index :通过有序索引顺序扫描直接返回有序数据,不需要额外的排序,操作效率较高。
filesort:通过对返回数据进行排序,filesort 并不代表通过磁盘文件排序,而是说明进行了一个排序操作,至于排序操作是否使用了磁盘文件或临时表等,则取决于MySQL服务器对排序参数的设置和需要排序数据的大小。
一般而言,filesort是通过相应的排序算法,将所取得的数据在sort_buffer_size系统变量设置的内存排序区中进行排序,如果内存装载不下,它就会将磁盘上的数据进行分块,再对各个数据块进行排序,然后将各个块合并成有序的结果集。
sort_buffer_size设置的排序区是每个线程独占的,所以同一时刻,MySQL中存在多个sort buffer排序区。
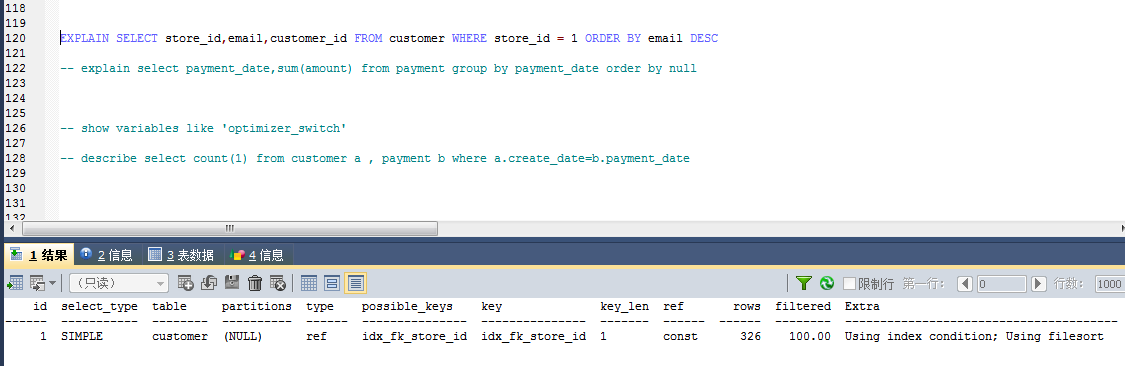
优化:尽量减少额外排序,通过索引直接返回有序的数据。where 条件和order by 使用了相同的索引,并且order by 的顺序和索引顺序相同,并且order by 的字段都是升序或者降序,否则肯定需要额外的排序操作,这样就会出现 filesort。
以下SQL可以使用索引:
select * from tablename order by key_part1,key_part2,....;
select * from tablename where key_part1=1 order by key_part1 desc,key_part2 desc;
select * from tablename order by key_part1 desc,key_part2 desc;
以下SQL不可以使用索引:
select * from tablename order by key_part1 desc,key_part2 asc; ----order by 的字段混合asc,desc
select * from tablename where key2=constant order by key1; ----用于查询的关键字与order by 中所使用的不相同
select * from tablename order by key1,key2; ----对不同的关键字使用order by
对于Filesort,MySQL有两种排序算法 :
一次扫描算法和两次扫描算法,通过比较系统变量max_length_for_sort_data的大小和query语句总字段的大小来判断使用哪种排序算法。
适当增加 max_length_for_sort_data的值,适当增加sort_buffer_size排序区,尽量使用具体的字段而不是select * 选择所有字段。
在CPU和IO之间平衡。