前言
很久以前有学习过各种树结构, 但后来真的没有在实际项目中运用到. 毕竟我主要负责的都是写业务代码. 太上层了
但是忘光光还是很可惜的. 所以久久可以复习一下. 记得概念也好, 帮助思考.
参考:
mysql底层原理-二叉树、红黑树、BTree、B+Tree
二叉树

规则是左边要比右边小. 它最大的问题就是会很深, 像上面这样. 每多一层就 IO 读写多一次, 就慢 (因为读 IO 是物理操作, 要移动磁头, 这个和读 ram 通通电, 不同级别). 所以它不可以用来做 database 数据结构.
红黑树
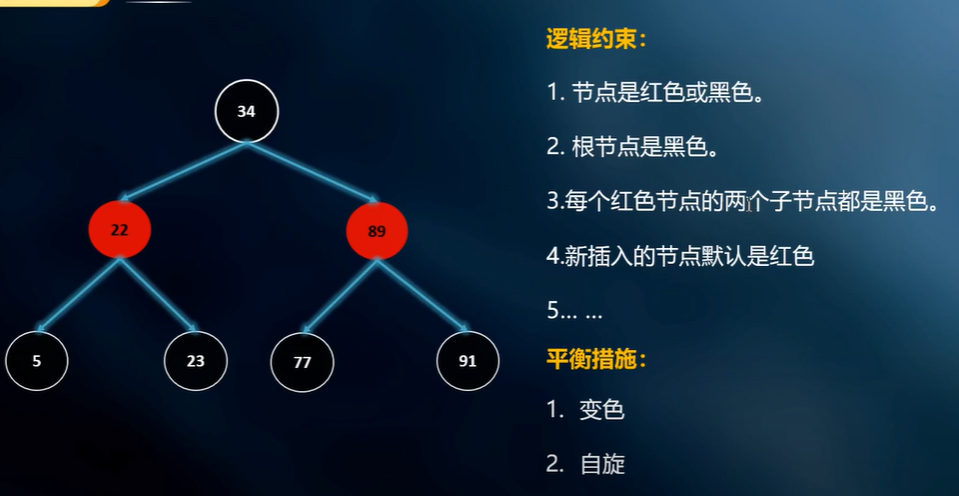
红黑是二叉的查询优化, 所有查询优化都是建立在提前对数据结构处理的. 所以 insert, update, delete 一定会变慢.
红黑树多了一些规则, 确保树没有那么深 (做了一些平衡), 每当新节点插入的时候, 树结构就有可能因为要满足条件而调整.
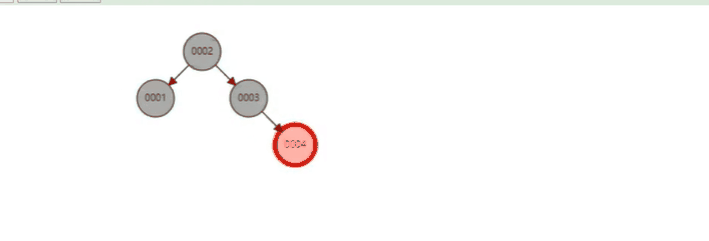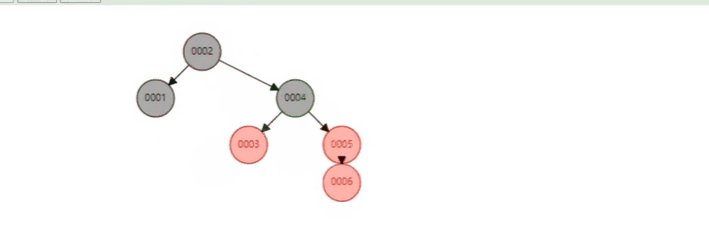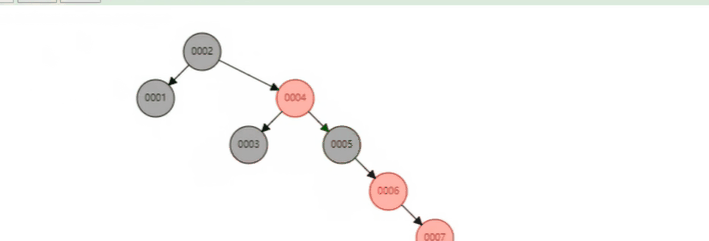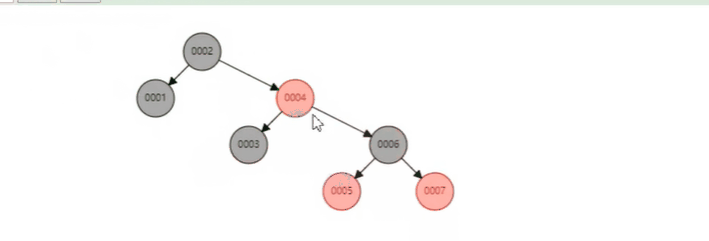
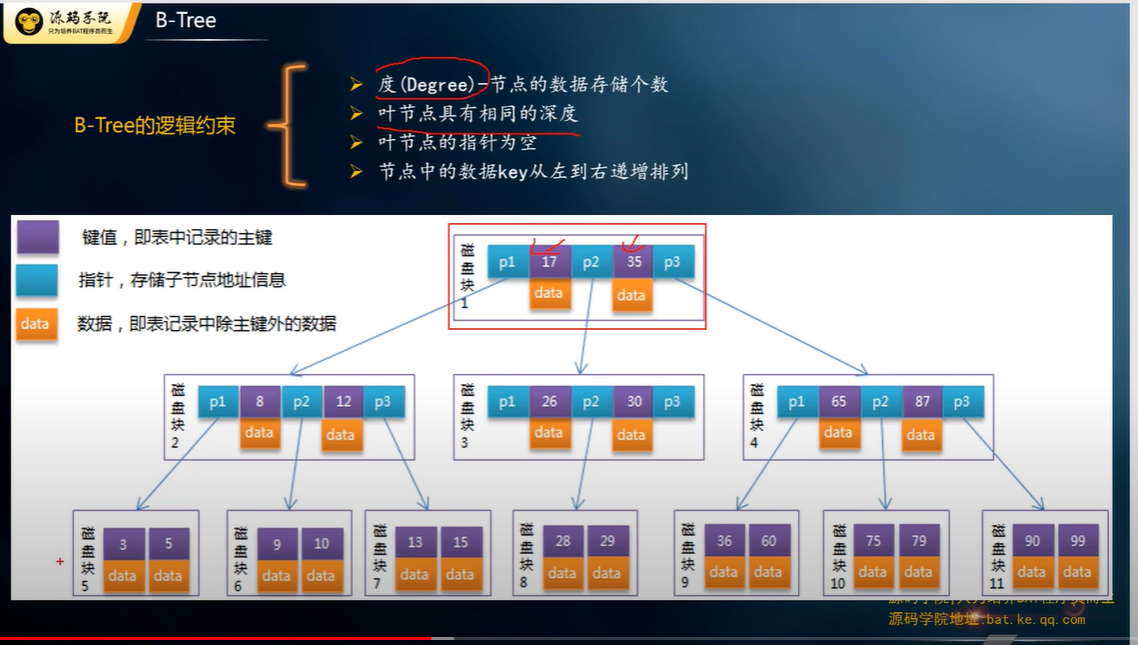
B 树
B 树又对红黑进行了优化, 它利用了磁盘预读原理, 加大了树的宽度 (MySQL 16kb, SQL Server 8kb per page), 减少了树的高度. 树低了, IO 就少了, 性能就快了.
磁盘每一次读多少是不确定的, 因为系统会缓存, 可能把几次读操作合并一起做, 参考: 磁盘读写与数据库的关系
预读是因为局部性原理, 通常当你需要一个资料, 它附近的资料你也会想要用到. 而且顺着读性能不大, 所以就顺便预读出来了.
B+ 树
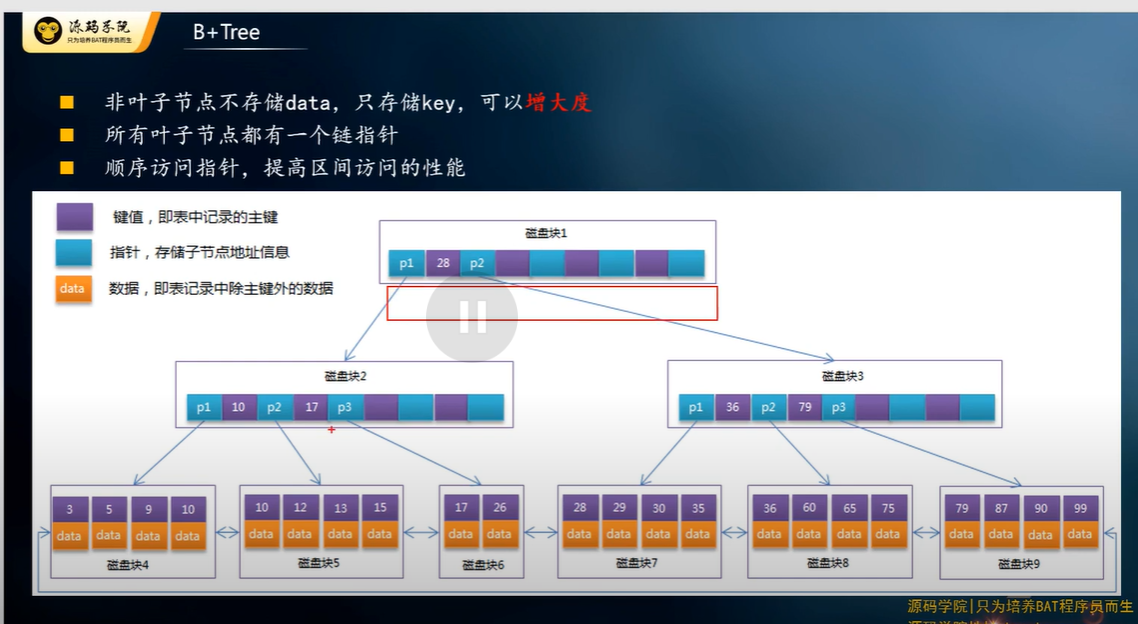
对 B 树做了优化, data size 太大, 会导致磁盘块太大, 所以把 data 都移到了最底部, 所以先查找关键字, 最终才去拿资料. 这也说明为什么索引只能 450 字.
结论
数据库的设计和找字典是一样概念, 上面这些磁盘块, 就好比字典的目录,
比如我找 Derrick 这个字, 一页一页翻肯定很慢, 但是有一个 A-Z 的目录, 里面就 26 个字母.
先把目录读出来, 然后 loop 到 D, 那么就锁定 D 的范围了. 过滤了大部分不相关的字.
所谓的 index 就是目录. 依据不同 column 排序.
p.s 红黑, B 树 抽象都是平衡二叉树, 目的都为了平衡, B-树就是B树来的. 只是因为有一个B+树所以就把原来的叫B-树.