水东降级就", "state": 0 } }, { "_index": "cluster_two:book", "_type": "emp", "_id": "1", "_score": 1, "_source": { "name": "小黑", "age": 23, "bir": "2012-12-12", "content": "为开发团队选择一款优秀的MVC框架是件难事儿,在众多可行的方案中决择需要很高的经验和水平", "address": "北京" } } ] } }
从上面的结果可以,es把两个集群下面查询到的索引的结果做了聚合返回给了客户端
下面还有一个需求,我要遍历所有集群下面的全部book的索引,集群名称可以用下面的*代替
GET /*:book/_search
返回的结果如下
{ "took": 20, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "_clusters": { "total": 2, "successful": 1, "skipped": 1 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "cluster_two:book", "_type": "emp", "_id": "1", "_score": 1, "_source": { "name": "小黑", "age": 23, "bir": "2012-12-12", "content": "为开发团队选择一款优秀的MVC框架是件难事儿,在众多可行的方案中决择需要很高的经验和水平", "address": "北京" } } ] } }
下面的需求
GET /*:book,*:sms-logs-index/_search查询所用集群中的book索引和索引集群中的sms-logs-index
我们来看看结果,我们发现结果为空

所以对于远程查询,我们最好事先知道哪些索引在哪些集群上面,按照这种方式来进行查询
GET /*:book/_search
这种查询在生产上我们可以使用到,一个系统同时部署在两个es集群中,福州es集群和上海es集群中,两个集群中的索引的名称都是一样的,我们就可以使用上面的两种方式进行聚合查询
上面我们的列子中,一个集群都是单机的,如果集群下面存在多个机器,我们要采用下面的方式

第二,我们在kibana上面也可以远程查询
列如我们在集群3上面查询集群2上面的索引
我们输入*:就会自动提示

es跨集群官网的地址为:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cross-cluster-search.html
属性2
Skip unavailable clustersedit By default, a cross-cluster search returns an error if any cluster in the request is unavailable. To skip an unavailable cluster during a cross-cluster search, set the skip_unavailable cluster setting to true. The following cluster update settings API request changes cluster_two's skip_unavailable setting to true. PUT _cluster/settings { "persistent": { "cluster.remote.cluster_two.skip_unavailable": true } } Copy as cURL View in Console If cluster_two is disconnected or unavailable during a cross-cluster search, Elasticsearch won’t include matching documents from that cluster in the final results.
上面还有一个点:在设置远程连接的时候
对于7以上的版本设置的时候

我们上面演示的是6.2.4版本的

这里要注意下