更新: 2021-05-13
convert int to am pm
https://stackoverflow.com/questions/38329899/convert-integer-value-into-hour-value-am-pm-in-sql-server/38330108#38330108
FORMAT(DATEADD(hh,15,'00:00:00'),'h:mm tt')
更新: 2021-01-06
OLAP on-Line analytical processing
OLTP on-line transaction processing
ACID (atomicity 原子性, consistency 一致性, isolation 隔离性 and durability 持久性)
RDBMS (relational database management system)
microsoft Azure Cosmos DB 视乎是微软的 NoSql 或 NewSql 来的
PostgreSQL - 因为 mysql 被 oracle 收购后就越来越火了
更新: 2020-11-16
generate change script
option -> designer -> auto generate change script
refer:
https://dirkstrauss.com/easily-generate-table-change-scripts/#:~:text=In%20SQL%20Server%20Management%20Studio%2C%20select%20the%20Options%20sub%2Dmenu,option%20and%20click%20on%20OK.
https://www.sqlshack.com/difference-between-unique-indexes-and-unique-constraints-in-sql-server/
更新: 2020-07-14
新版本的 .bak 去旧版本
比如用 2019 做一个 backup, 然后想 restore 到 2017 是不可以的.
refer :
https://www.mssqltips.com/sqlservertip/2810/how-to-migrate-a-sql-server-database-to-a-lower-version/
解决方法是用 script, 要记得 set 下面这些
set Script for Server Version to SQL Server 20xx (去你要的版本)
under the Table/View Options, set Script Triggers, Script Indexes and Script Primary Keys to True
and set Types of data to script to Schema and Data (默认是不包括 data 的)
好了以后打开这个 file
把 path 换掉. 然后 run 就可以了.
如果 data 太多, 做出来的 file 就会太大. 那么就只能先做一个 structure, 然后再想办法一个一个 table 的资料搬进去. (这个工程就大多了)
更新: 2020-07-11
sql select 的时候如果没有指定 orderby, 那么它是无法预测的. 并不是 order by Id asc 也不是依据 clustered. 我猜是看它有没有走索引之类的瓜.
总之如果你需要次序,那么就一定要放 orderby
更新: 2020-06-10
sql server = char(13) = char(10)
有时候我们想存 string list, 一般上用逗号做分隔符,但是有时候呢,用户又需要写逗号
比如 google map 的 link 就有逗号.
为了避开这个问题,可以考虑用 作为分隔符.
依赖是 display 的时候可以配 preline display, 二来也比逗号难撞.
缺点就是在操作数据库的时候不是很方便啦, 但是我觉得 ok 啦
更新: 2019-12-13
sql server 会自动 trim end 哦
'Stooges' 和 'Stooges ' 是一样的,不管是查询还是 unique
这个是 sql 规范来的.
但是也有例外哦, 在 like 的时候 trailing spaces 是会考虑在内的哦
' stooges' 和 'stooges' 是不同的,sql 只无视 trailing spaces 而已, leading spaces 是在乎的
更新 : 2019-11-17
case sensitive and case insensitive
通常 sql 是不区分大小写的, 比如 where name = 'Abc' 和 where name = 'abc' 是一样的
那么如果我们想区分大小写需要些 collate
-- 查询级别 select * from Products where name = 'abc' COLLATE SQL_Latin1_General_CP1_CS_AS; -- 区分大小写 select * from Products where name = 'abc' COLLATE SQL_Latin1_General_CP1_CI_AS; -- 不区分大小写 -- column 级别 alter table Products alter column name nvarchar(64) collate SQL_Latin1_General_CP1_CS_AS; -- 区分大小写 alter table Products alter column name nvarchar(64) collate SQL_Latin1_General_CP1_CI_AS; -- 不区分大小写
更新: 2019-11-8
查出 table 的 foreign key
SELECT object_name(parent_object_id) as [table], object_name(referenced_object_id) as linkTo, name, is_disabled FROM sys.foreign_keys WHERE parent_object_id = object_id('Items')
把 store procedure 的 data read 进 table
declare @TempTable table ( PK_NAME nvarchar(64) // 需要写全部 column ) insert into @TempTable EXEC sp_fkeys @pktable_name = 'Countries', @pktable_owner = 'dbo'; select * from @TempTable;
留意哦,每一个 column 都要写上。
更新: 2019-09-22
store procedure
go create procedure sp_getMember @inputValue nvarchar(max), @outputValue nvarchar(max) output as set @outputValue = 'www'; go declare @result nvarchar(max); exec sp_getMember @inputValue = 'dada', @outputValue = @result output; print(@result);
留意 input 和 output 的用法.
ef core 的调用
SqlParameter inputParam = new SqlParameter("@inputValue", SqlDbType.NVarChar, 300); inputParam.Direction = ParameterDirection.Input; inputParam.Value = "test"; SqlParameter outputParam = new SqlParameter("@outputValue ", SqlDbType.NVarChar, 300); outputParam.Direction = ParameterDirection.Output; Db.Database.ExecuteSqlCommand("[sp_getMember] @inputValue, @outputValue output", inputParam, outputParam); var returnValue = (string)outputParam.Value;
更新: 2019-08-03
rename table, column, key
use klc2; EXEC sp_rename 'TableSettings', 'UserSettings'; -- rename table EXEC sp_rename 'UserSettings.tableName', 'name', 'COLUMN'; -- rename column EXEC sp_rename 'UserSettings.settingJson', 'json', 'COLUMN'; EXEC sp_rename 'dbo.PK_UserSettingsa', 'PK_UserSettings'; -- rename primary key EXEC sp_rename 'dbo.FK_UserSettings_AspNetUsers_userIa', 'FK_UserSettings_AspNetUsers_userId'; -- rename foreign key SELECT name, SCHEMA_NAME(schema_id) AS schema_name, type_desc FROM sys.objects WHERE parent_object_id = (OBJECT_ID('UserSettings')) AND type IN ('C','F', 'PK');
更新 : 2019-06-01
modify json
refer :
https://docs.microsoft.com/en-us/sql/t-sql/functions/json-modify-transact-sql?view=sql-server-2017
update klc2.dbo.Questions set audio = JSON_MODIFY(audio, '$.type', 'Audio');
mutiple JSON_MODIFY(JSON_MODIFY() ...) 做法是嵌套...
读取 array
declare @json nvarchar(max) = N'{"monday":[],"tuesday":[14,15,16,17,18,19,20,21],"wednesday":[12,13,14,15,16,17,18,19,20,21],"thursday":[14,15,16,17,18,19,20,21],"friday":[10,11,12,13,14,15,16,17,18,19,20,21],"saturday":[9,10,11,12,13,14,15,16,17,18,19,20],"sunday":[]}'; select * into #dailyHour from openjson(@json); while (select count(*) from #dailyHour) > 0 begin declare @dayOfWeek nvarchar(max); declare @hours nvarchar(max); declare @startHour int; declare @endHour int; select top 1 @dayOfWeek = [key], @hours = value from #dailyHour; select top 1 @startHour = value from openjson(@hours) order by [key]; select top 1 @endHour = value from openjson(@hours) order by cast([key] as int) desc; -- 要 cast 哦 if(@hours != '[]') begin print(@dayOfWeek); print(@startHour); print(@endHour); end delete from #dailyHour where [key] = @dayOfWeek; end drop table #dailyHour;
orderby date nulls first
sql server 不支持 null first or last 的 语法, 需要用 case 来完成
entity 的写法是
orderby(n => n.time == null)
生成出来的语句大概是 CASE WHEN ([Extent1].[time] IS NULL) THEN cast(1 as bit) ELSE cast(0 as bit) END AS [C1],
原理就是在 order by 的时候动态创建一个 boolean column 先 orderby 它.
可惜 odata 并不支持这个方法, 可以用 compute column 来解决.
ALTER TABLE [dbo].[CalendarEvents] ADD haveTime AS CASE WHEN (time IS NULL) THEN cast(0 as bit) ELSE cast(1 as bit) END PERSISTED;
调用是 $orderby : "date, haveTime desc, time"
nvarchar(MAX) vs ntext
不要用 ntext 了, nvarchar(N) N 必须小于 4000, 如果 charater 有可能大于 4000 就放 MAX
max 的话 sql 会用类似 text 的方式去处理的.
index 需要 column 小于 900 bytes, nvachar 就是 450 字就 max 了. vachar 就 900咯.
Compute column
不能子表哦
PERSISTED 的话会在 insert, update 时同步 属于 reccalc on change 模式
没有PERSISTED 则属于 getter 模式
ALTER TABLE [dbo].[Exams] ADD mark AS (CAST(totalCorrectAnswer AS FLOAT) / totalQuestion * 100) PERSISTED;
sql transaction isolation level
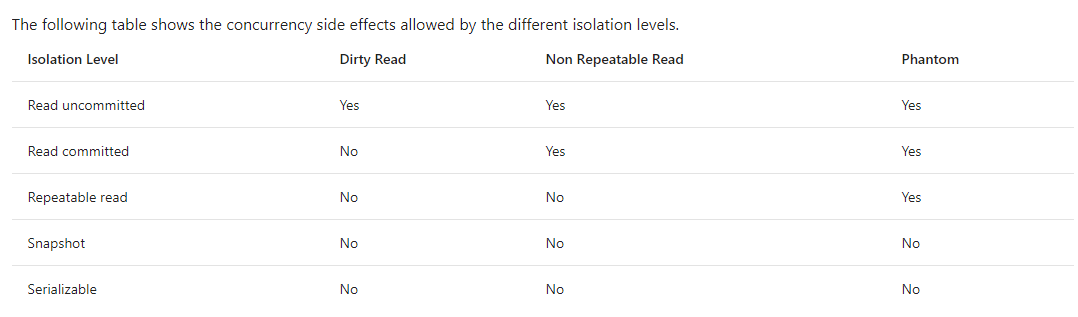
脏读,重复读,幻读
default is read commited, 防止脏读, 意思是 transaction update row 时, 这个 row 是不允许读的,transaction 写时会锁
通常做 update,post,delete 时如果依赖其它数据, 我们就会选择使用更高级别的 Repeatable read
意思是我重复读一条依赖的数据, 它在 transaction 的过程中永远是同一个值, transaction 读时会锁.
不过呢 Repeatable read 只是锁 row, 如果你依赖 row count 那么可能你需要锁更大的范围, 那么就是 Serializable 了
锁越大就越容易出现死锁,写入的效率也慢, 所以小心使用.
2019-06-18 补上细节
set transaction isolation level repeatable read; set transaction isolation level serializable; begin transaction tran1 select * from test where name = '55'; commit
什么时候应该使用 repeat 或 serial 呢
就是当我们依赖一些数据作为验证的时候,比如你从数据库拿一个值来判断用户是否可以 insert 资料, 结果就在你检查的瞬间
数据被修改了,这就会导致你的判断错误,除了判断还有可能我们依赖数据来做计算,这样就可能会算错了.
所以这时候就可以使用 repeat read 这样就可以确保我们在执行完事情的时候,当下是正确的计算。
需要注意的是 repeat read 只是锁了一行. 没有人可以对那个 row 进行更新,但是这不代表你的数据不会被影响.
比如
select name from table where name = 'abc';
这是返回了 3 个数据. 你使用这 3 个数据做东西.
没有人可以修改这 3 个数据... 但是呢, 你的 where 却不安全.
如果其他人 insert ... (name) values ('abc') .. 你的算法又错了.
或者 update set name = 'abc' where id ...
所以如果你的 where 是 unique 的话就没事儿, 如果不是的话就要小心了
这时候要安全的话就要使用 serial
它可以阻止 insert 和 update ..
serial 要小心的用, where 的 column 最好是放上 index (如果 index 被使用的话它可以减小锁的范围)
比如
select name from table where name = 'abc';
拿到一行, id = 1, name = abc
如果 name 不是 index 的话, 那么整个表就锁掉了
update table set age = 11 where Id = 5
这句完全没有影响到你的 update 也无法 run ..
所以要加上 index 给 name
那么 sql 会变聪明, 上面那个 update 是可以运行的. 估计是通过 index 来判断. (前提是 select + where 有用到 index 啦, 如果它用的 index 不对, 或者它认为全表更快, 那么也是会造成锁的范围变大的, 所以还是小心用)
死锁是这样发生的
a 锁表 table1
b 锁表 table1
a update 表 table1, 被 b 锁了, 等待
b update 表 table1 , 也被 a 锁了, 等待...
这样就锁死了 .
一旦死算, 第一个 update 的人赢.. 后面的就 error,这样就解锁了. sql 发现死锁是蛮快的.
总结就是 :
如果依赖数据来做计算, 验证等,那么就需要锁.
如果 where 的条件是 unique 比如 where id =.. where email =...
那么用 repeat read 就很安全了
如果不是..unique 那么尽量加上 index 在 where 的 column 让 sql 聪明一点.
这篇写的很完整,可以看看
https://www.cnblogs.com/edisonchou/p/6129717.html
check trans open
SELECT * FROM sys.sysprocesses WHERE open_tran = 1
unique with filter null
CREATE UNIQUE NONCLUSTERED INDEX[UNIQUE_Characters_Teacher_contactEmail] ON[dbo].[Characters]([Teacher_contactEmail] ASC) WHERE([Teacher_contactEmail] IS NOT NULL);
foreign relation cascade delete or set null
ALTER TABLE [dbo].[ExamDatas] DROP CONSTRAINT [FK_dbo.ExamDatas_dbo.Questions_questionId]; ALTER TABLE [dbo].[ExamDatas] WITH CHECK ADD CONSTRAINT [FK_dbo.ExamDatas_dbo.Questions_questionId] FOREIGN KEY([questionId]) REFERENCES [dbo].[Questions] ([Id]) ON DELETE SET NULL;
-- ON DELETE CASCADE;
check connection
exec sp_who exec sp_who2
Or
SELECT
DB_NAME(dbid) as DBName,
COUNT(dbid) as NumberOfConnections,
loginame as LoginName
FROM
sys.sysprocesses
WHERE
dbid > 0
GROUP BY
dbid, loginame
;reset auto increment
DBCC checkident ('Employees') //check currentDBCC checkident ('Employees', reseed, 0); //reset to 0 , next is 1Function
从例子学习
drop function dbo.getWorkingDateCount; --getWorkingDateCount = functionName CREATE FUNCTION [dbo].[getWorkingDateCount] ( --这3个是parameter, 名字和类型 @fromDate date, @toDate date, @publicHolidayStrList nvarchar(500) ) RETURNS int --表明返回类型 AS BEGIN DECLARE @count INT = 0; --DECLARE 就是var WHILE @fromDate <= @toDate --while 就是for loop BEGIN DECLARE @ipos INT = 0; DECLARE @dateName nvarchar(50); --赋值一定要写set在前面, --CHARINDEX 是 indexOf --CONVERT 是 datetime to string , 126 是一个sql对日期格式的代号 refer : https://msdn.microsoft.com/en-us/library/ms187928.aspx SET @ipos = CHARINDEX(CONVERT(VARCHAR(10),@fromDate,126), @publicHolidayStrList); --DATENAME weekday 返回星期几 SET @dateName = DATENAME(weekday, @fromDate); IF @ipos = 0 and @dateName != 'Saturday' and @dateName !='Sunday' BEGIN SET @count = @count + 1; END SET @fromDate = DATEADD(day,1,@fromDate) --DATEADD = datetime.addDays() END; RETURN @count; END select dbo.getWorkingDateCount('2015-11-01','2015-11-30','2015-11-07,2015-11-13') as 'date';
上面是一个调用来获取工作天数的函数
update 和 insert 顾虑并发
insert into DemoProducts (code) select top 1 'mk100' from DemoColors where DemoColors.ID = 5 and DemoColors.rowVersion = 'xxfx01tAA'; UPDATE p SET p.code = 'mk200' FROM DemoProducts p,DemoColors c WHERE p.ID = 5 and c.ID = 5 and c.rowVersion = '';
insert 之后拿 ID
INSERT [dbo].[DemoProducts]([code]) select 'x' from DemoColors SELECT [ID] FROM [dbo].[DemoProducts] WHERE @@ROWCOUNT > 0 AND [ID] = scope_identity()
用 output 会更好,不止insert,update,delete也通用哦
INSERT DemoProducts (code) OUTPUT inserted.code as ttc,inserted.ID select 'newCode' from DemoProducts;
refer: https://msdn.microsoft.com/en-us/library/ms177564.aspx
Transaction 逻辑
当一个transaction开始后,如果有修改sql, 那么被修改的那一行row会被锁上,其它请求 get,set 涉及到那一行row都会阻塞,直到 tran 结束.
查看 database 目前有的 trigger, function, stored procedure 等
SELECT DB_NAME() AS DataBaseName, dbo.SysObjects.Name AS TriggerName, dbo.sysComments.Text AS SqlContent FROM dbo.SysObjects INNER JOIN dbo.sysComments ON dbo.SysObjects.ID = dbo.sysComments.ID;